What’s inside?
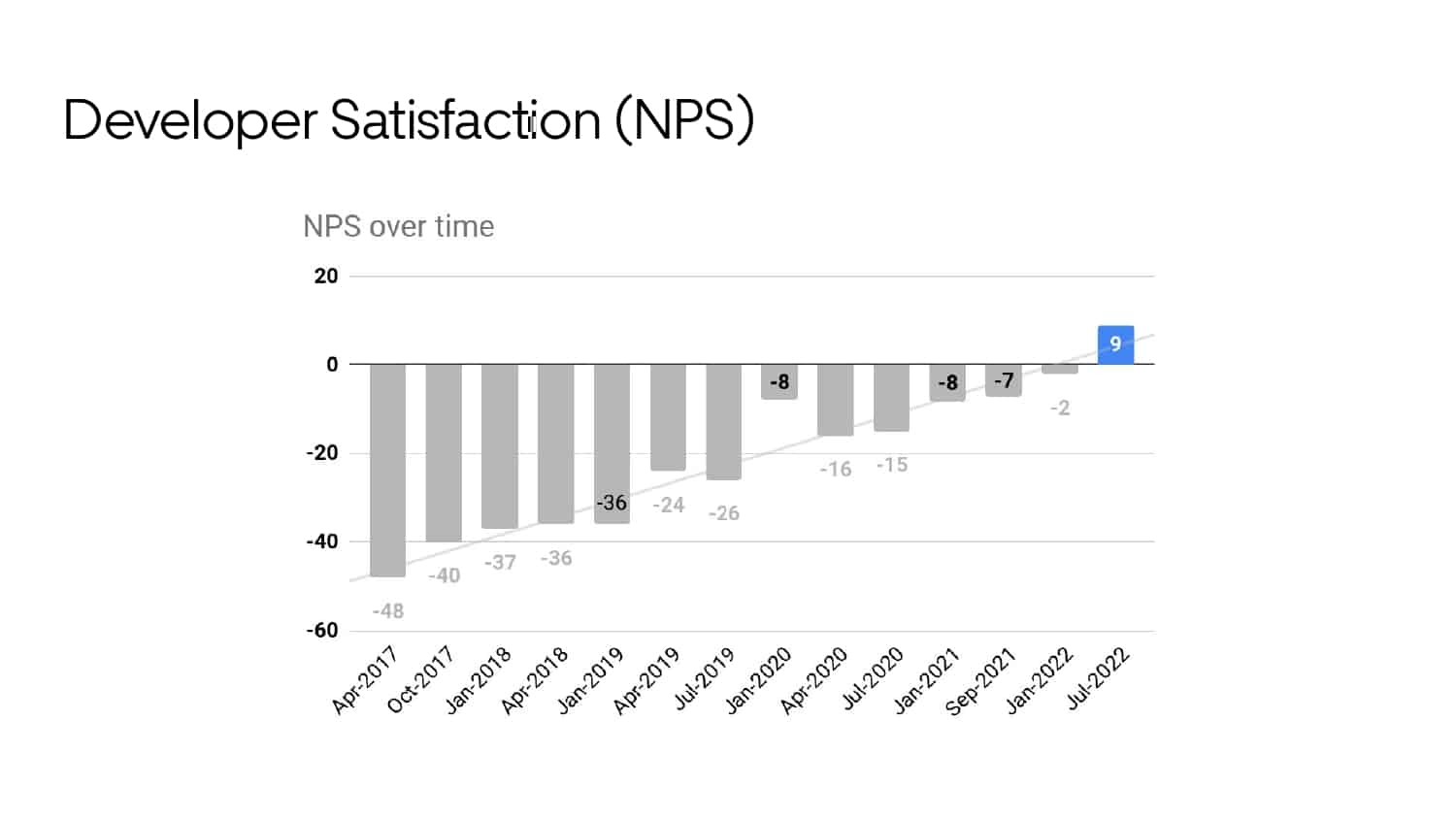
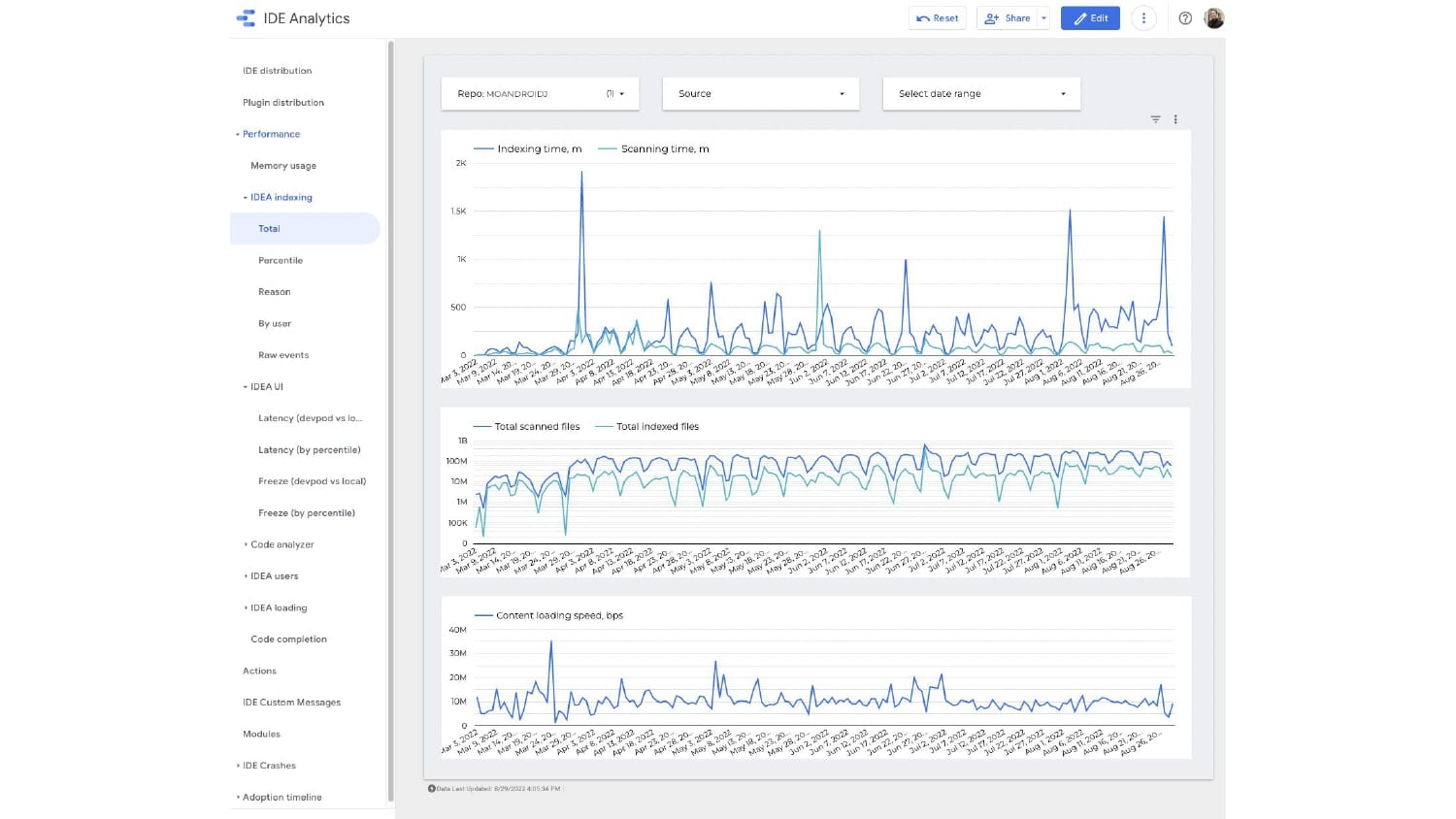
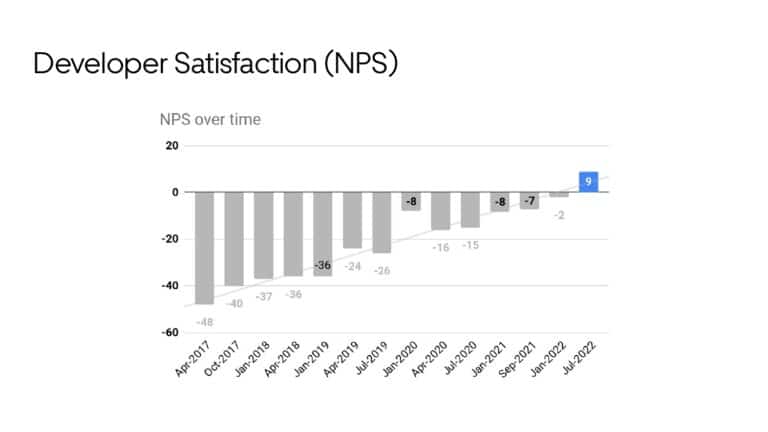
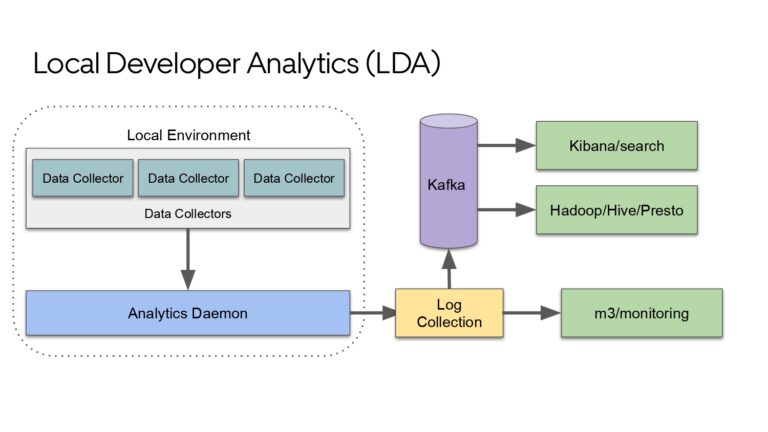
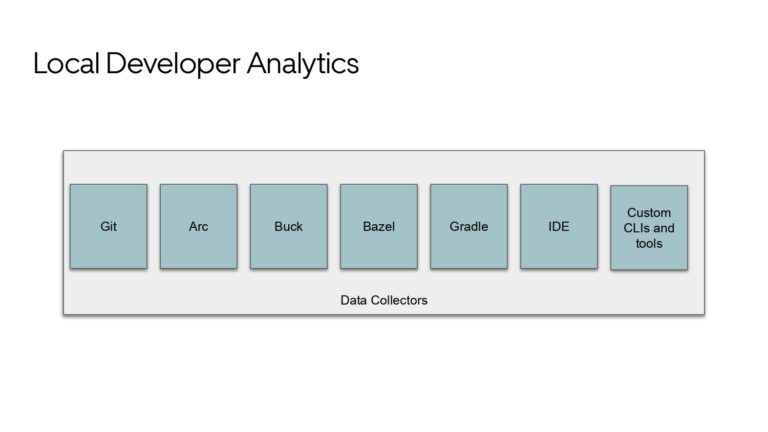
Ty Smith will share the key metrics that productivity engineers at Uber capture and utilize to optimize Developer Experience. He shares one of their biggest DPE initiative’s wins that you will not want to miss learning more about.
Ty Smith will share the key metrics that productivity engineers at Uber capture and utilize to optimize Developer Experience. He shares one of their biggest DPE initiative’s wins that you will not want to miss learning more about.
Summit Producer’s Highlight
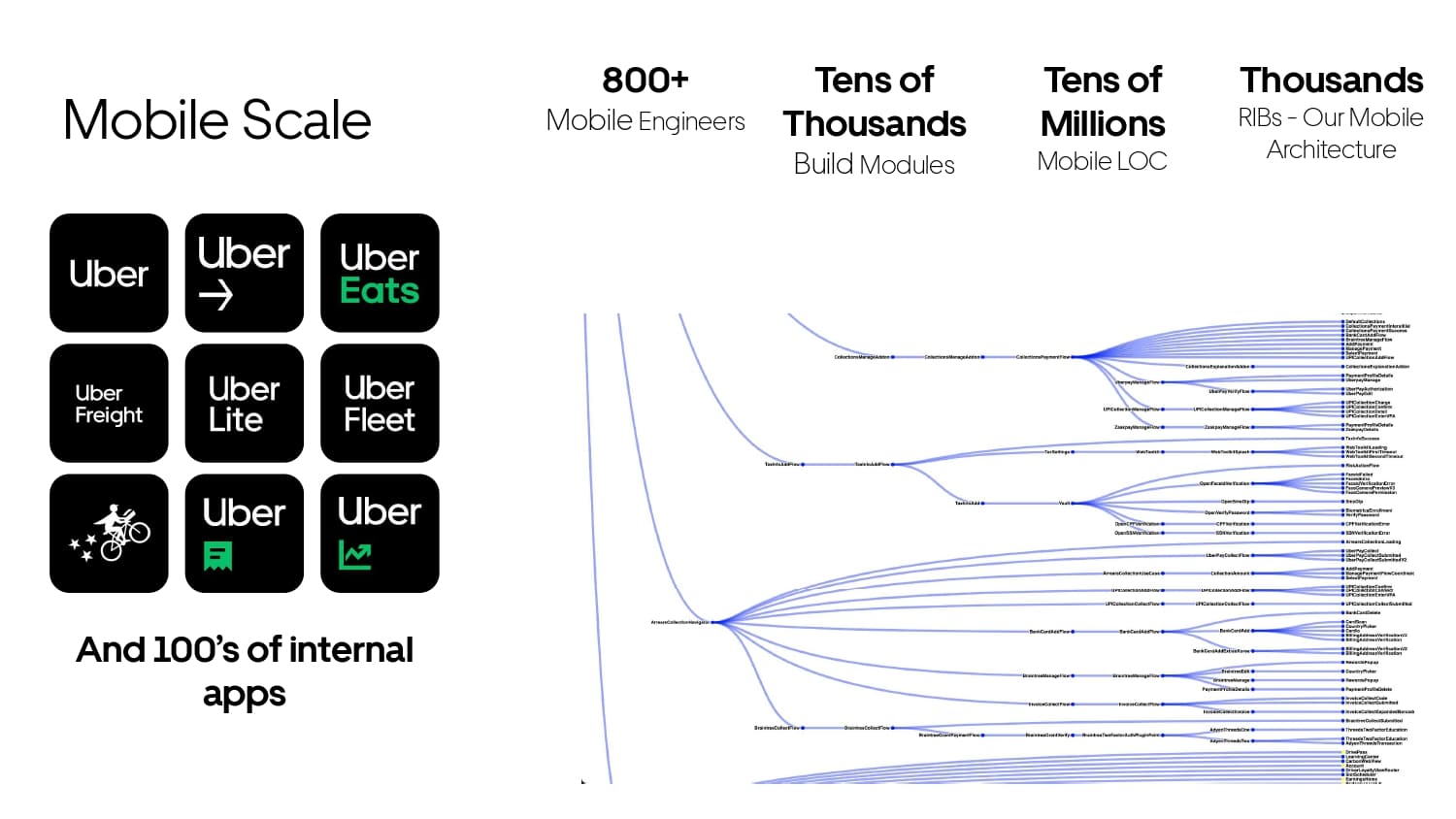
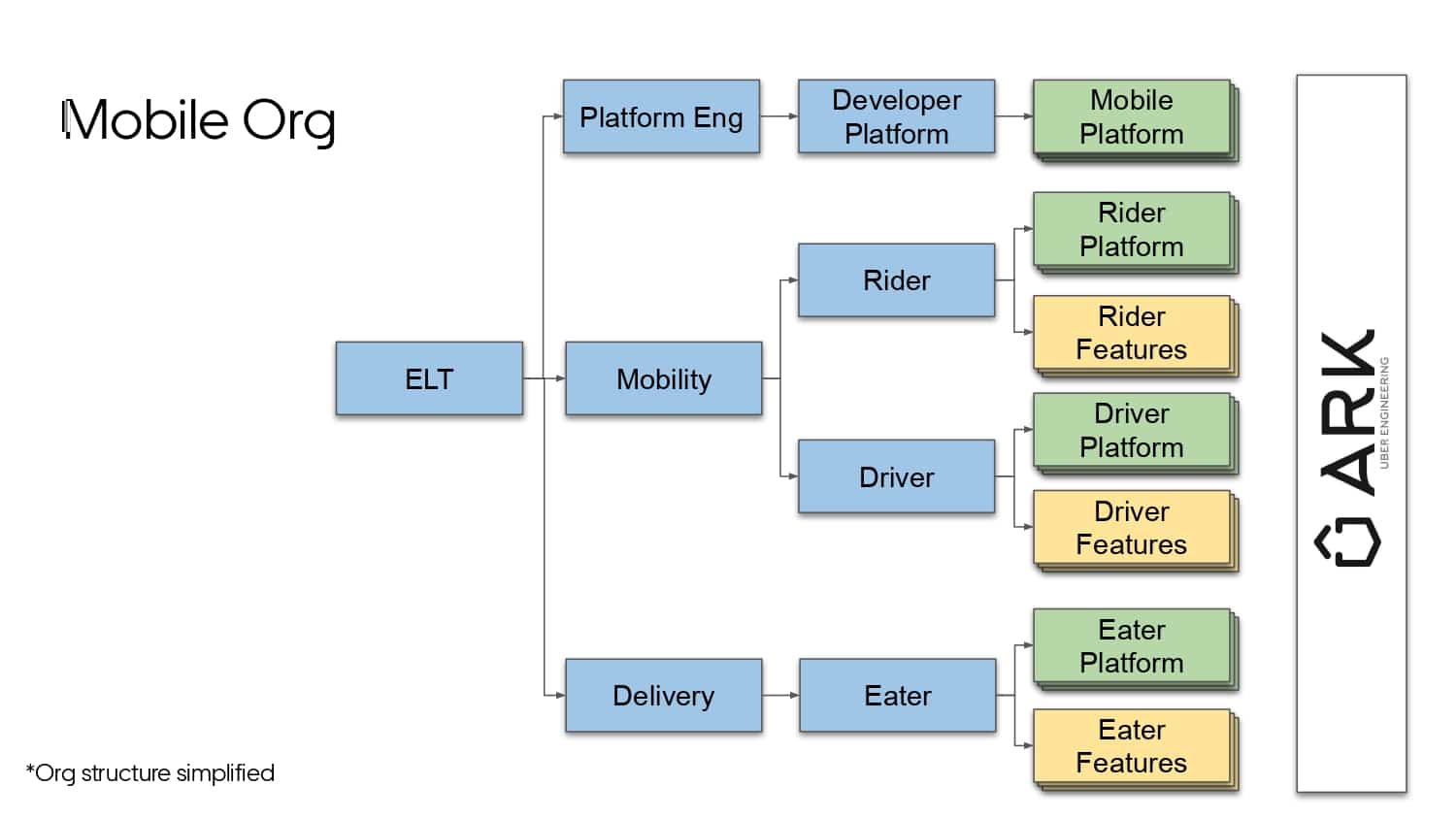
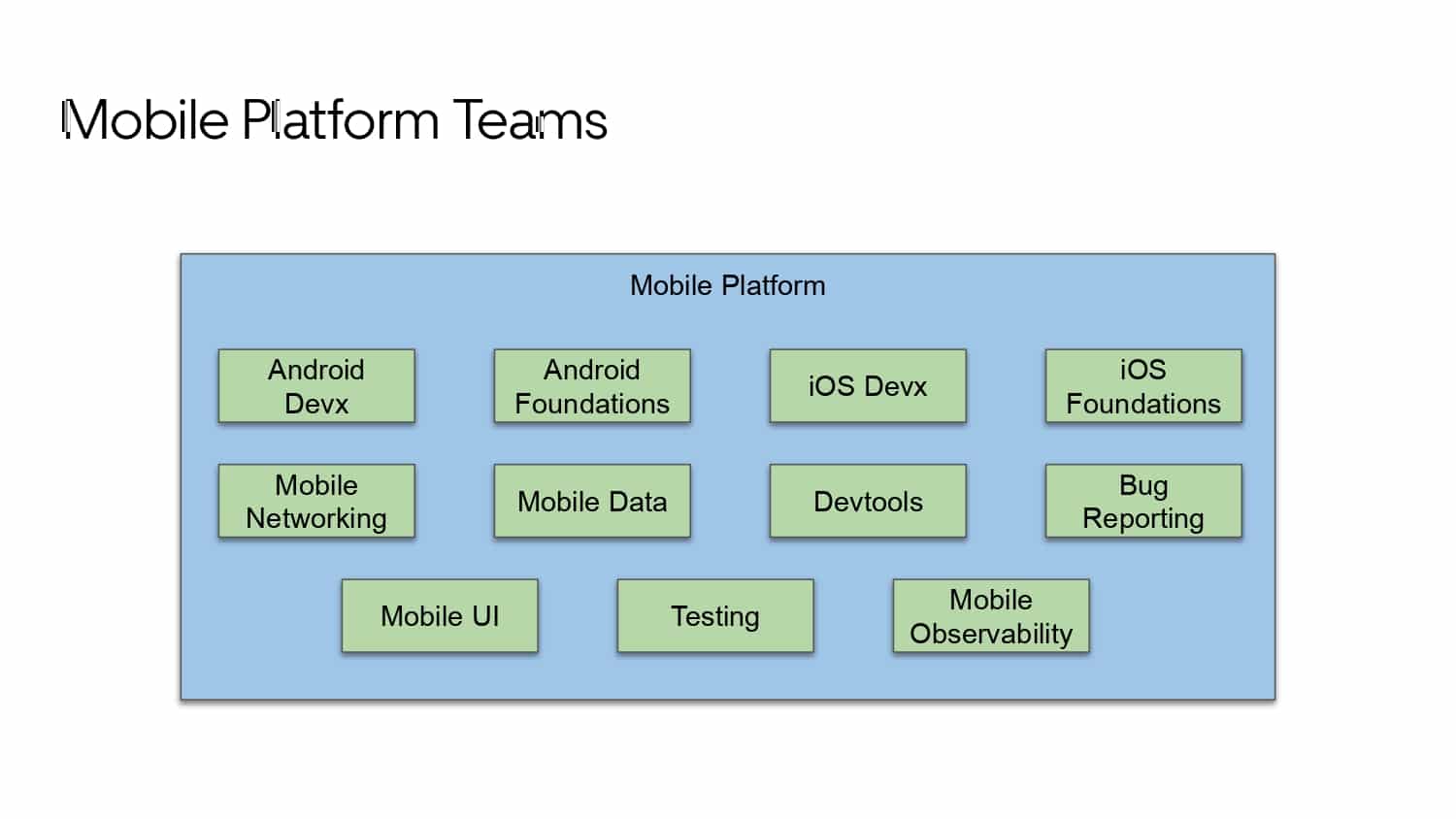
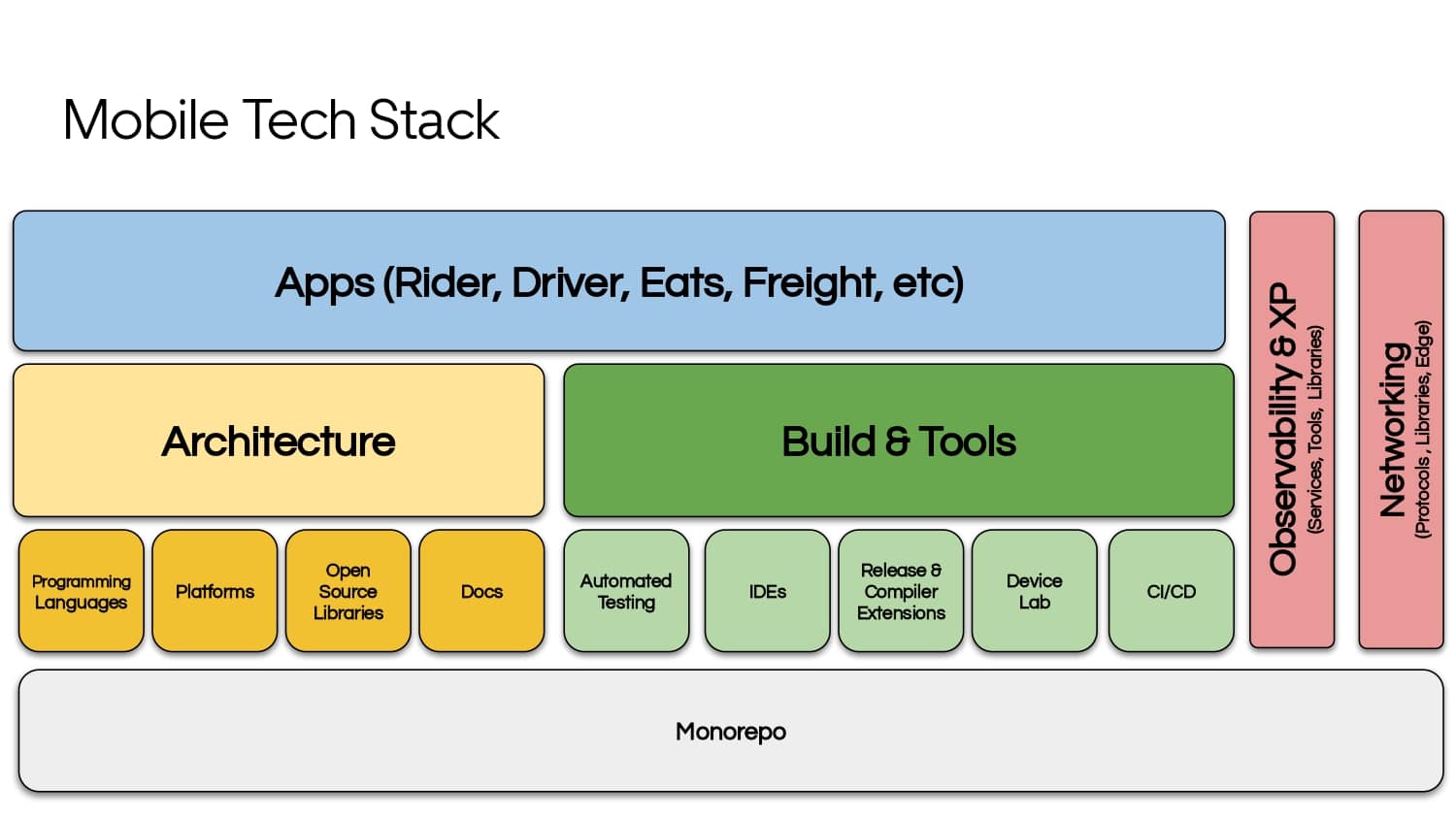
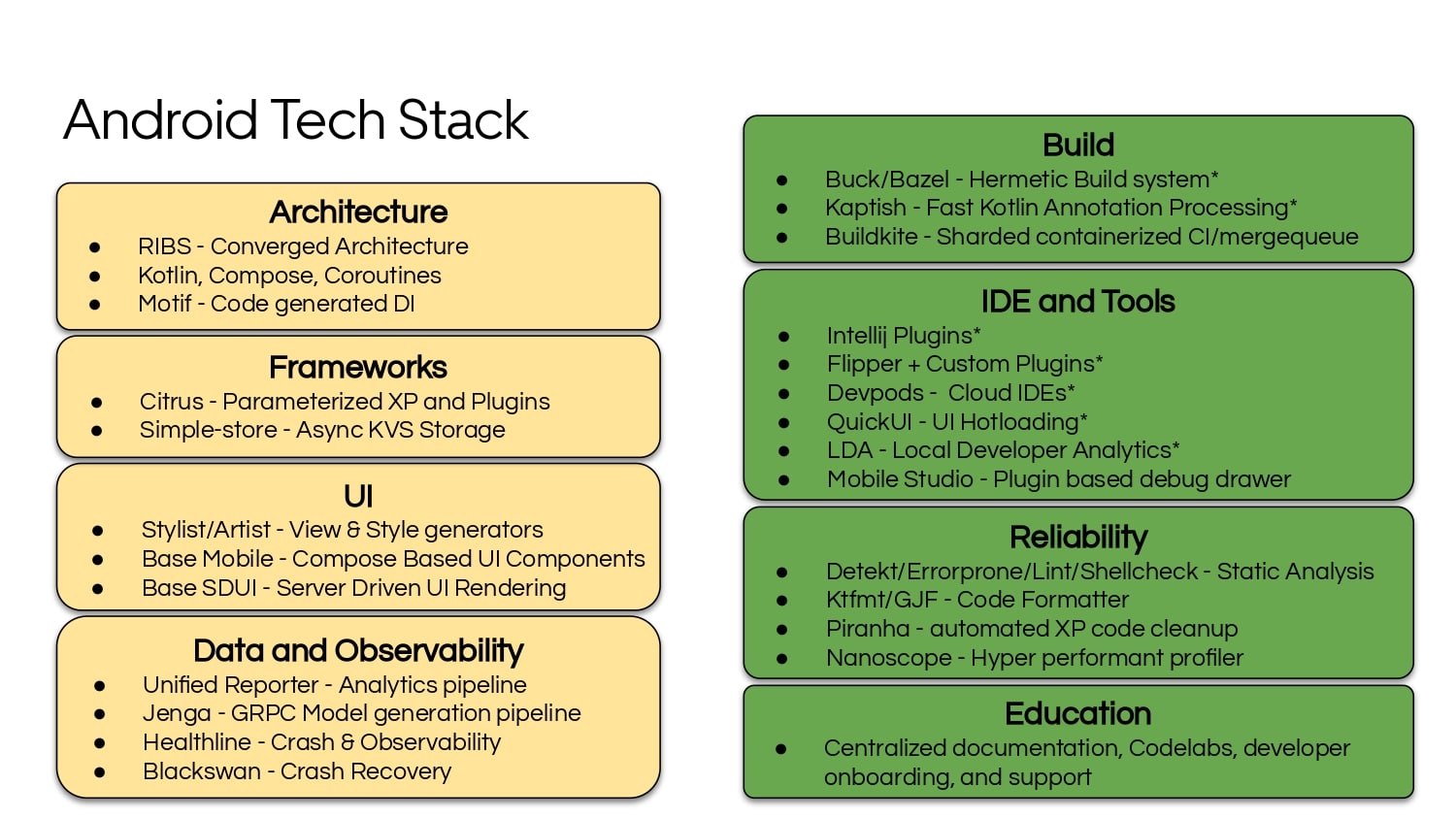
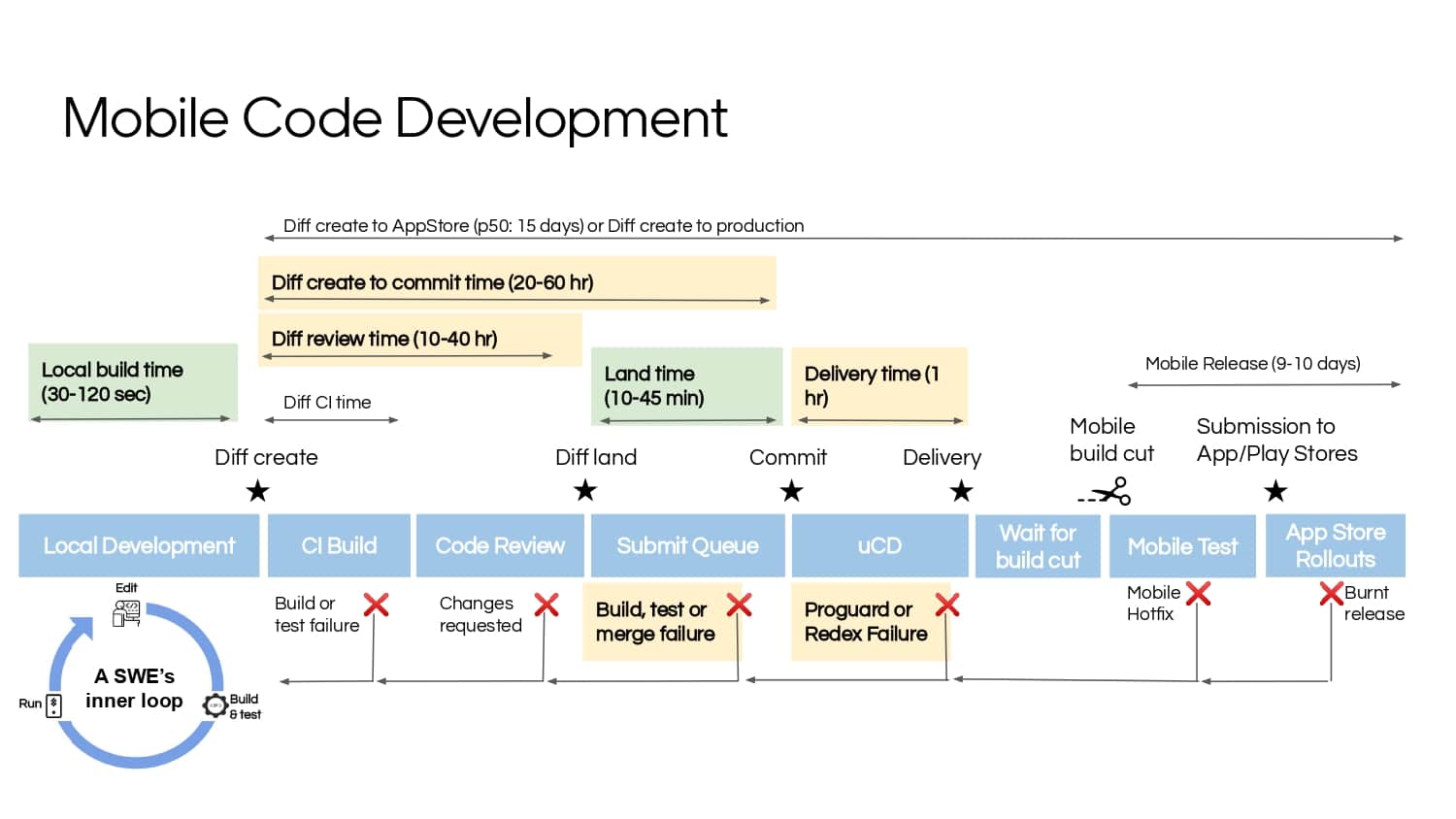
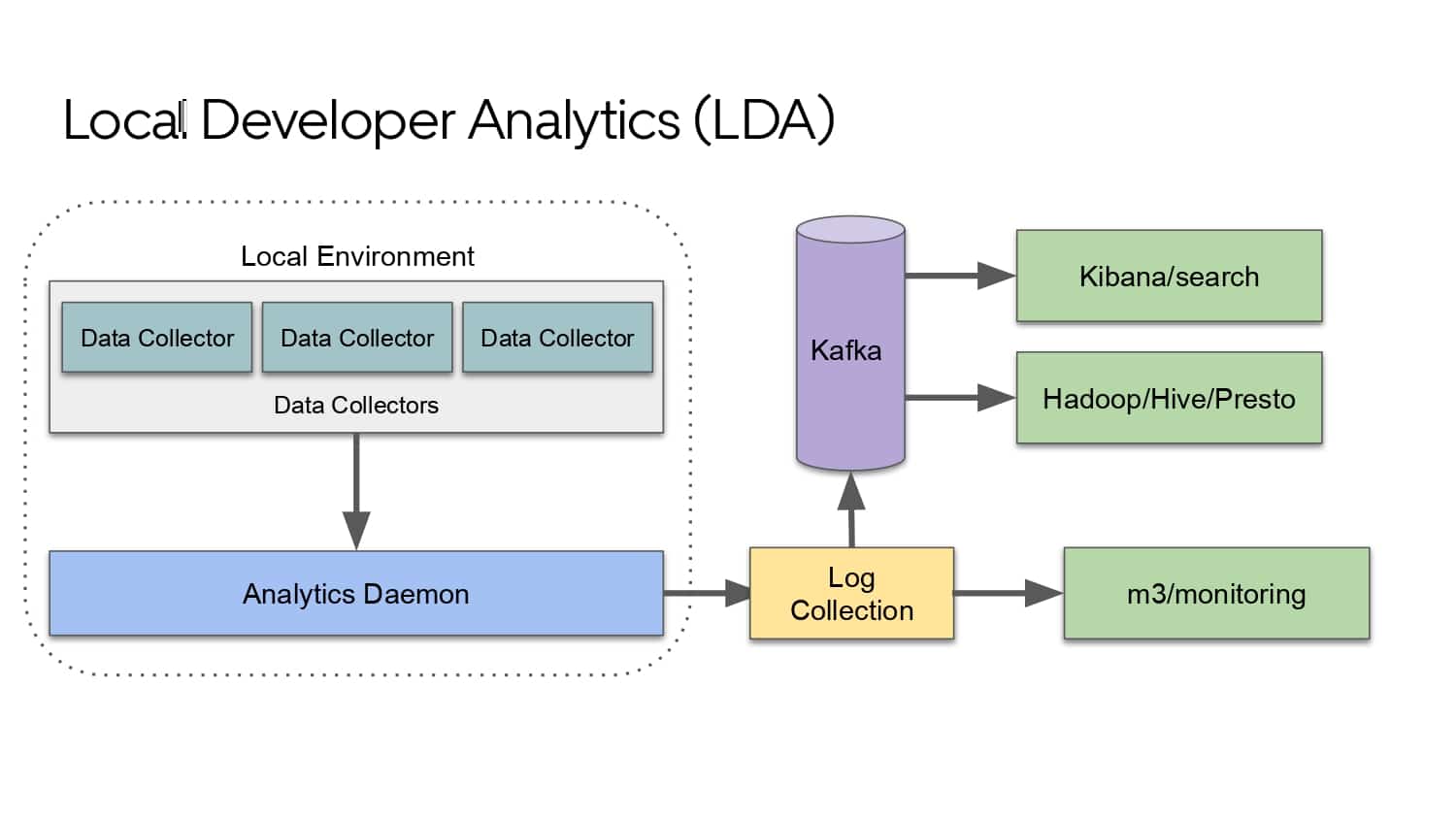
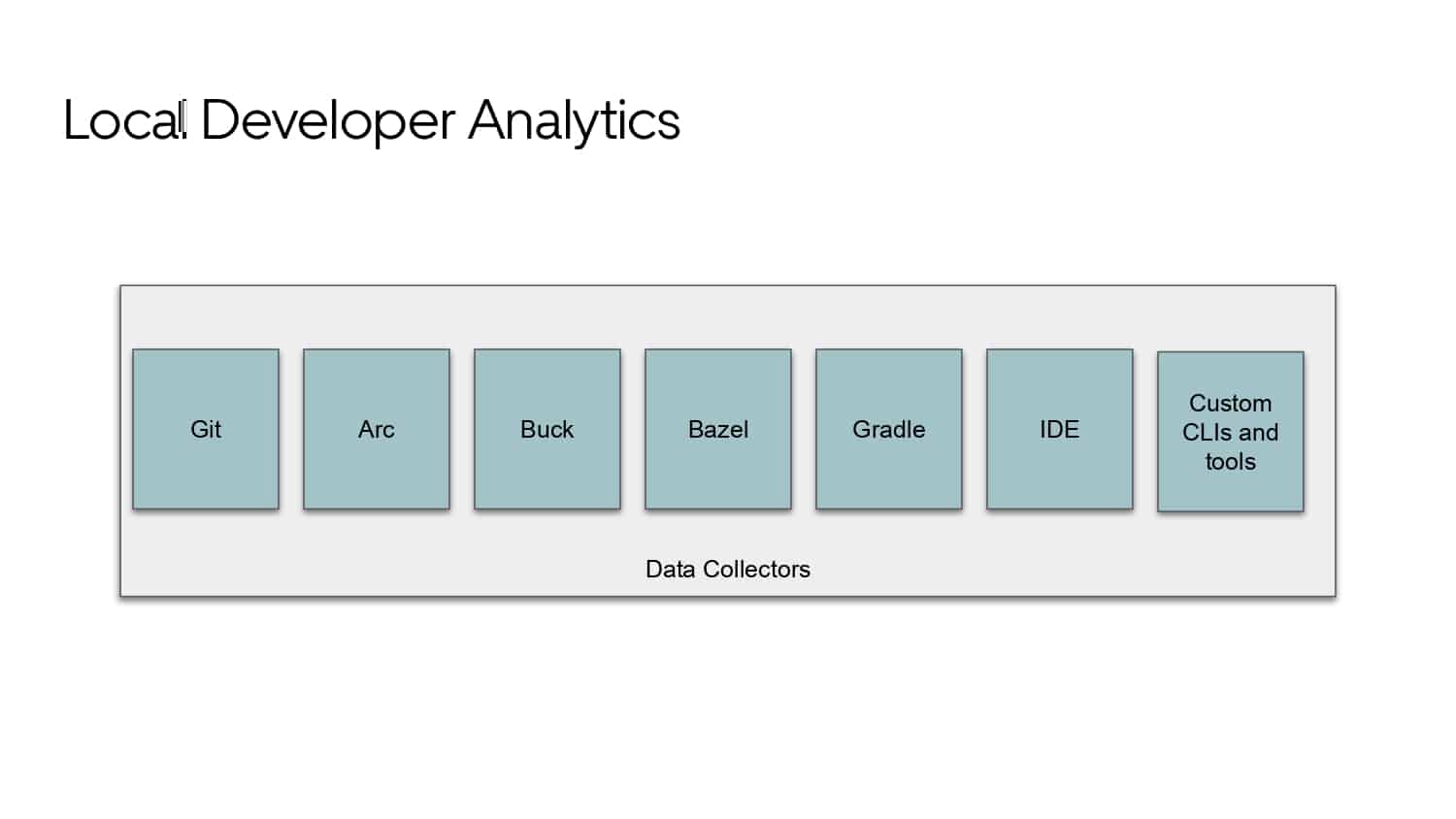
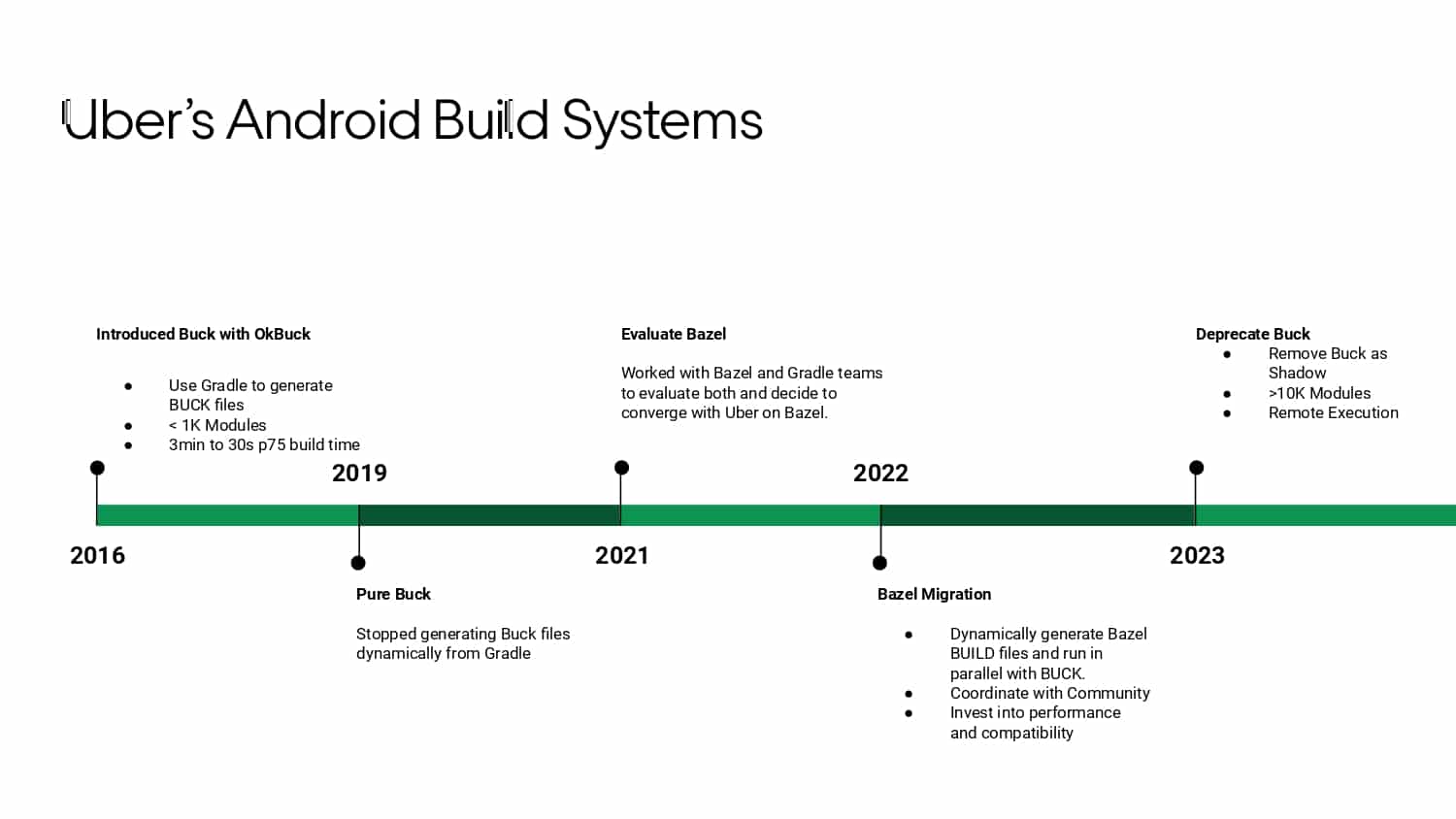
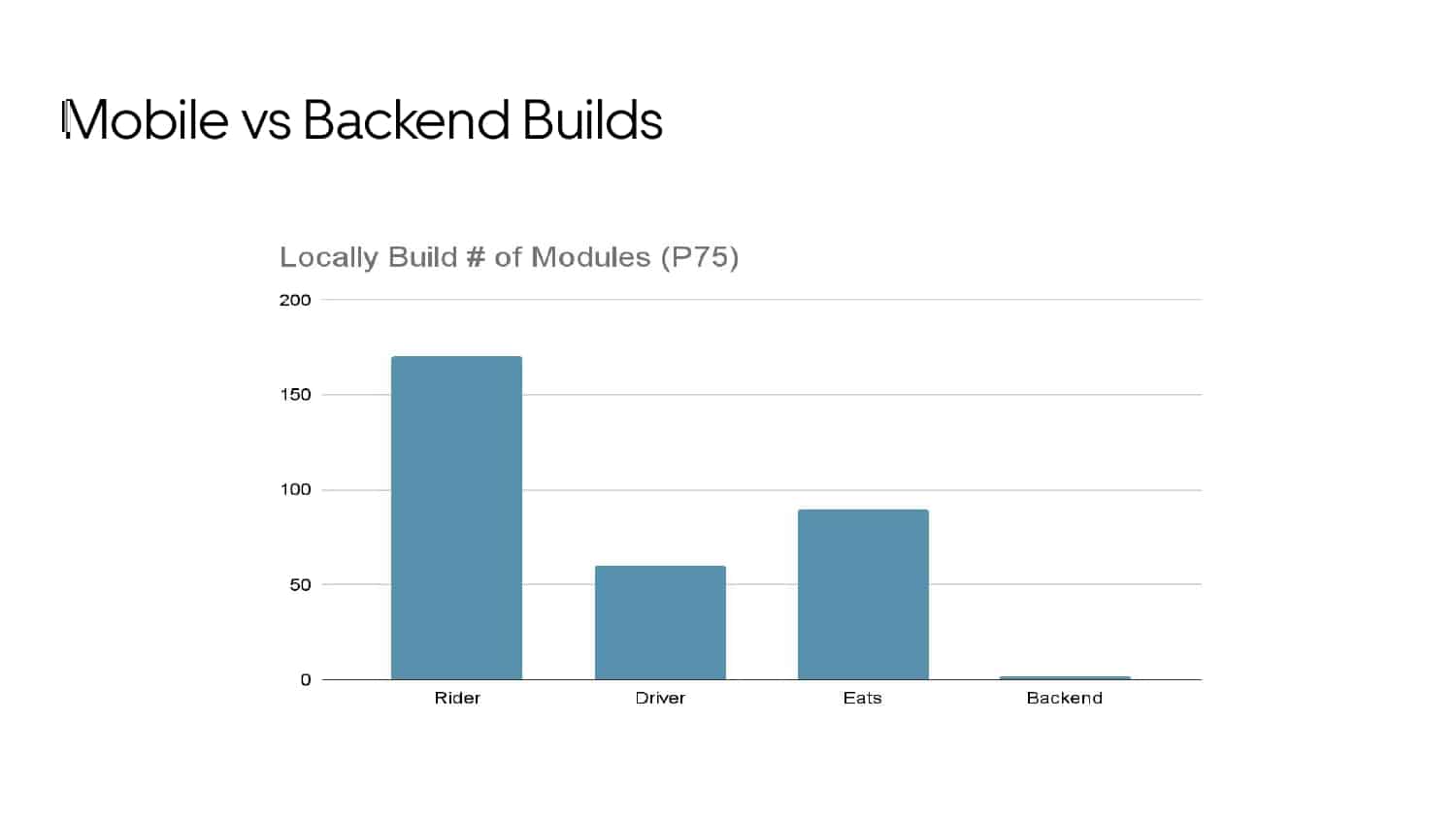
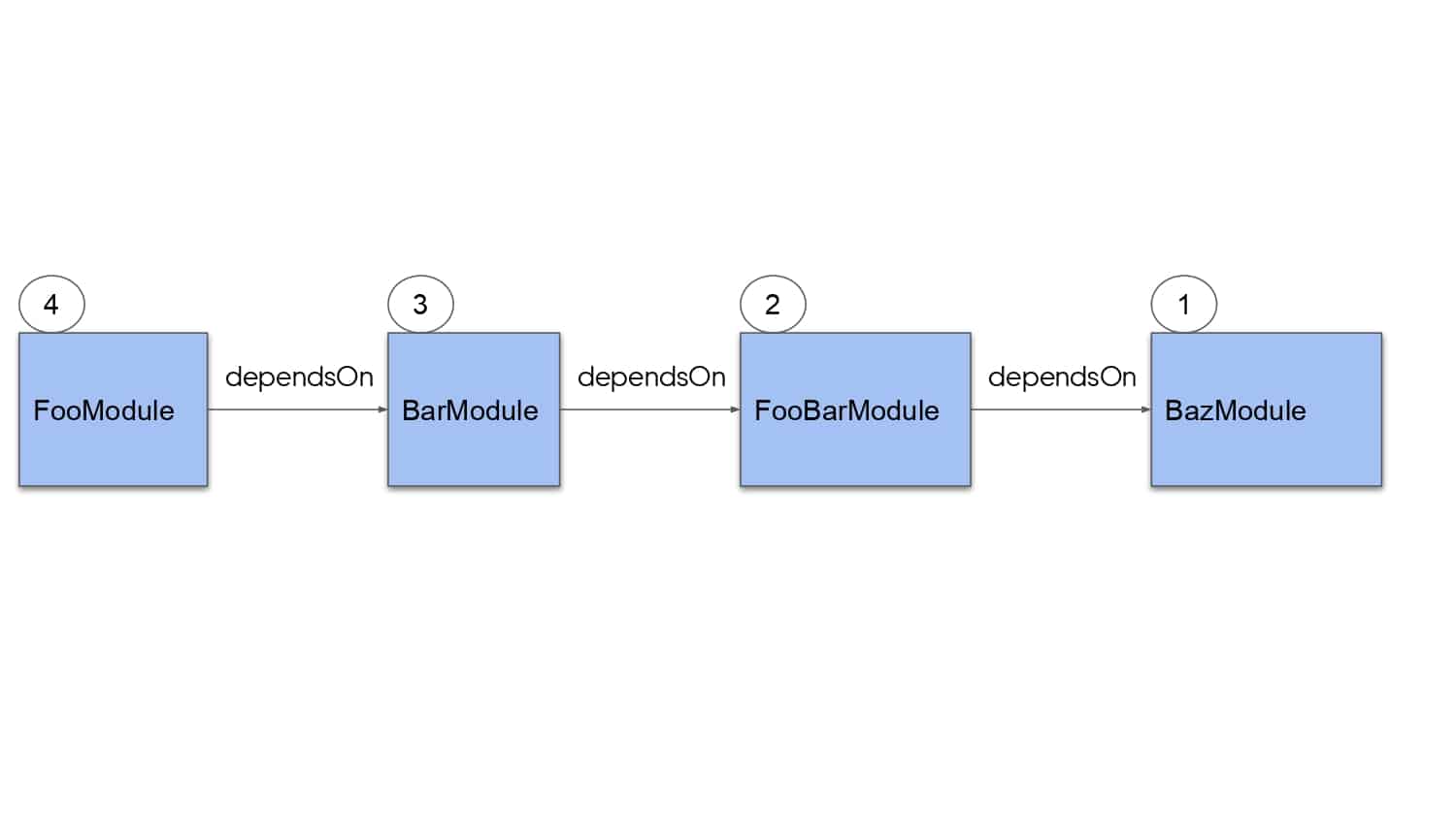
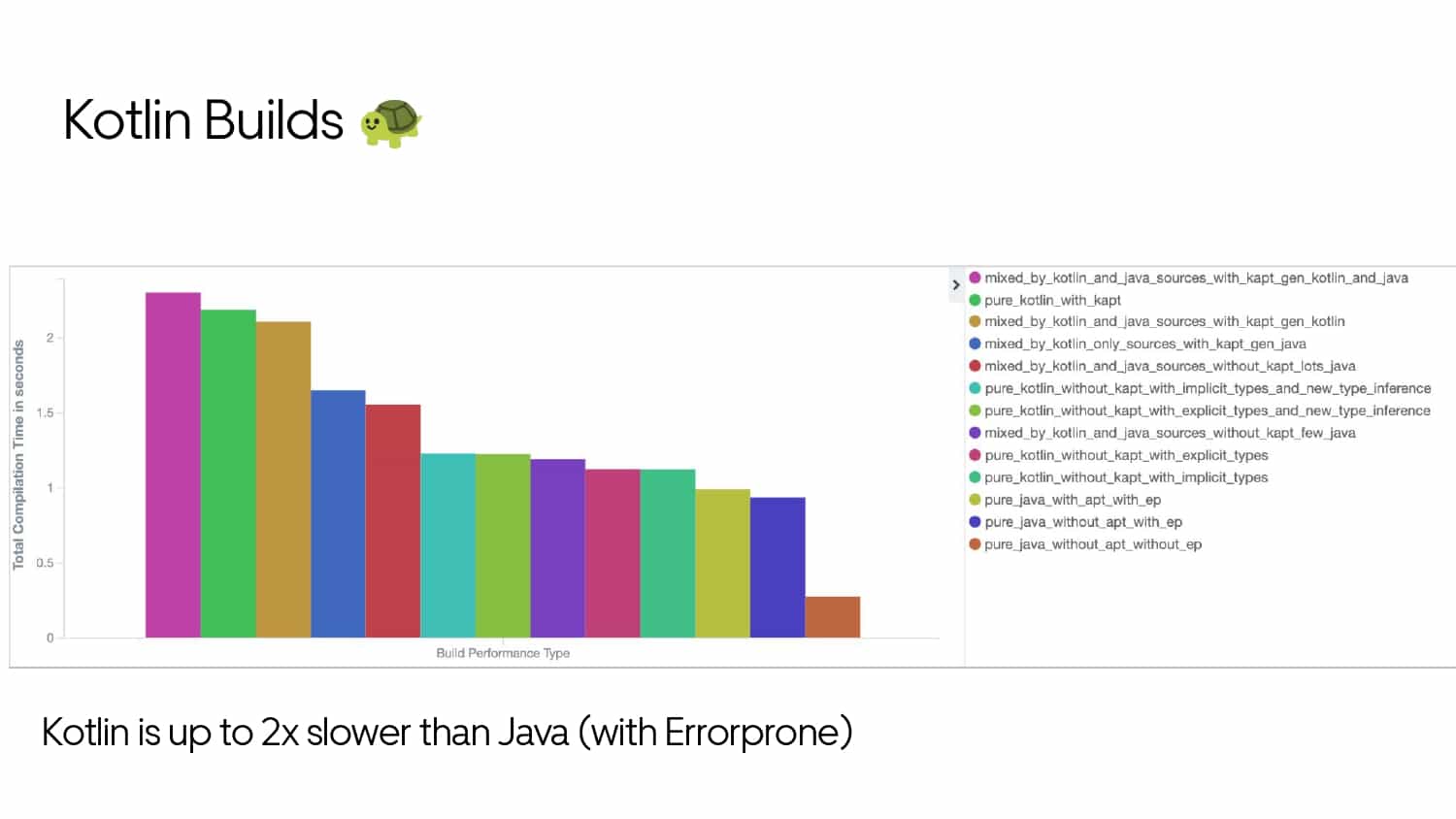
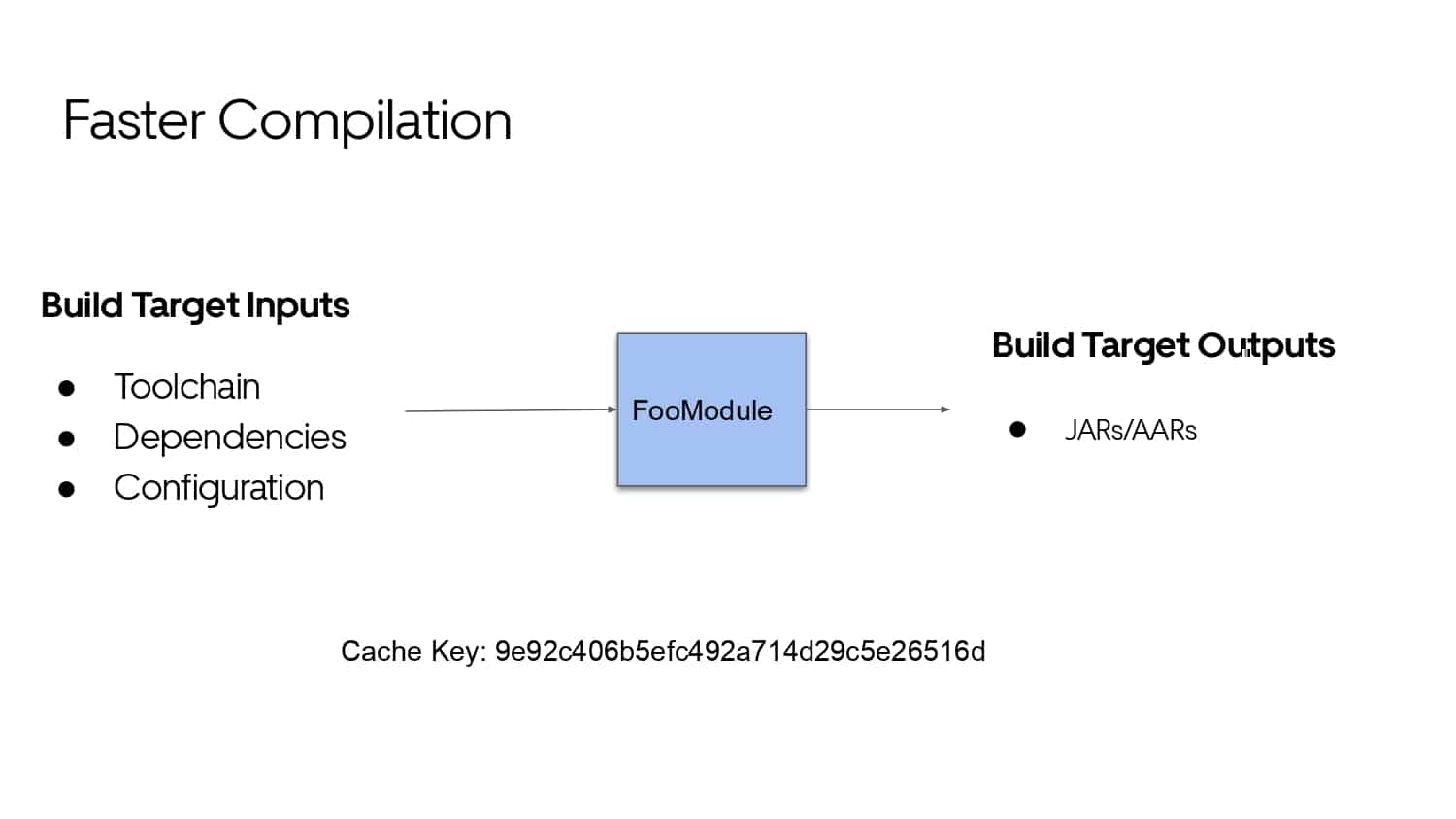
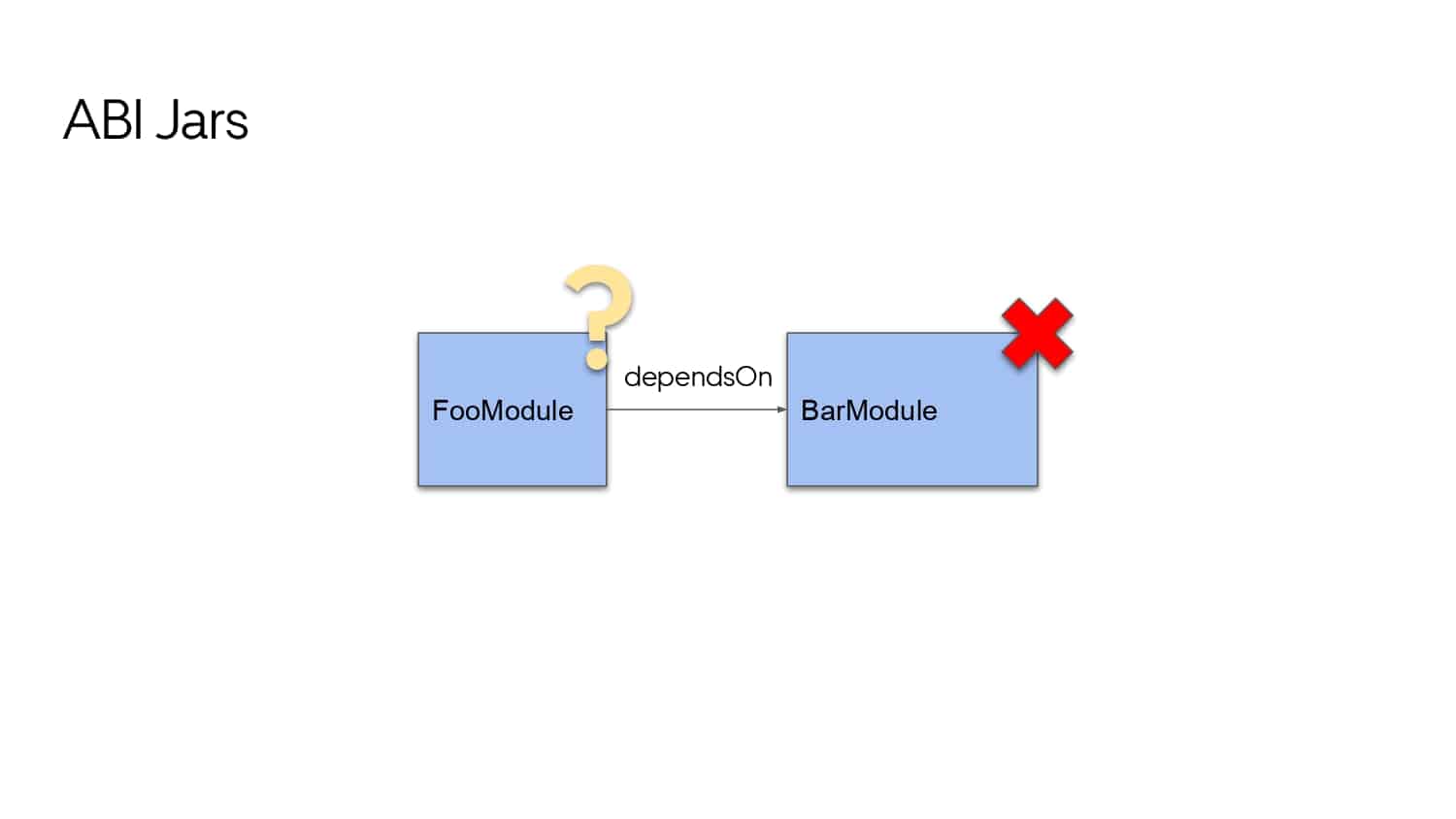
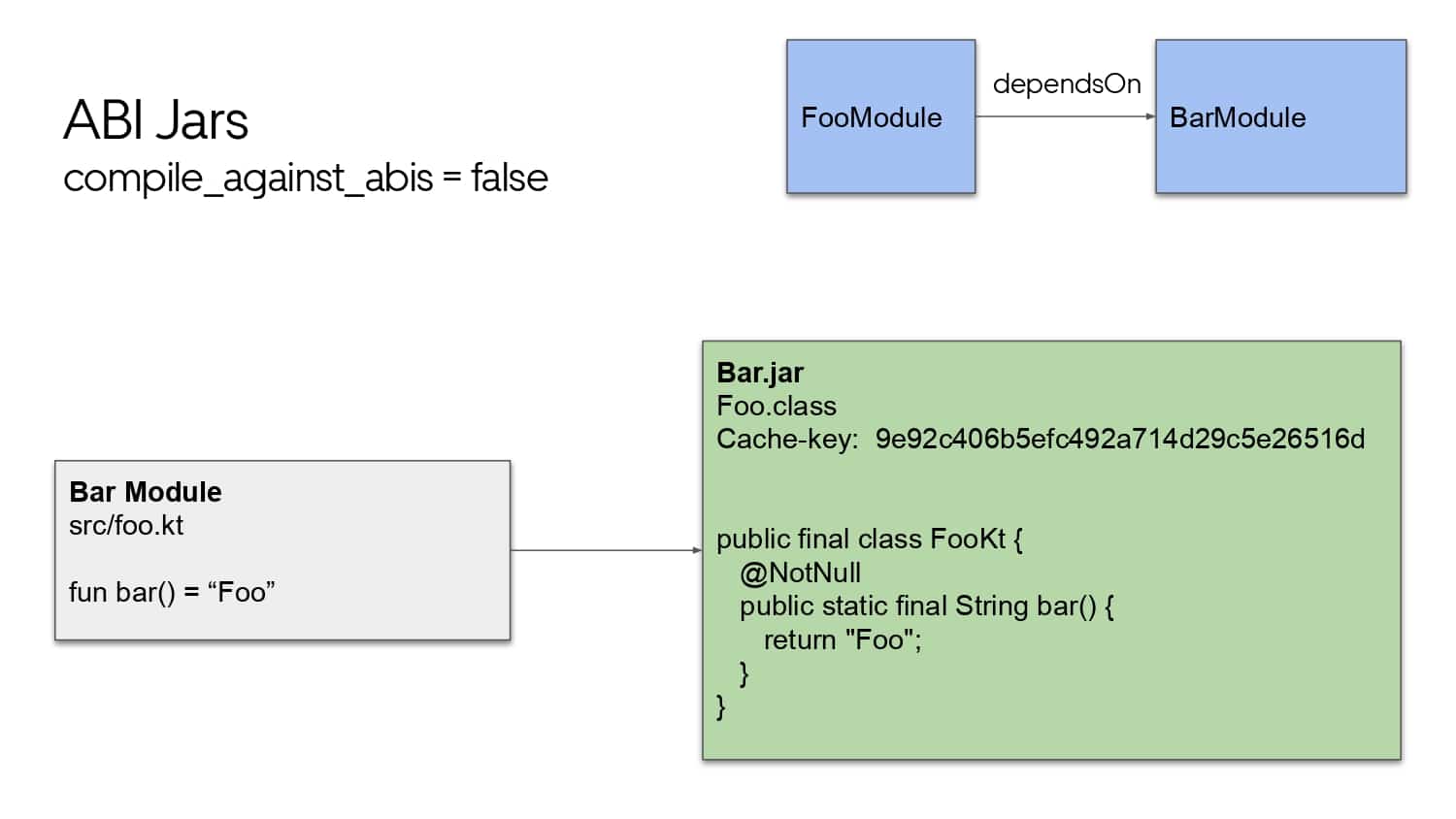
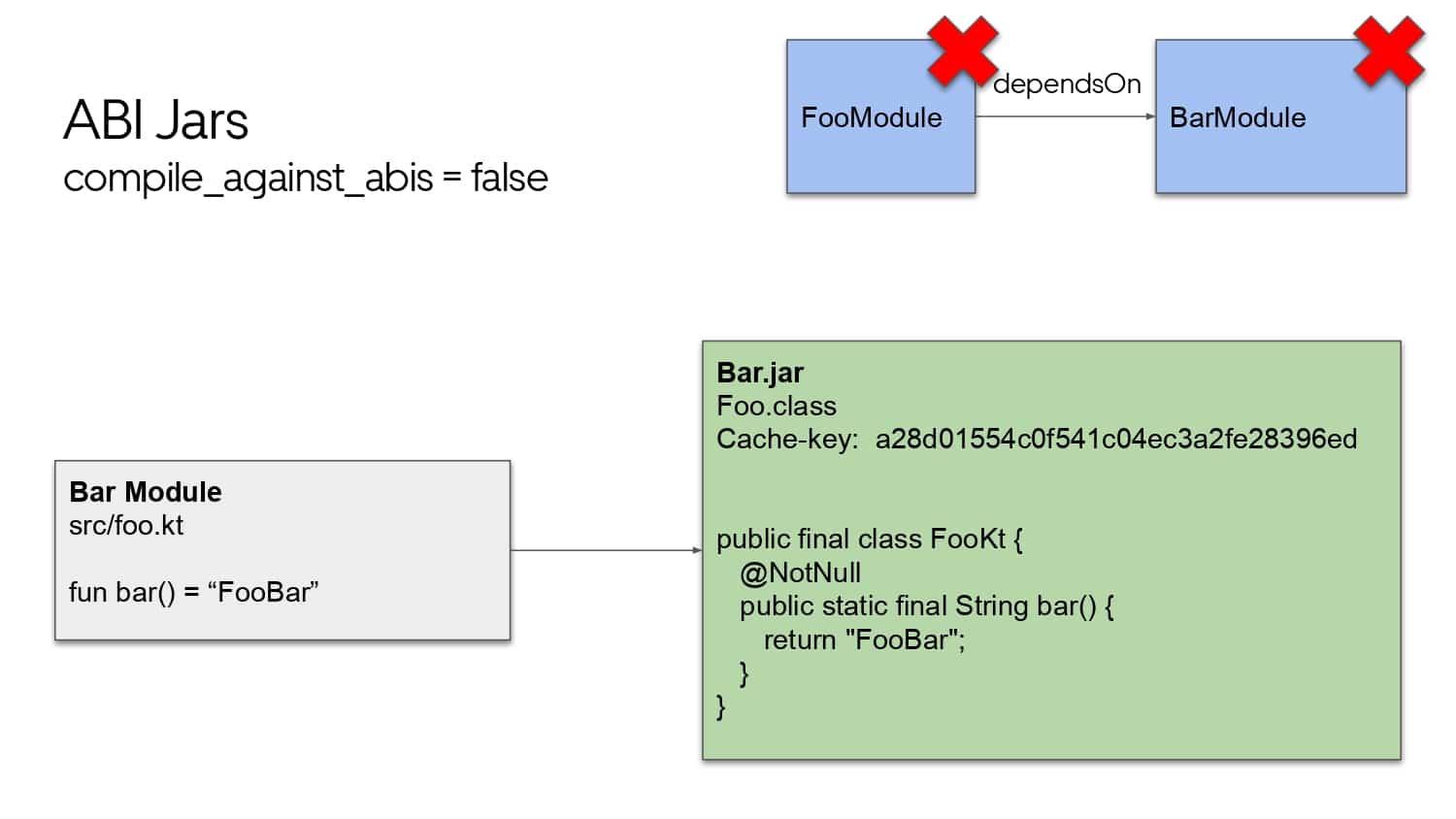
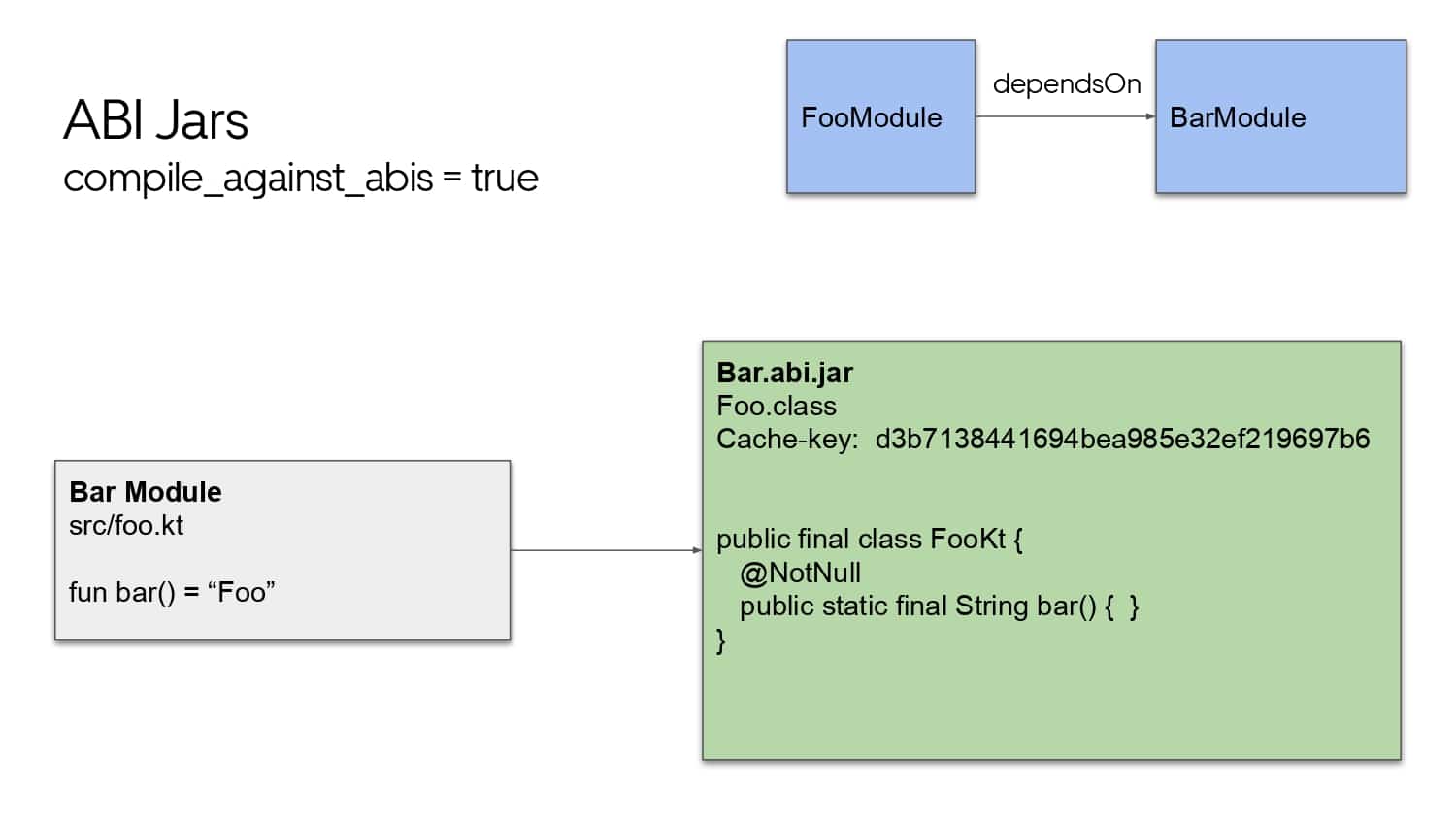
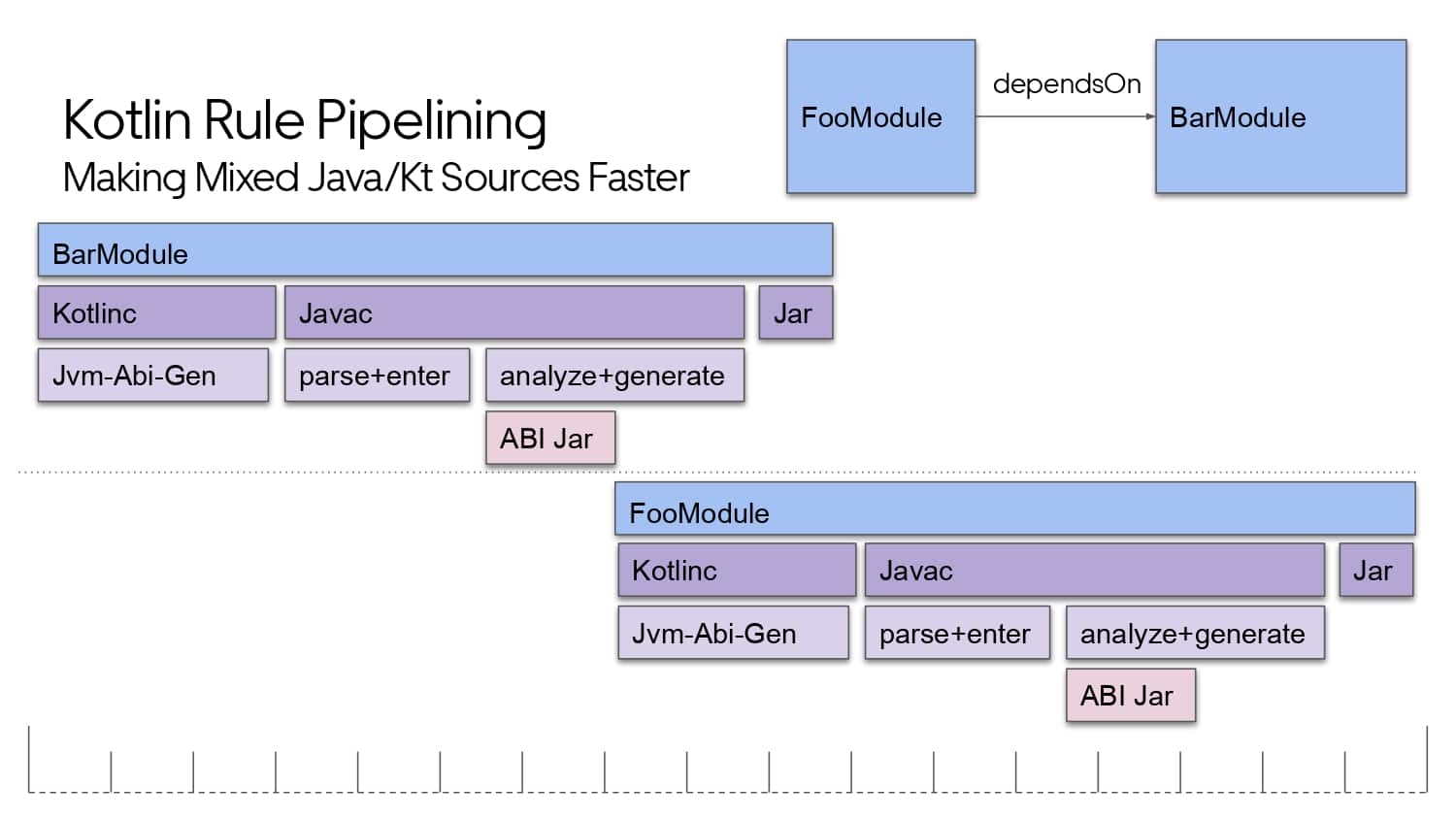
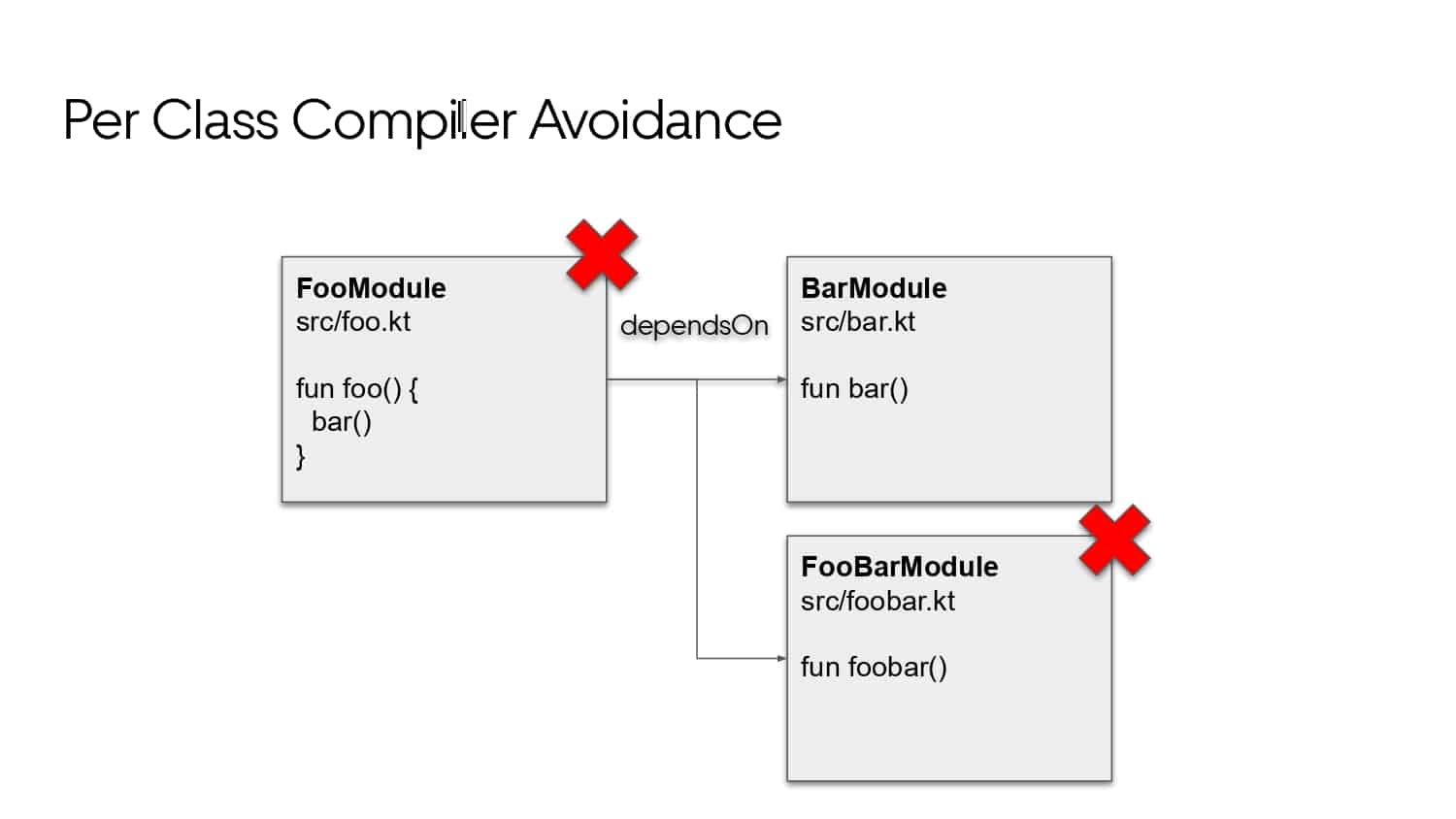
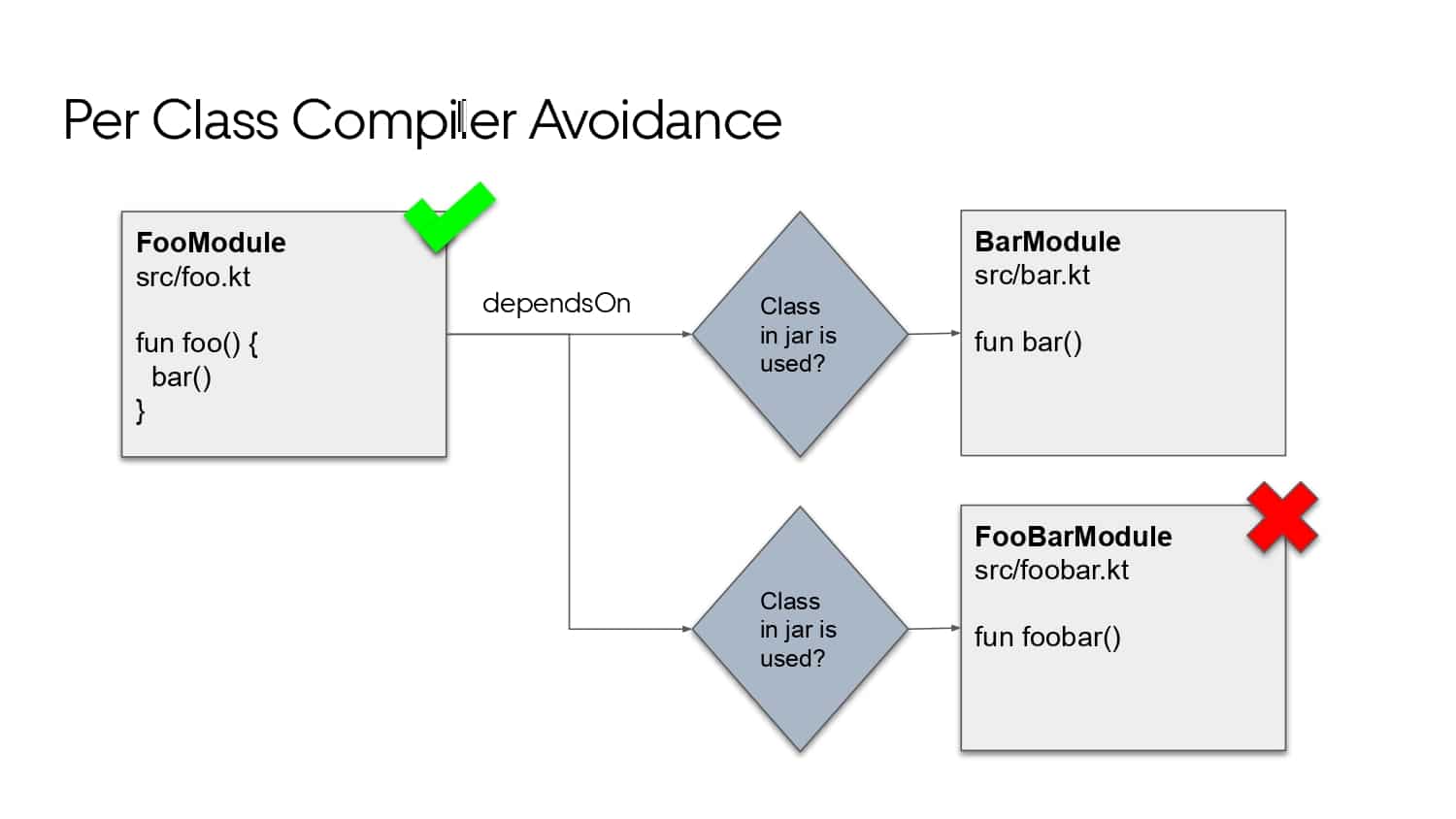
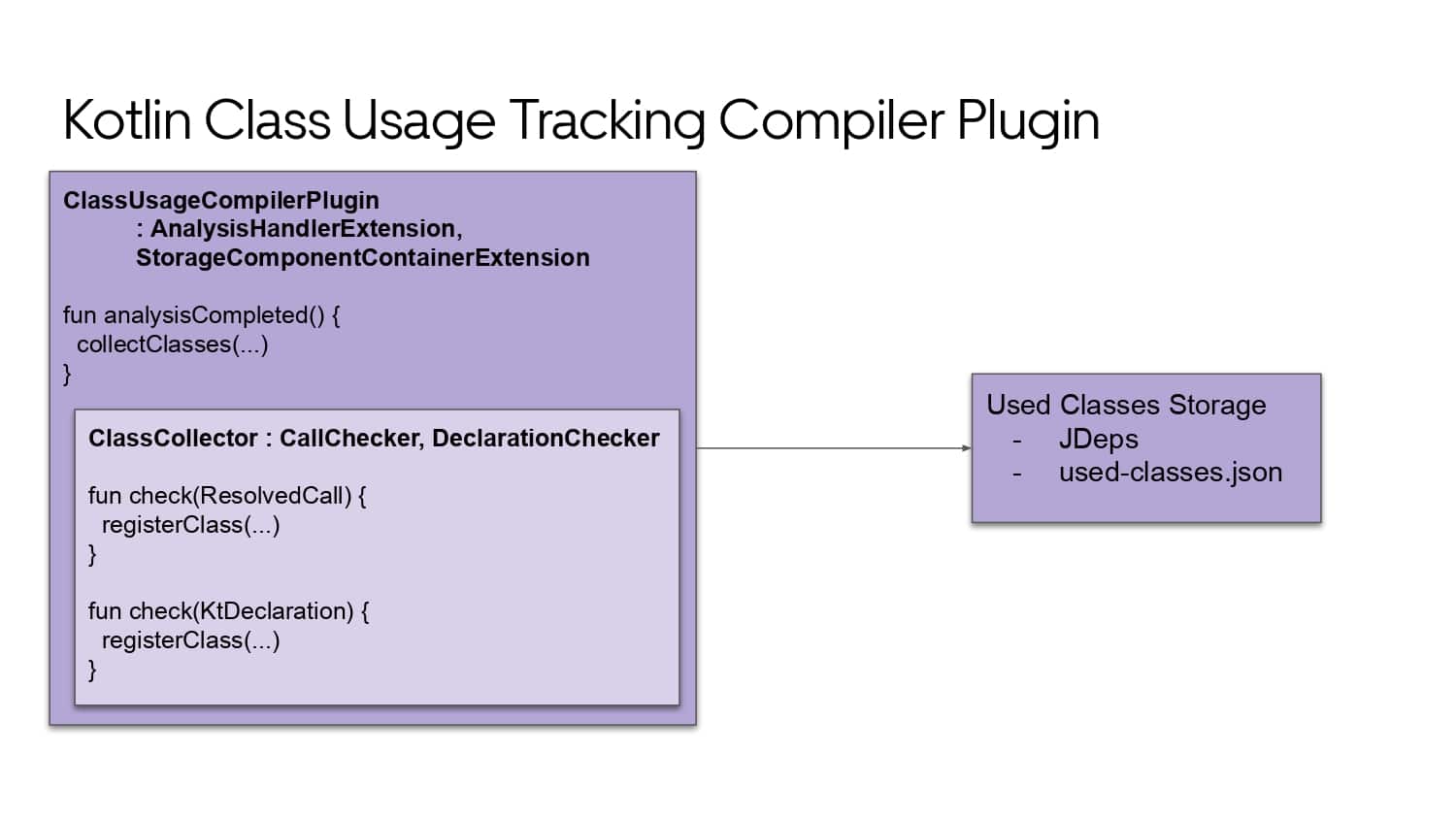
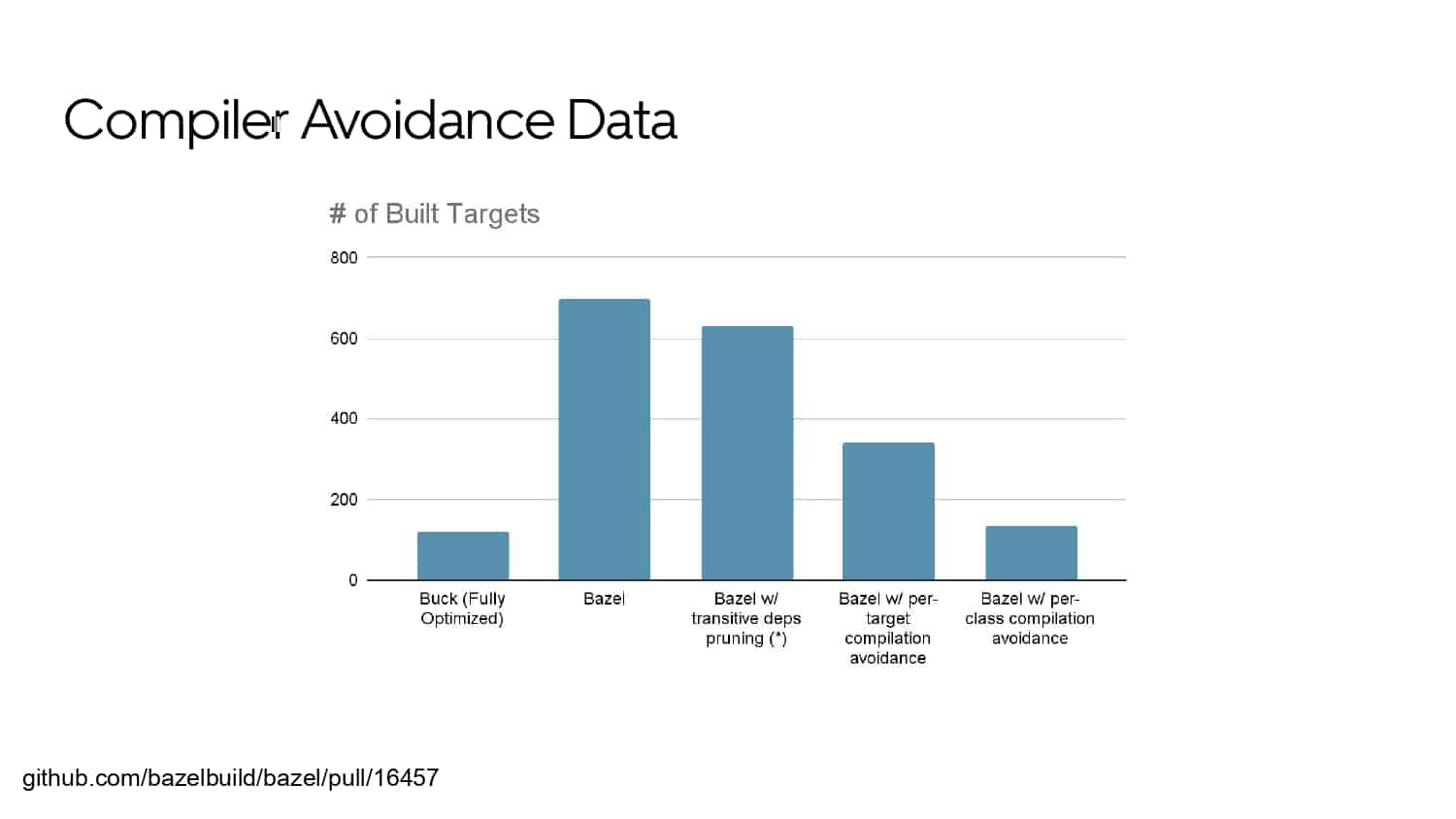
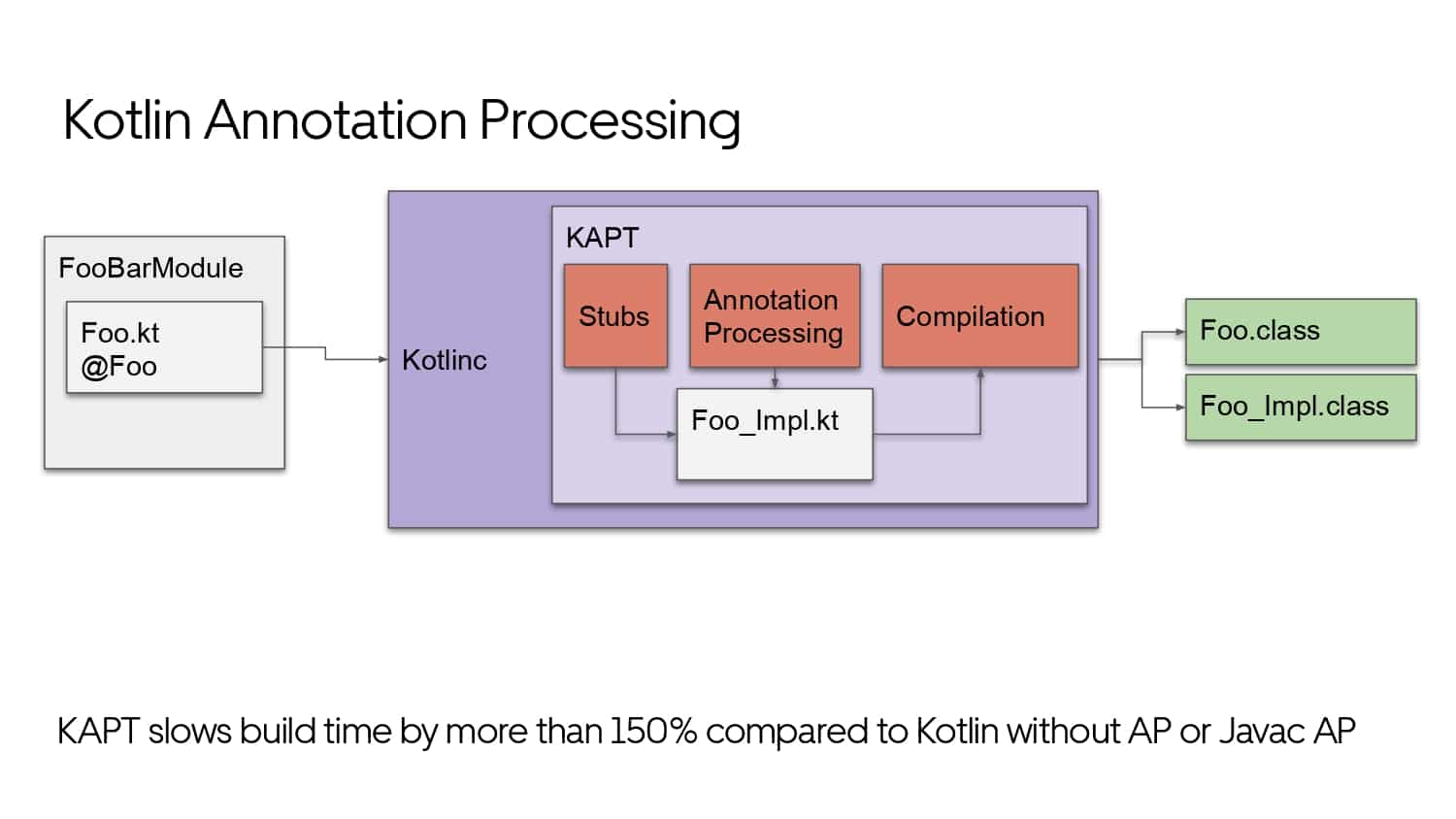
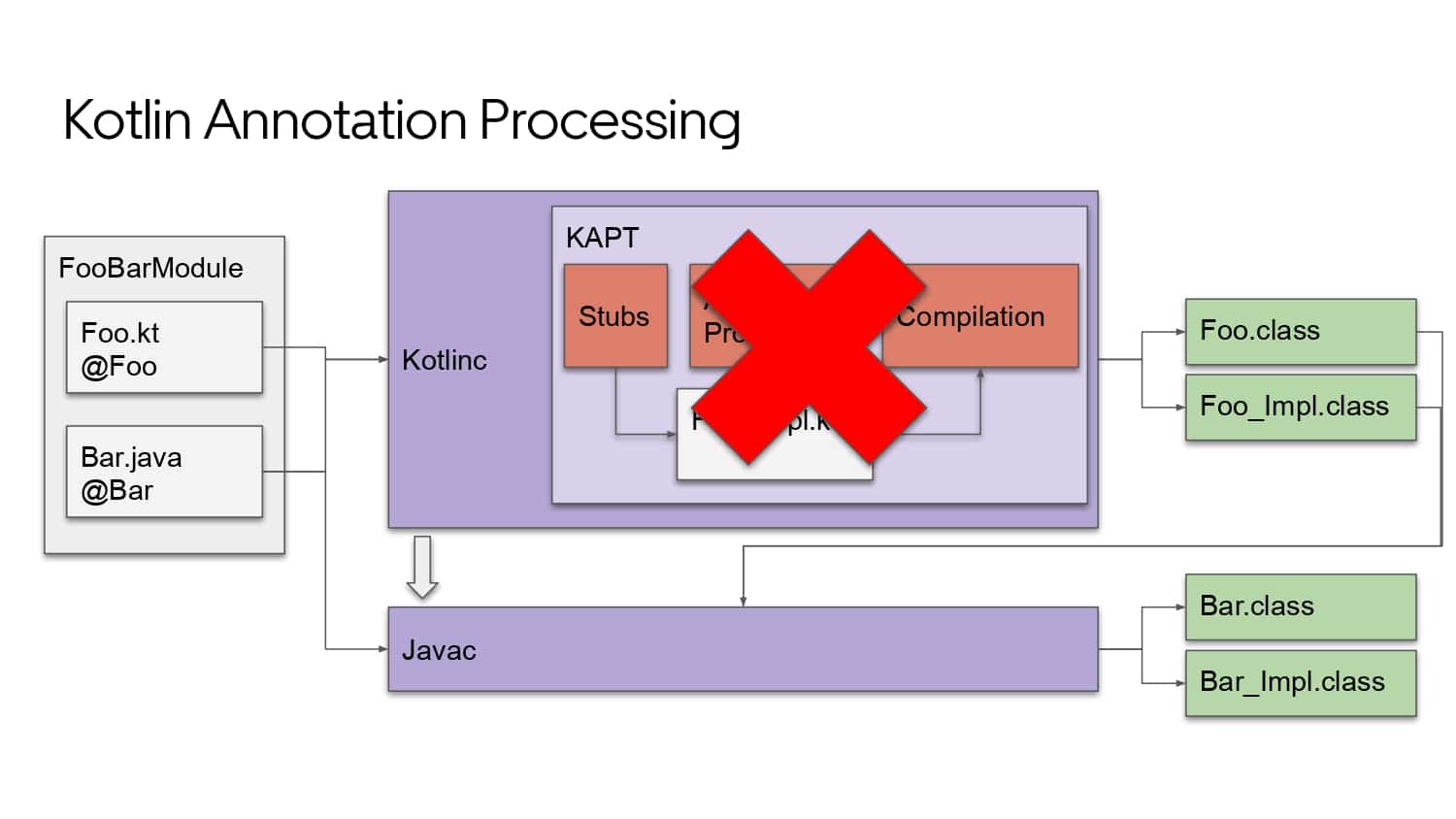
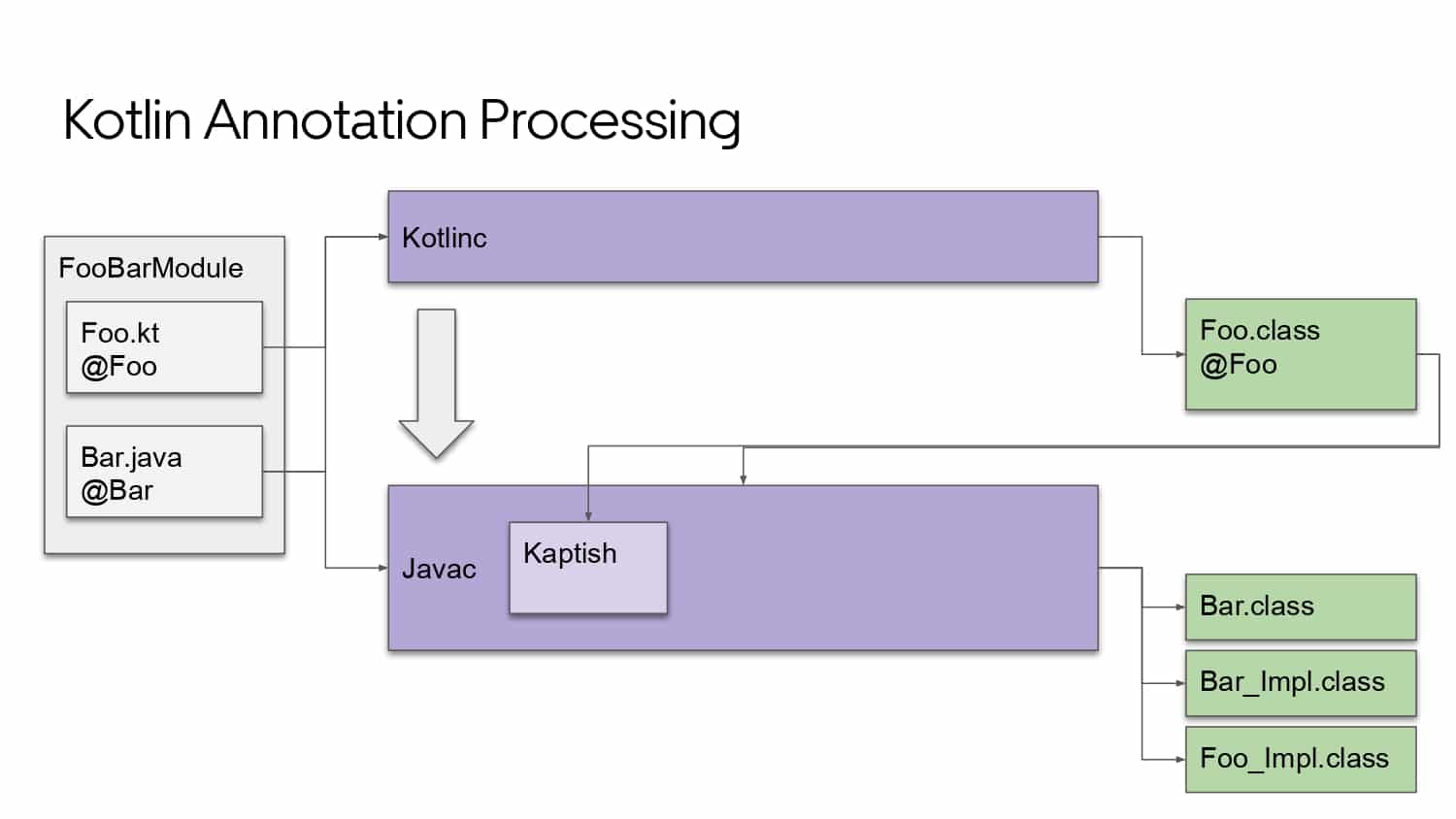
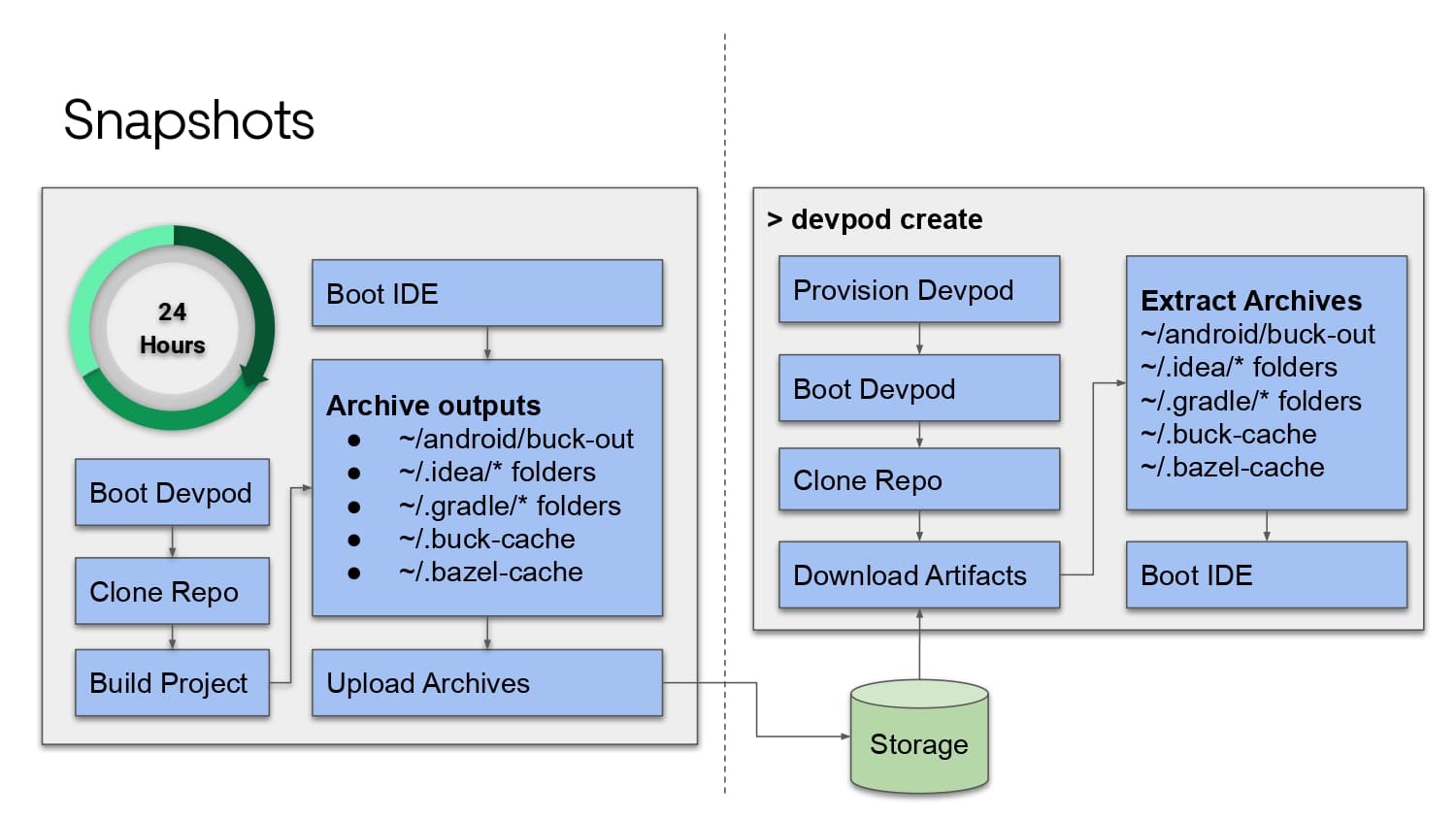
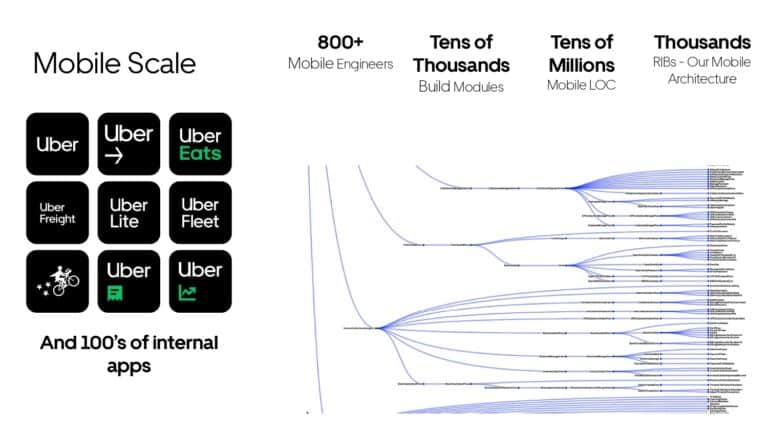
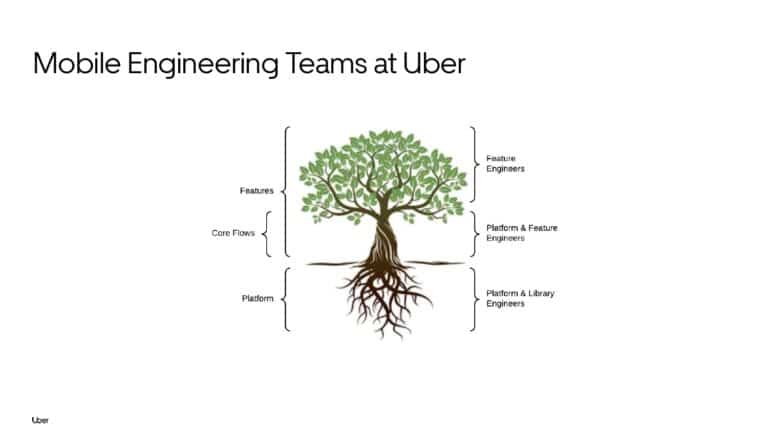
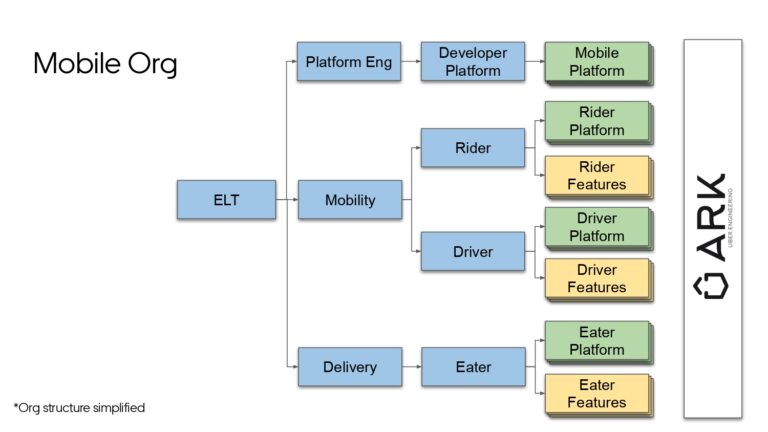
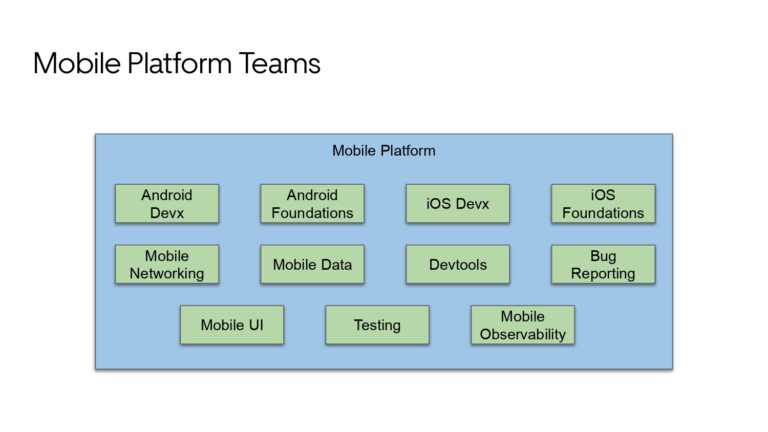
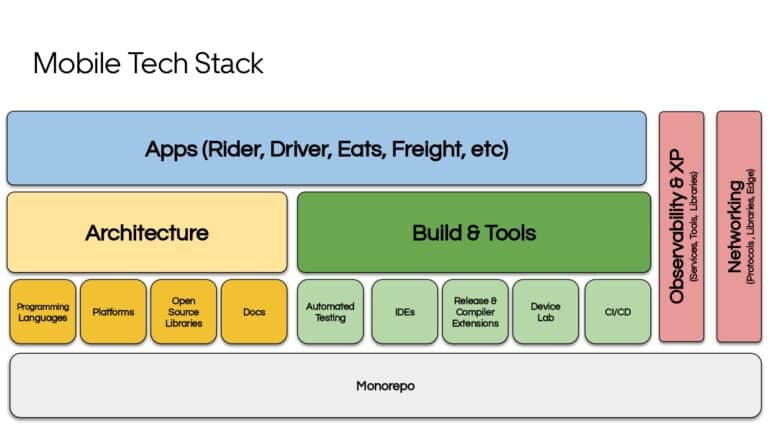
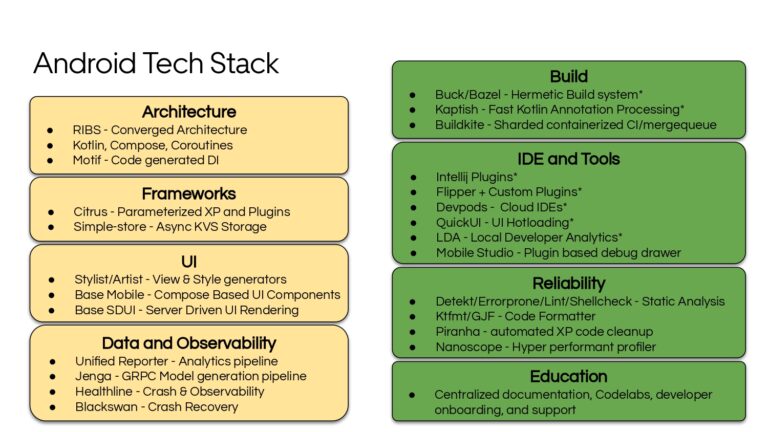
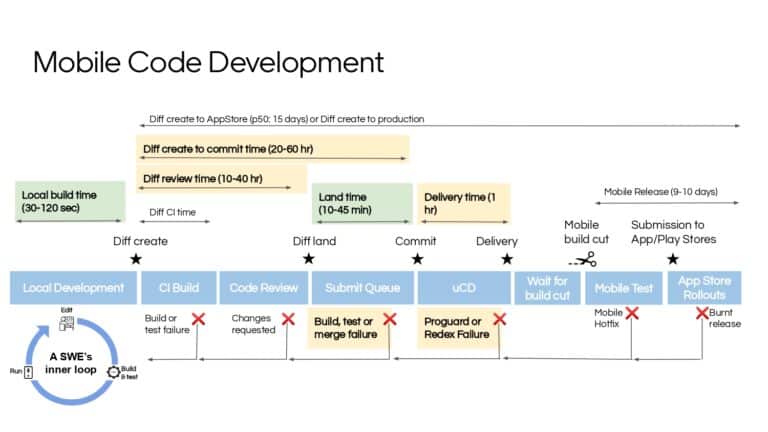
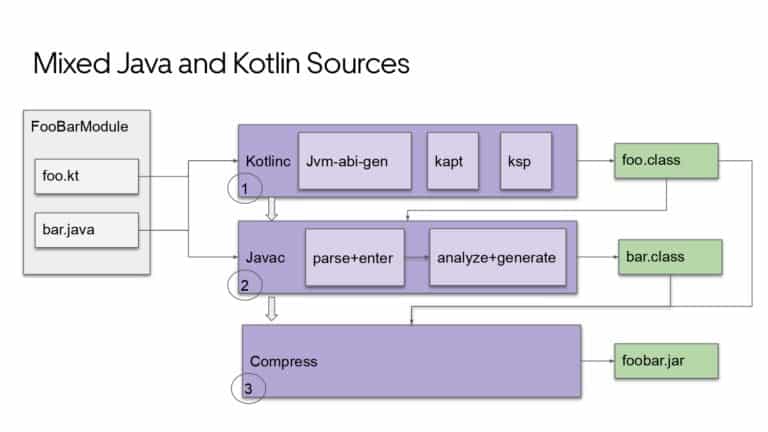
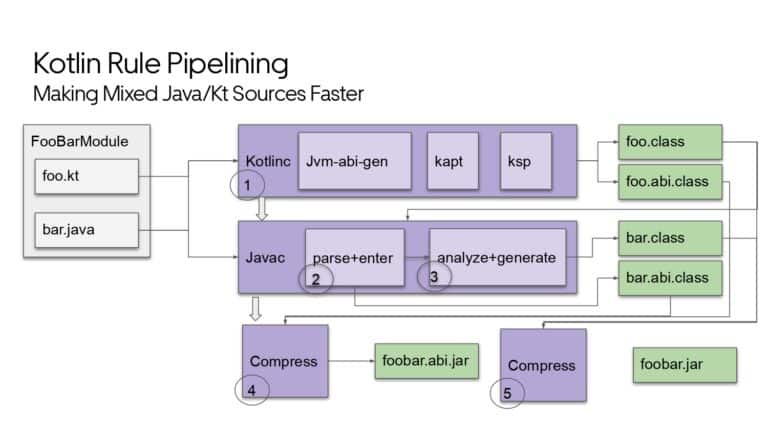
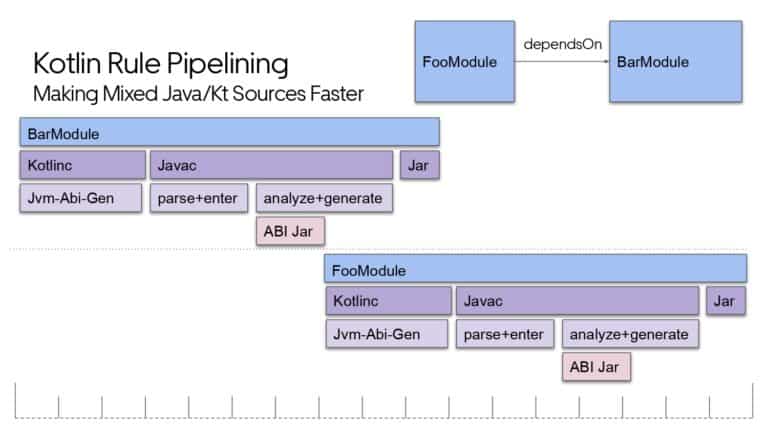
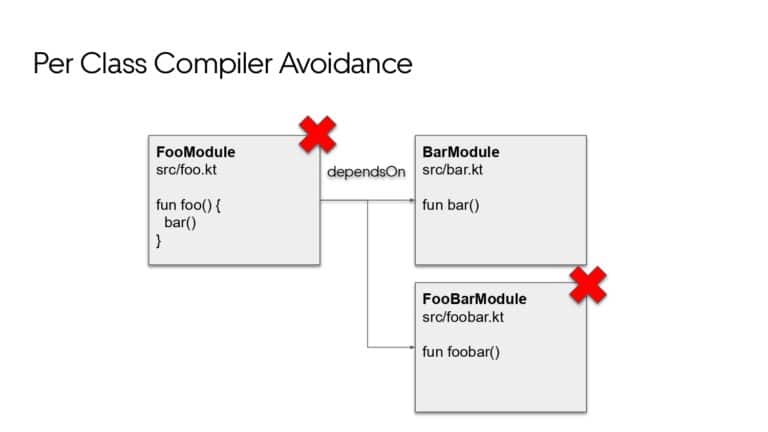
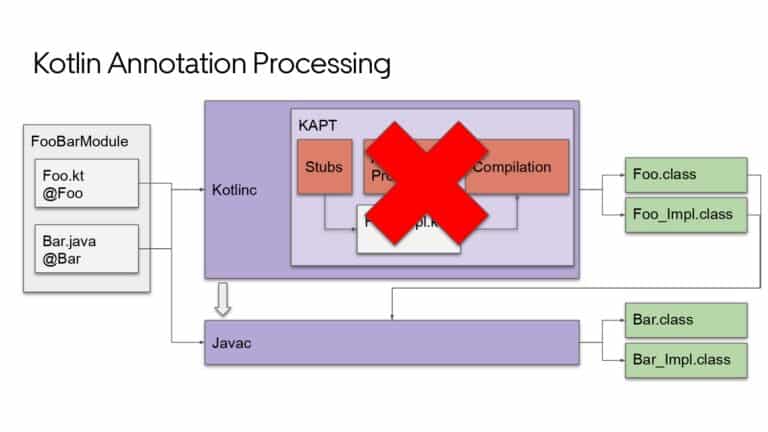
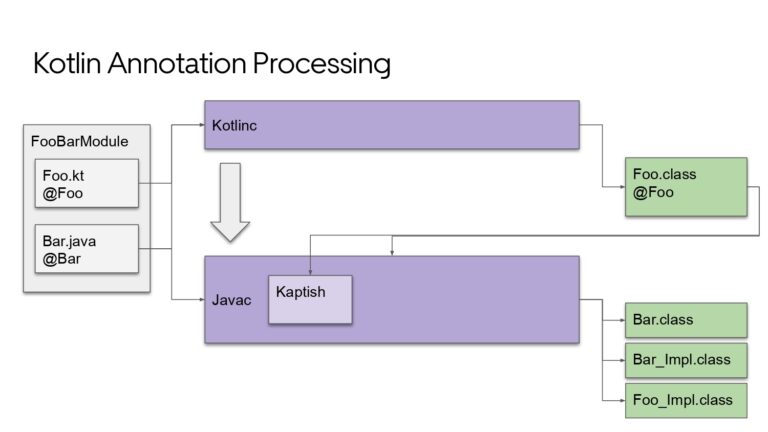
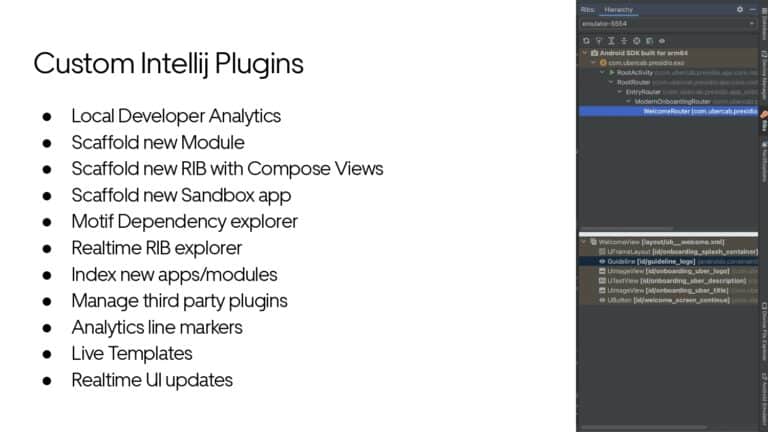
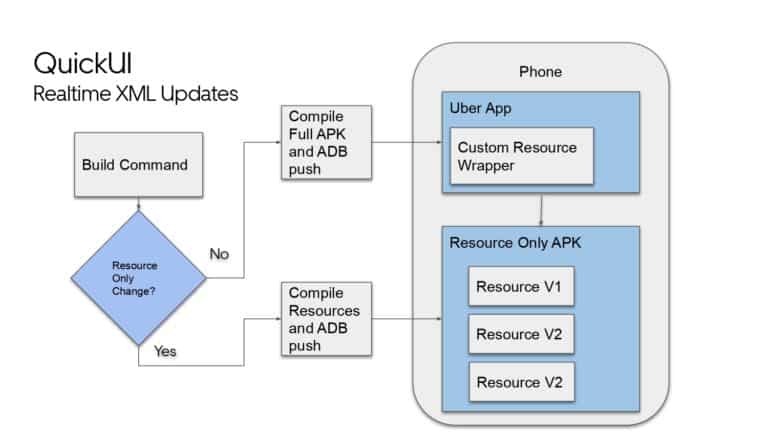
Building large mobile apps is hard. Keeping developers productive while working on large mobile apps is harder. Most Android developer tools target smaller apps, so what’s the best way to think about building some of the largest apps in the world? In this talk, you’ll learn how Uber enables hundreds of Android developers to contribute to hundreds of apps in a single monorepo while keeping developers productive and shipping reliable apps quickly.
Building large mobile apps is hard. Keeping developers productive while working on large mobile apps is harder. Most Android developer tools target smaller apps, so what’s the best way to think about building some of the largest apps in the world? In this talk, you’ll learn how Uber enables hundreds of Android developers to contribute to hundreds of apps in a single monorepo while keeping developers productive and shipping reliable apps quickly.
About Ty
Ty Smith is a senior staff engineer at Uber, where he leads the Android platform group and chairs the Uber’s Open-Source Technical Steering Committee. He is passionate about tools, frameworks, and open-source to help developers make great mobile apps. Ty is a Google Developer Expert for Android and Kotlin, engaging regularly with the community through conferences, open-source, and writing, and as an organizer for conferences and meetups. He is an angel investor, tech advisor, and a member of multiple venture capital advisory syndicates. Ty has been at Uber for six years. Before that, he worked at Twitter on the Fabric developer tools, Evernote, and a variety of smaller startups and consulting firms.
Ty Smith is a senior staff engineer at Uber, where he leads the Android platform group and chairs the Uber’s Open-Source Technical Steering Committee. He is passionate about tools, frameworks, and open-source to help developers make great mobile apps. Ty is a Google Developer Expert for Android and Kotlin, engaging regularly with the community through conferences, open-source, and writing, and as an organizer for conferences and meetups. He is an angel investor, tech advisor, and a member of multiple venture capital advisory syndicates. Ty has been at Uber for six years. Before that, he worked at Twitter on the Fabric developer tools, Evernote, and a variety of smaller startups and consulting firms.
More information related to this topic
Gradle Enterprise
Solutions for Android Developer Productivity

Performance Acceleration technologies for Android eliminate the pain of idle wait time and avoidable context switching resulting from long build and test feedback cycle times. Gradle Build Scans for Android give you granular analytic information for every build. Failure Analytics can leverage build data to proactively find unreliable builds and tests and learn how many people and environments are affected by the problem. Finally, Flaky Test Management will help you proactively detect flakiness in your application and tests.
Slides