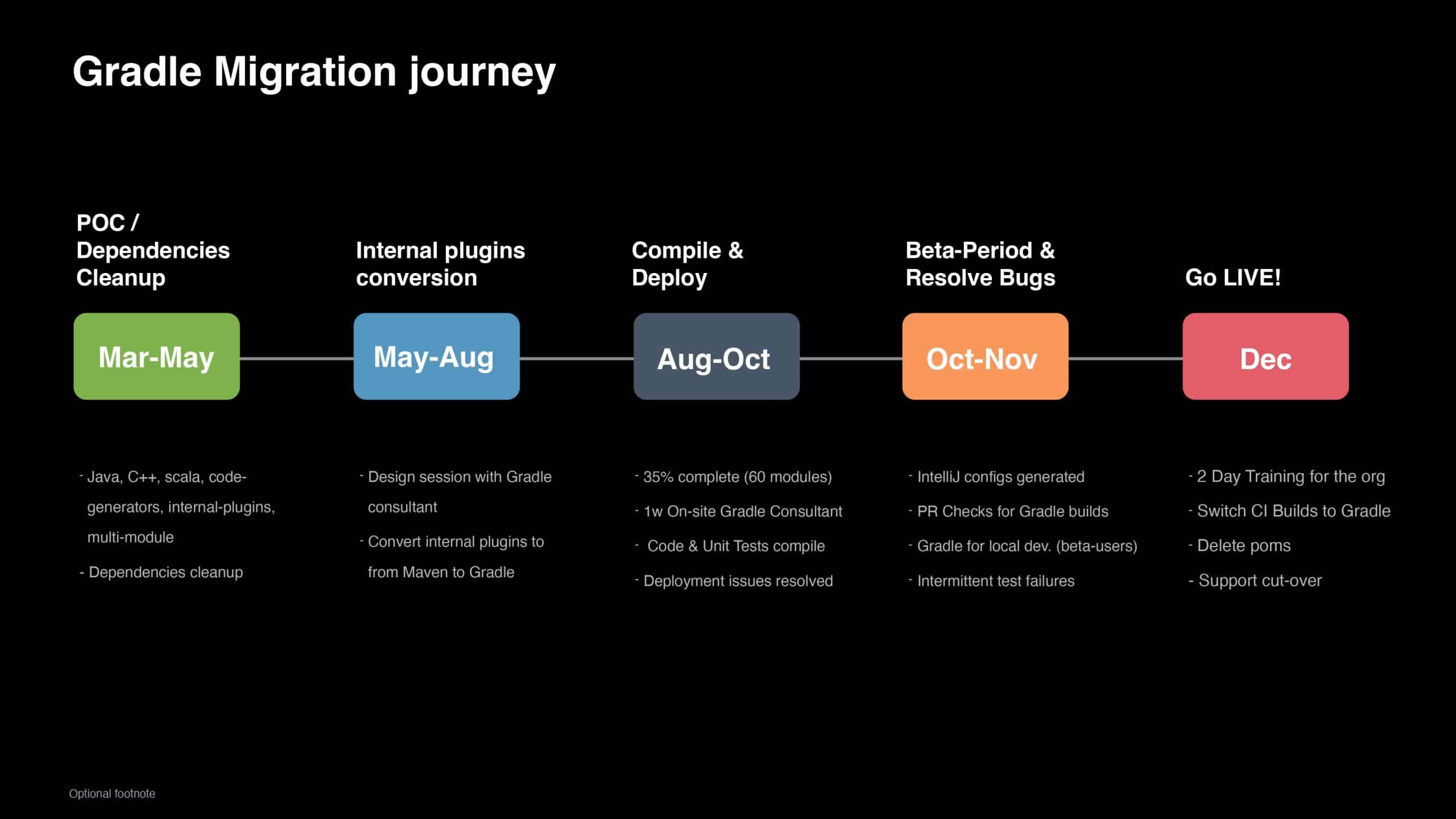
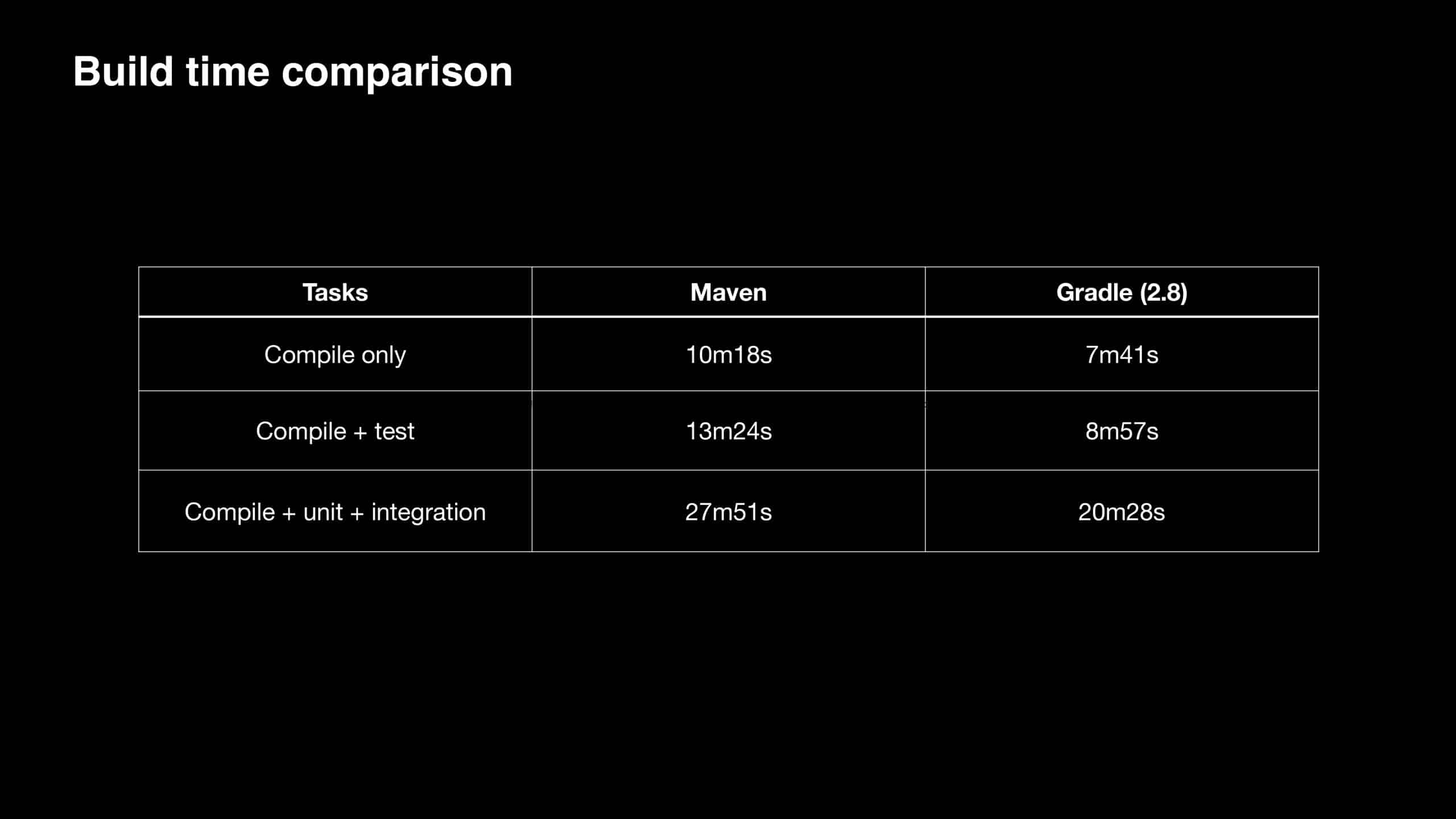
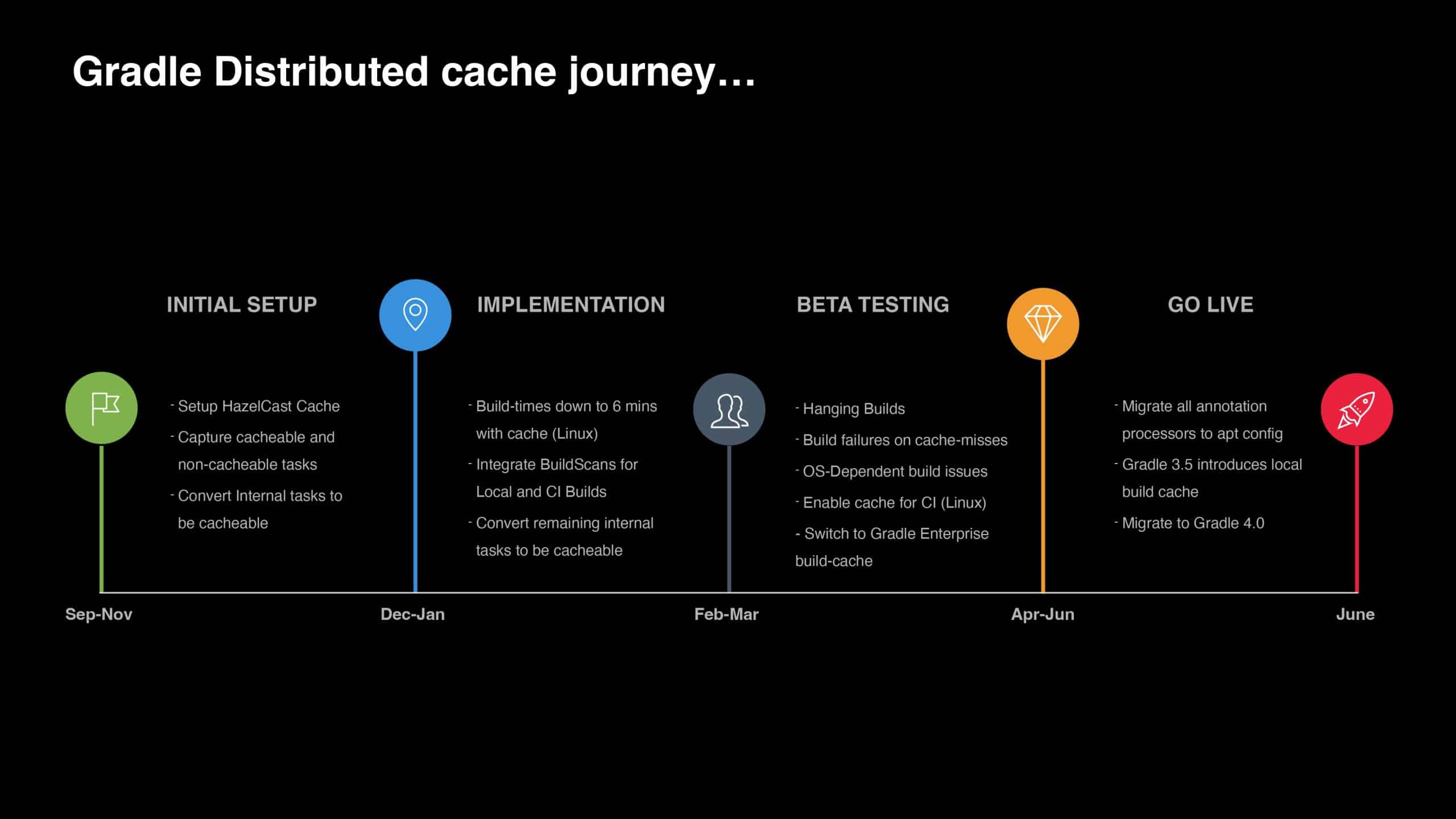
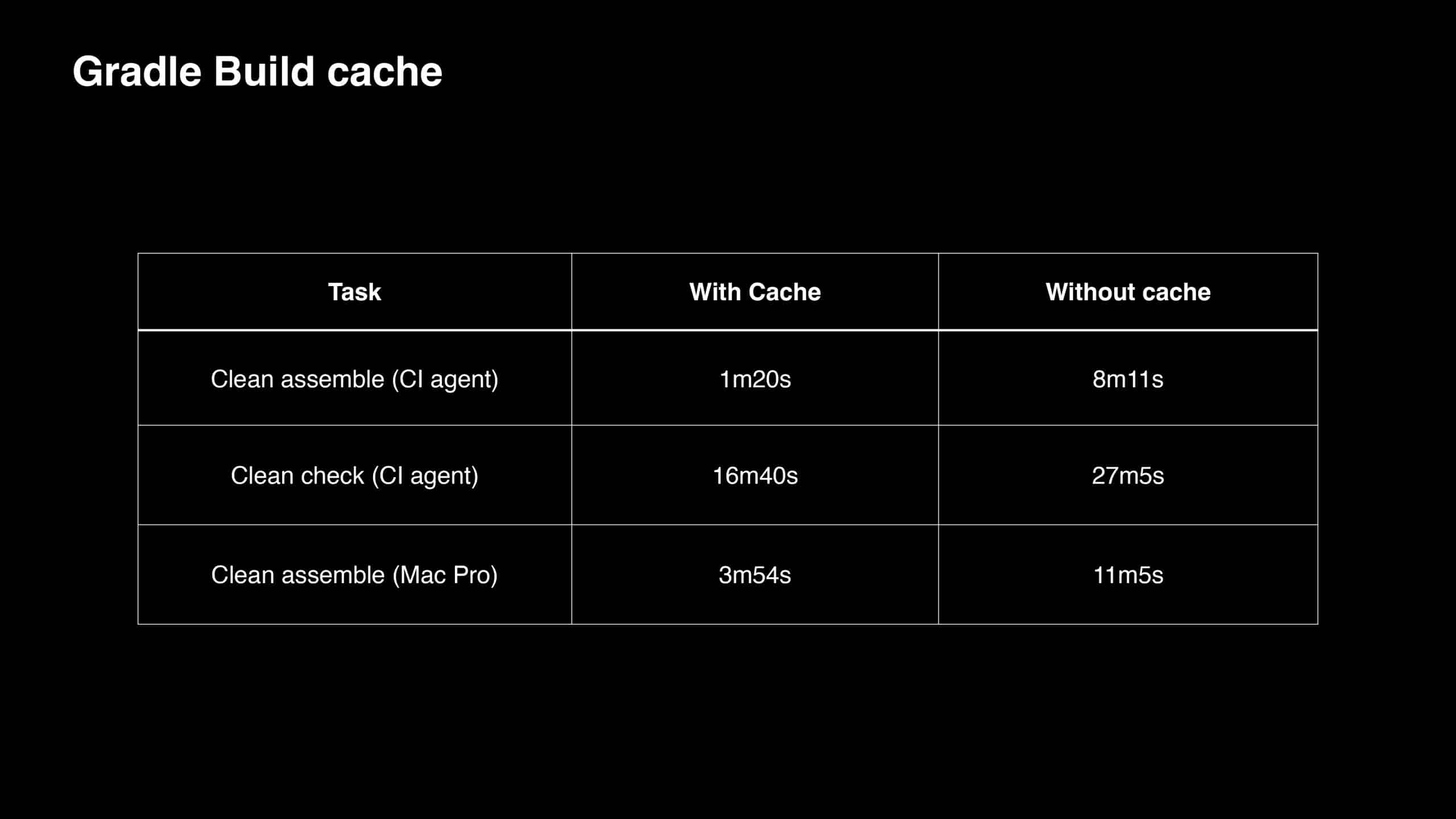
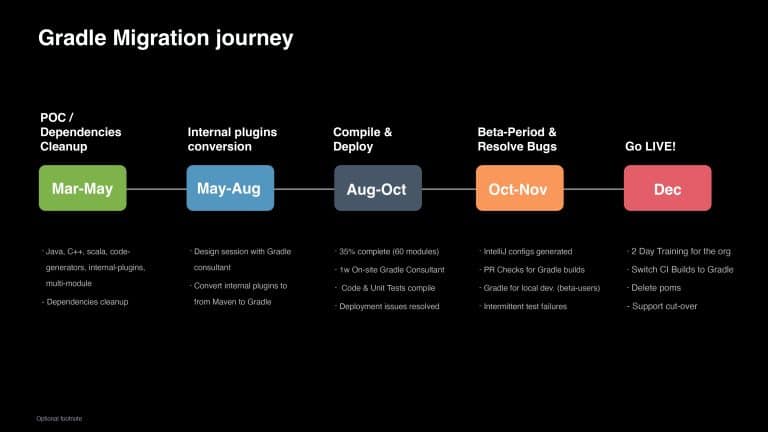
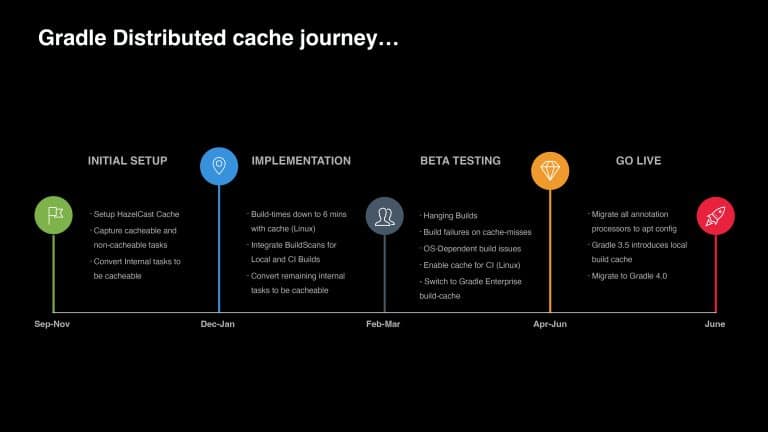
With over 350 engineers continuously developing Apple Siri, the slow Maven build times (up to 30 minutes) could no longer be ignored. This talk traces the transformations of the Siri build that started with the migration from Maven to the Gradle Build Tool. It then covers the approaches taken to not only improve the Apple developer experience but also significantly increase feedback-loop velocity, address common pain points, and identify the right KPIs for evaluating developer productivity across the team.
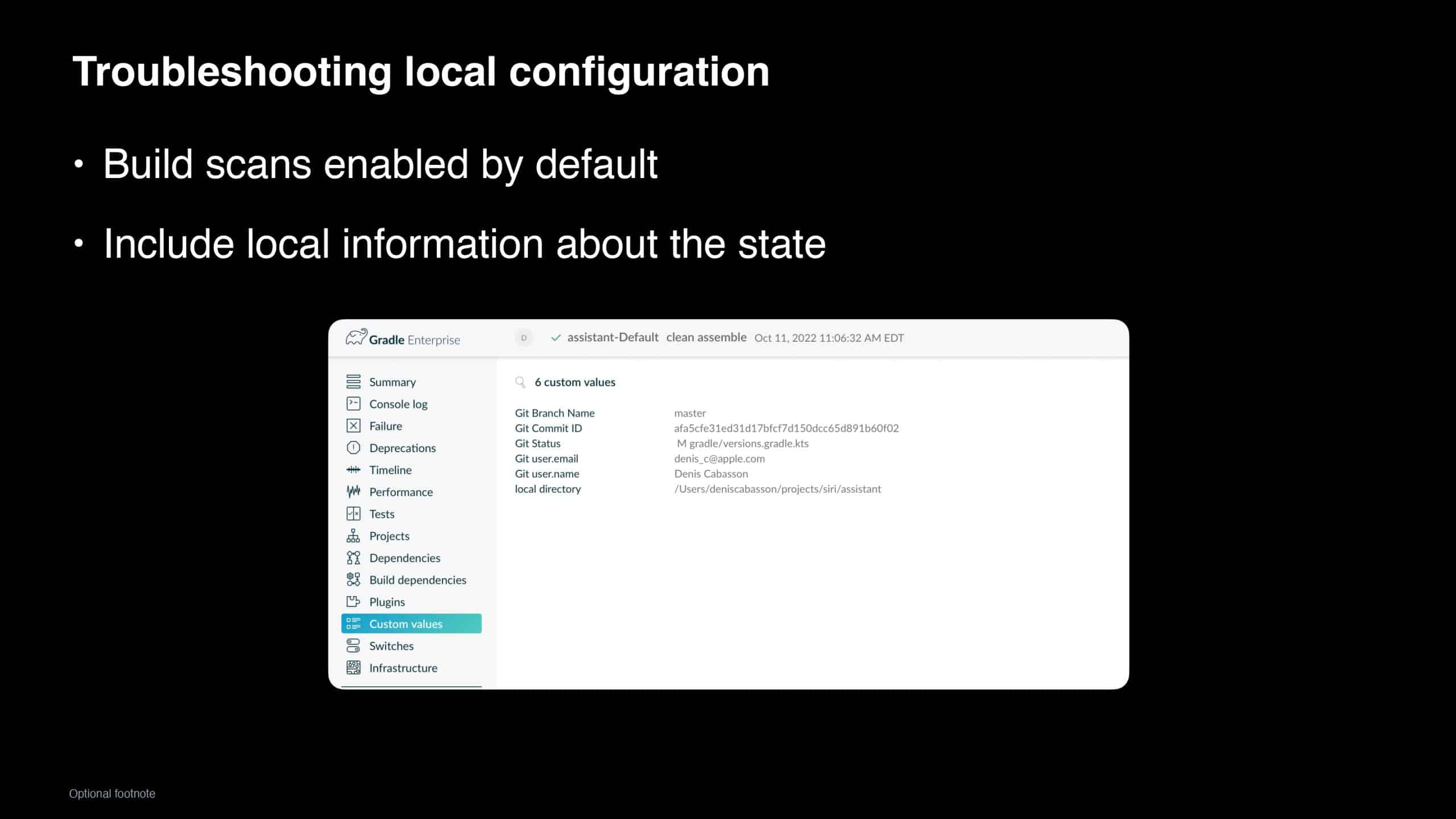
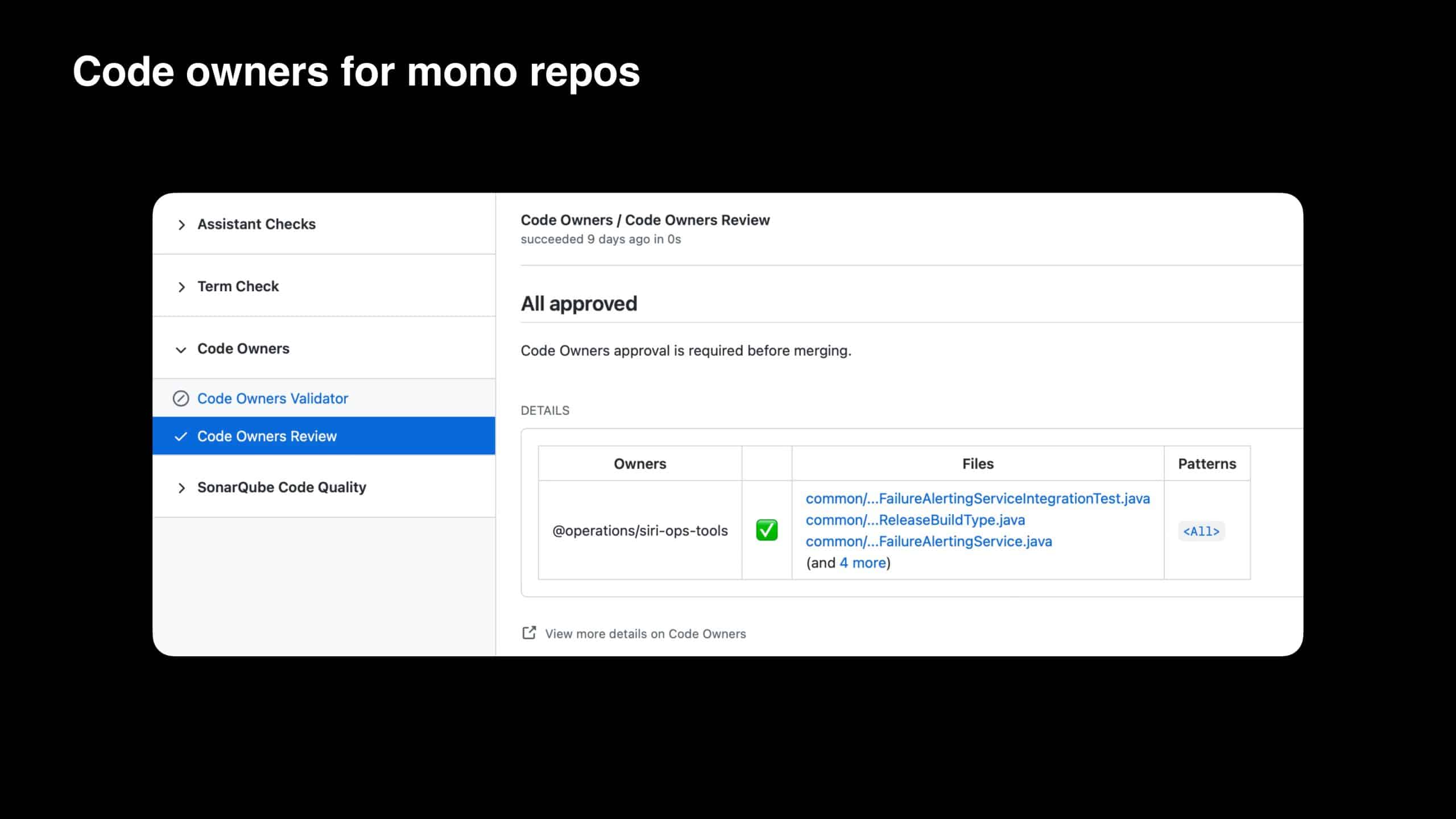
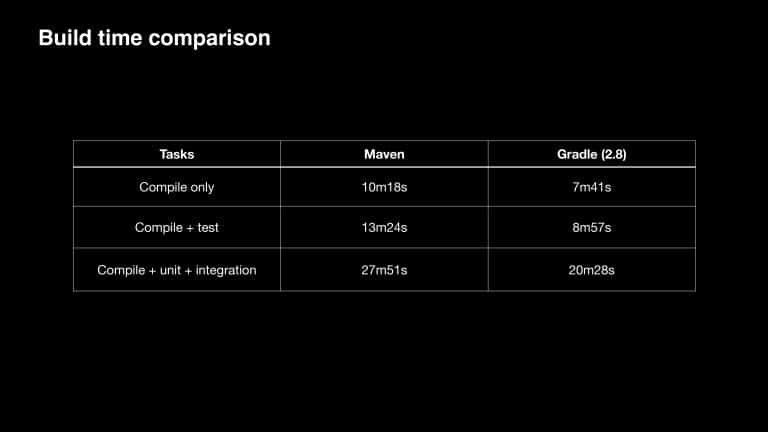
“Hey Siri…” are words spoken by millions of people each day. To keep Siri scalable and meet growing demand, the team at Apple is always looking for areas to optimize the developer experience. In this presentation, you will learn how Apple achieved a 35-75% drop in build times by migrating from Maven to Gradle. You will also learn how Apple leveraged Build Cache, Build Scan™, and other Gradle Enterprise features to address developer pain points, such as 20+ minute Maven builds, and troubleshoot local config challenges, saving a remarkable 16,500 developer hours per year.
Ankit Srivastava is a software engineer based in San Francisco, working at Apple. He has a background in solving challenging problems associated with development environment frameworks, CI/CD, scalability, and software build systems. His goal is to enable engineers to deliver products at high velocity and scale without compromising quality. Ankit’s passions include Buckeyes football, hiking, photography, and good beer.
Denis Cabasson is a DevOps engineering manager with a strong focus on automation and streamlining the user experience as it relates to CI/CD processes and build topics. Based in Ottawa, Canada, Denis enjoys playing board games with friends and family, as well as soccer and badminton.

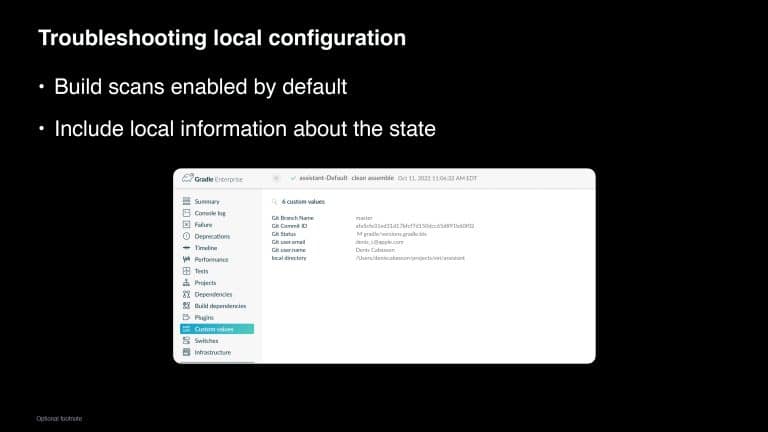
Gradle Enterprise customers use the Gradle Enterprise Build Scan, Performance, and Trends dashboards to identify and monitor performance bottlenecks in the build/test process, including build cache misses, code generation, and annotation processors. You can learn more about these features by running your own free Build Scan™ for Maven and Gradle Build Tool, as well as in our free instructor-led Build Cache deep-dive training.