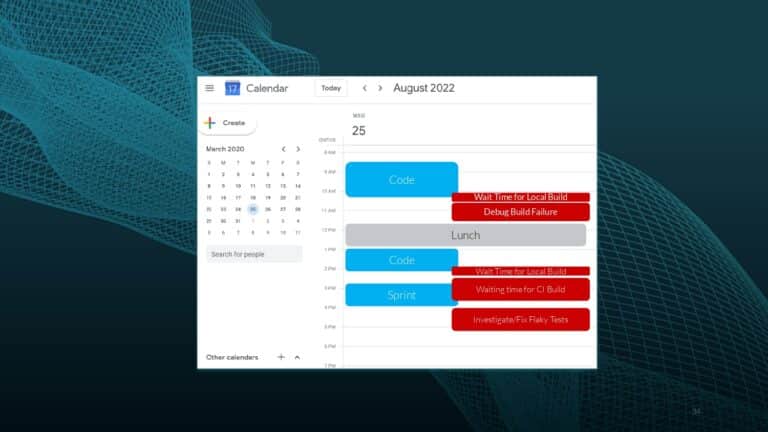
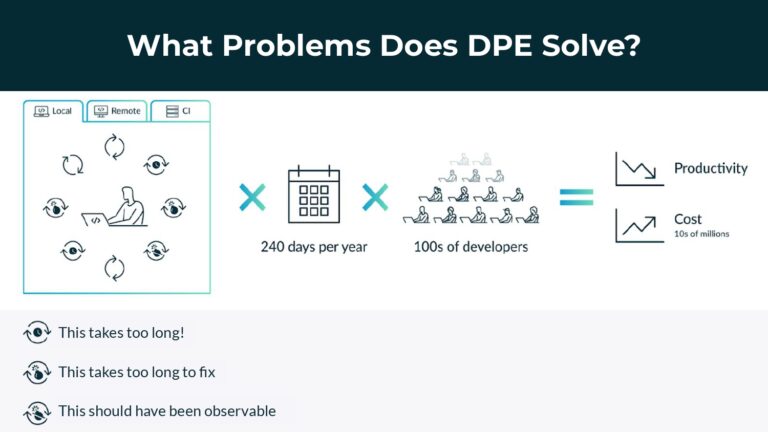
Over the last decade, DevOps has emerged as a core business philosophy and practice that helps teams drive high-quality software to market faster. While DevOps focuses on eliminating bottlenecks caused by the gap between development and operational resources, outside of that scope even the magical “10x developer” still toils daily with productivity challenges like slow builds, flaky tests, and other avoidable failures.
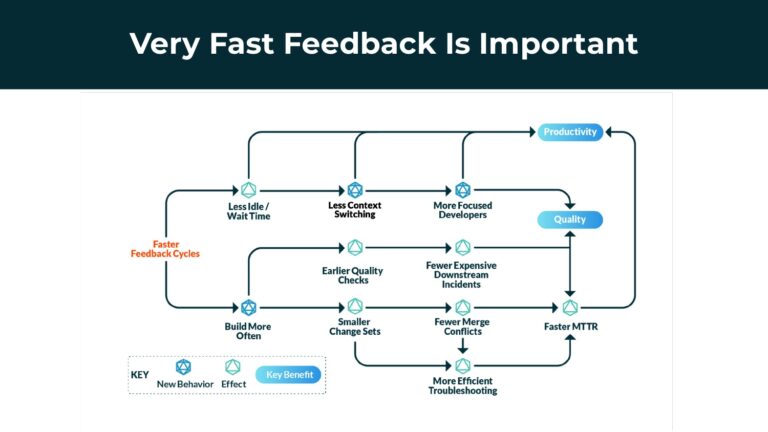
This talk demonstrates how Gradle Enterprise’s comprehensive Developer Productivity Engineering solution–including build and test acceleration, failure analytics, and observation technologies–can address these challenges.
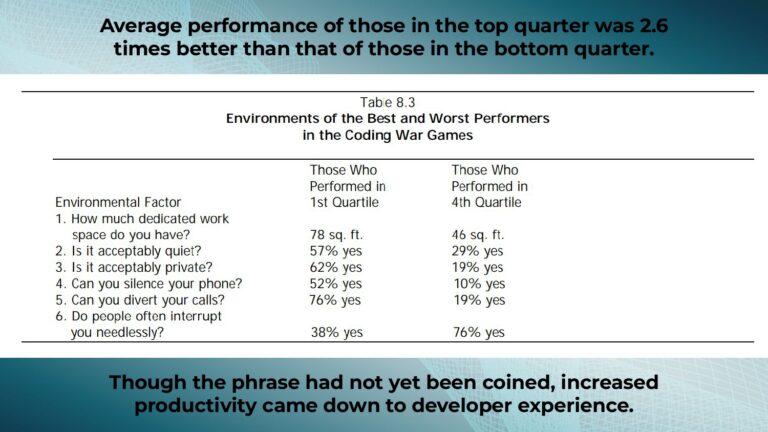
Like Bigfoot and the Loch Ness monster, the 10x developer is also a mythological creature: the concept emerged in the 1980s based on a survey of software teams that actually revealed the characteristics of 10x organizations, not individual developers.
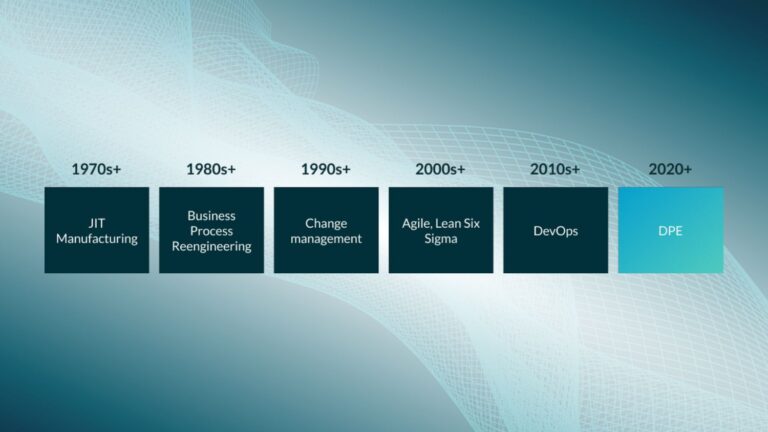
Since then, software practices like Lean, Agile, and DevOps have arisen to make software organizations more productive and aligned, but still fail to address many of today’s development bottlenecks–e.g. long build and test times, poor visibility into failures and flaky tests, etc. In this talk, Gradle describes the nascent evolution of DevOps into DPE, the problems that DPE solves, and how bringing productivity and joy back to coding can help us go beyond the 10x developer and build 10x organizations.
Justin Reock is the Field CTO and Chief Evangelist at Gradle Inc. Justin is an outspoken blogger, speaker, and free software advocate with over 20 years of experience working in various software roles. His focus is on delivering enterprise solutions, technical leadership, and community education on a range of topics.

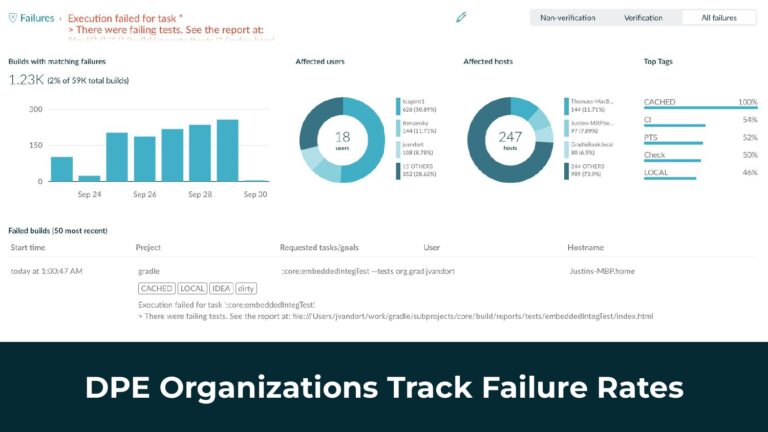
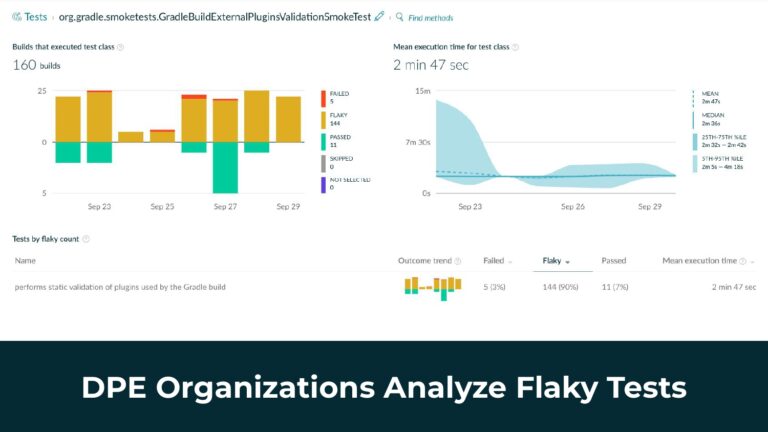
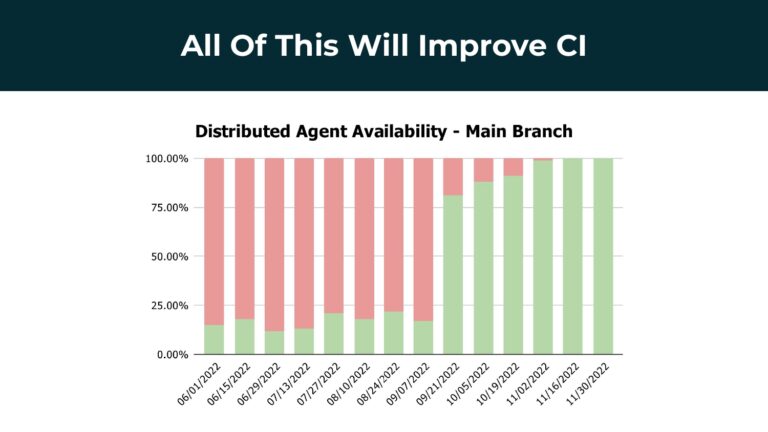
Gradle Enterprise customers utilize Gradle Enterprise Build Scan™ to rapidly get deep insights into various DPE-based metrics, like build and test performance, flaky tests, dependencies, failures and regressions. From there, features like Build Cache reduce build and test times by avoiding re-running code that hasn’t changed since the last successful build, and Test Distribution further improves test times (often 90% of the entire build process) by parallelizing tests across all available infrastructure. You can learn more about these features by running a free Build Scan™ for Maven and Gradle Build Tool, watching videos, and registering for our free instructor-led Build Cache deep-dive training.