

What’s inside?
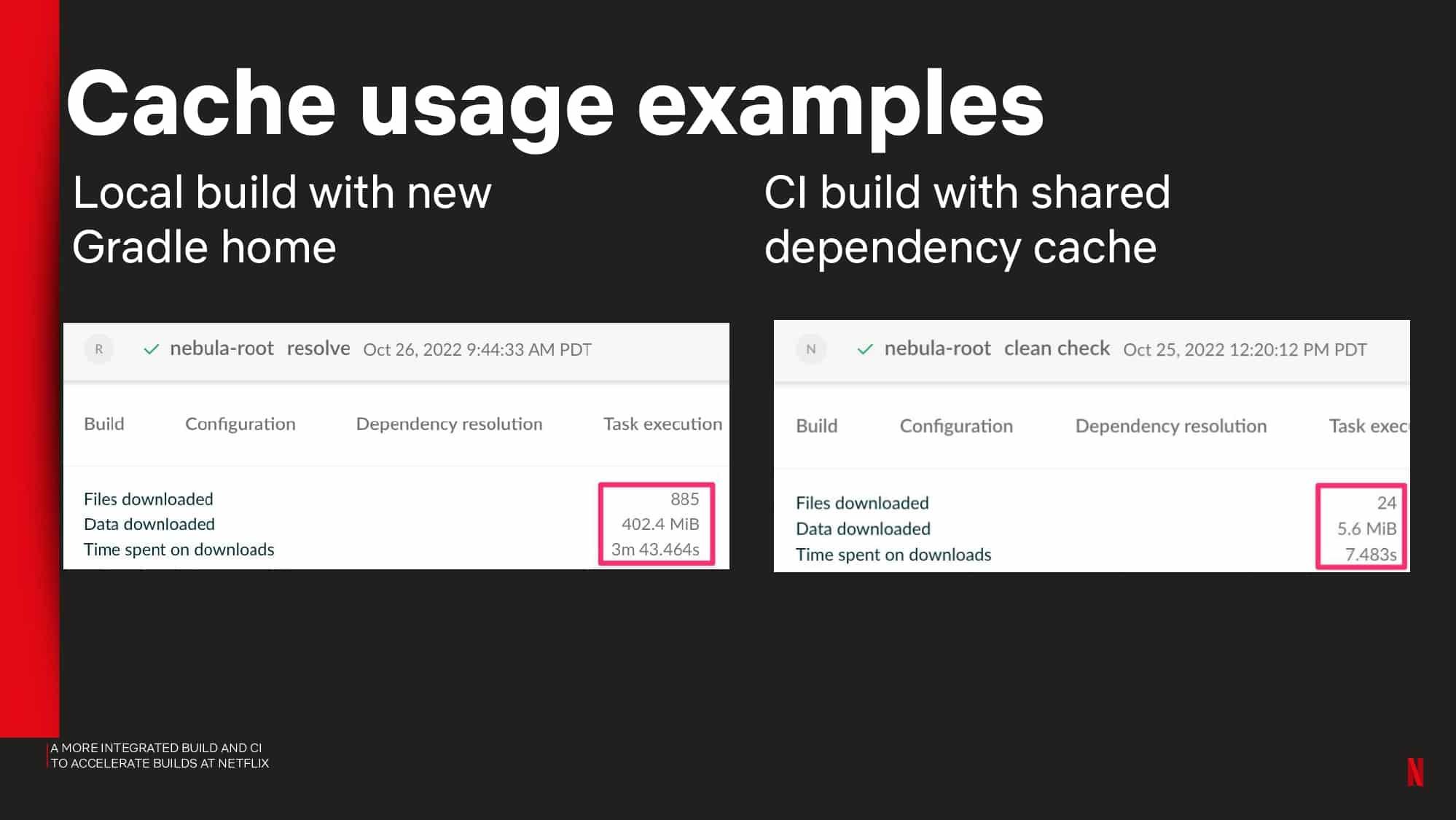
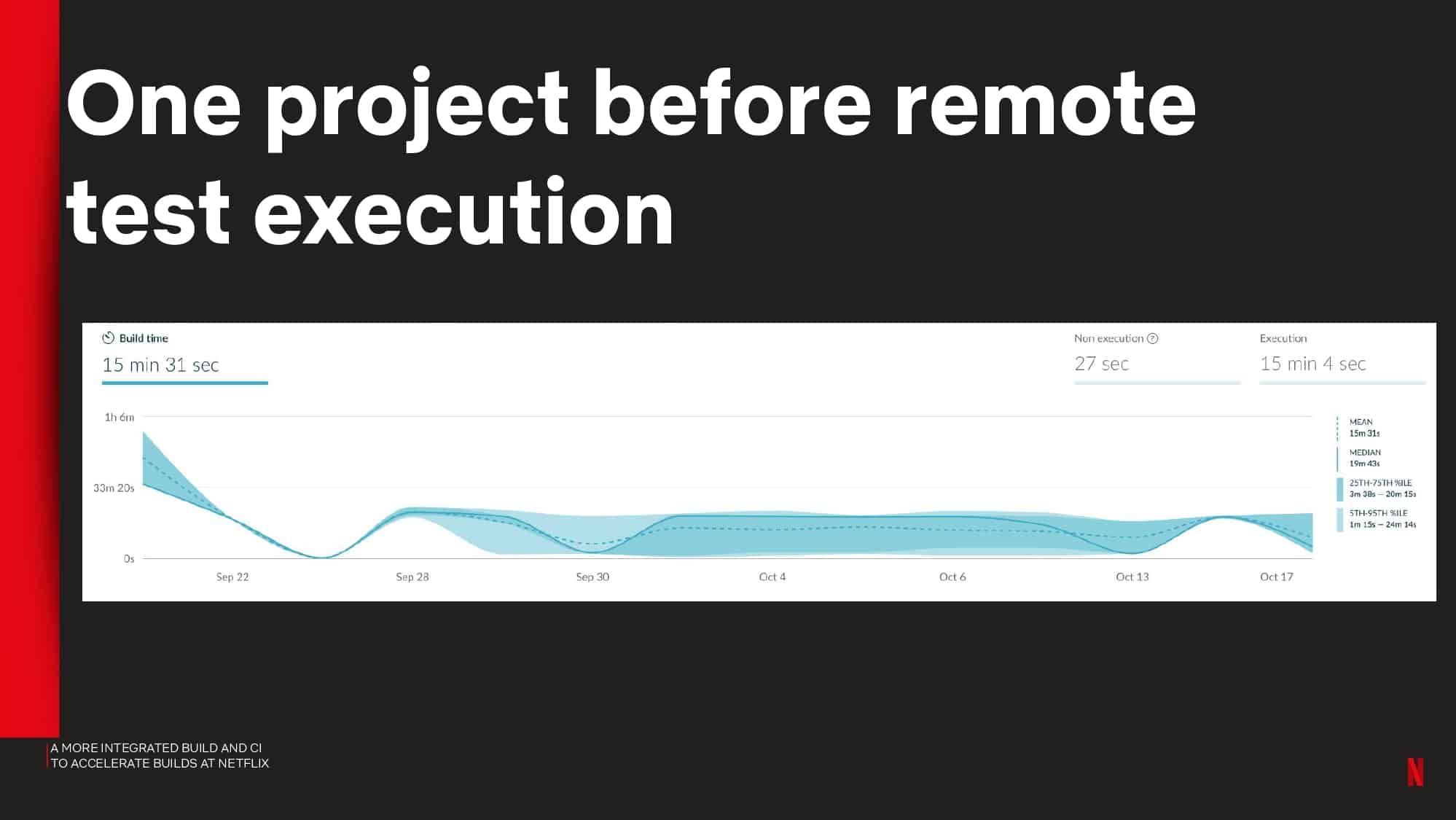
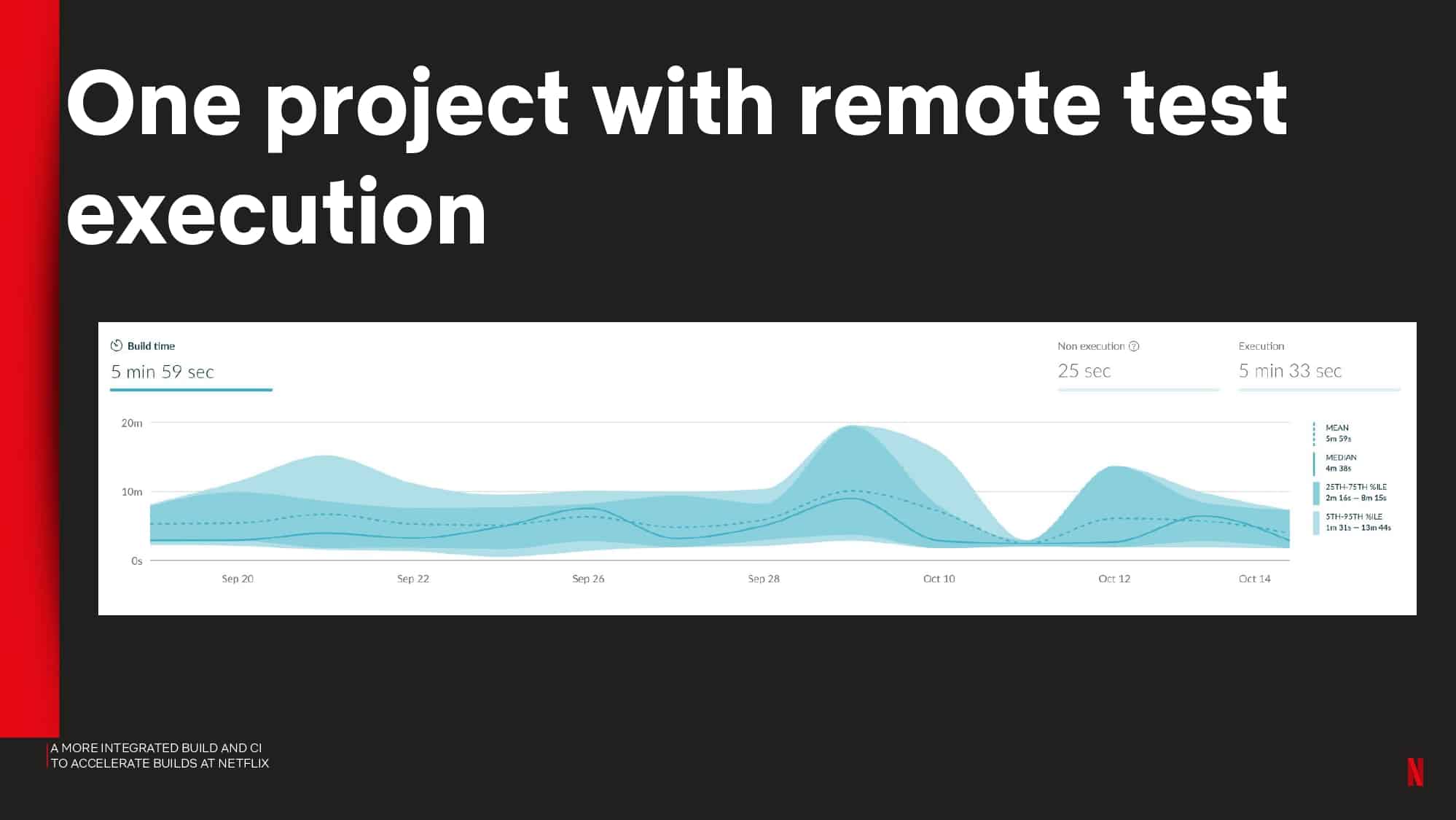
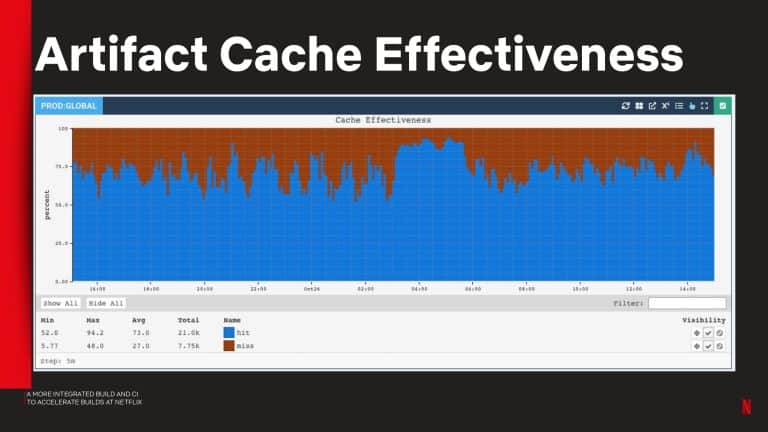
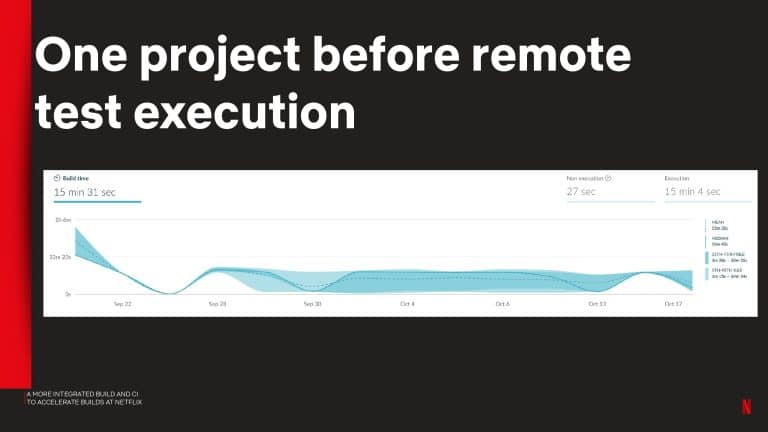
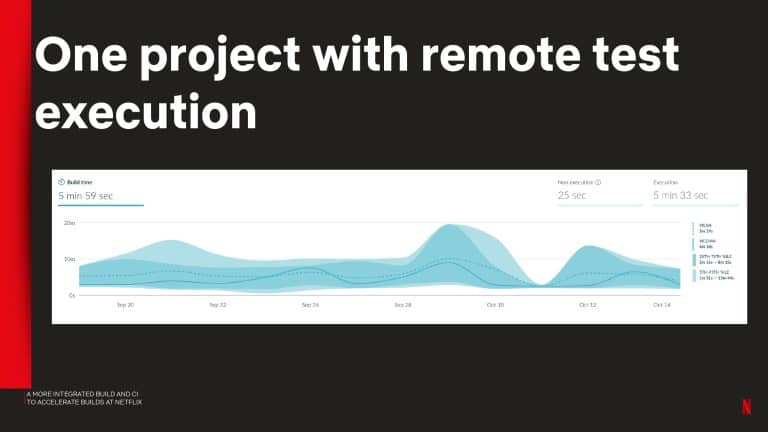
Netflix shares observability metrics they captured to identify common problems with the local and CI tool experience. They also share how remote test execution reduced PR build times down from 50 to 5 min.
Netflix shares observability metrics they captured to identify common problems with the local and CI tool experience. They also share how remote test execution reduced PR build times down from 50 to 5 min.
Summit Producer’s Highlight
Find out why the Netflix DevProd organization focuses on optimizing the local development loop and finding ways to minimize unproductive wait time. Points of discussion include:
Find out why the Netflix DevProd organization focuses on optimizing the local development loop and finding ways to minimize unproductive wait time. Points of discussion include:
- Common problems with long local development loops
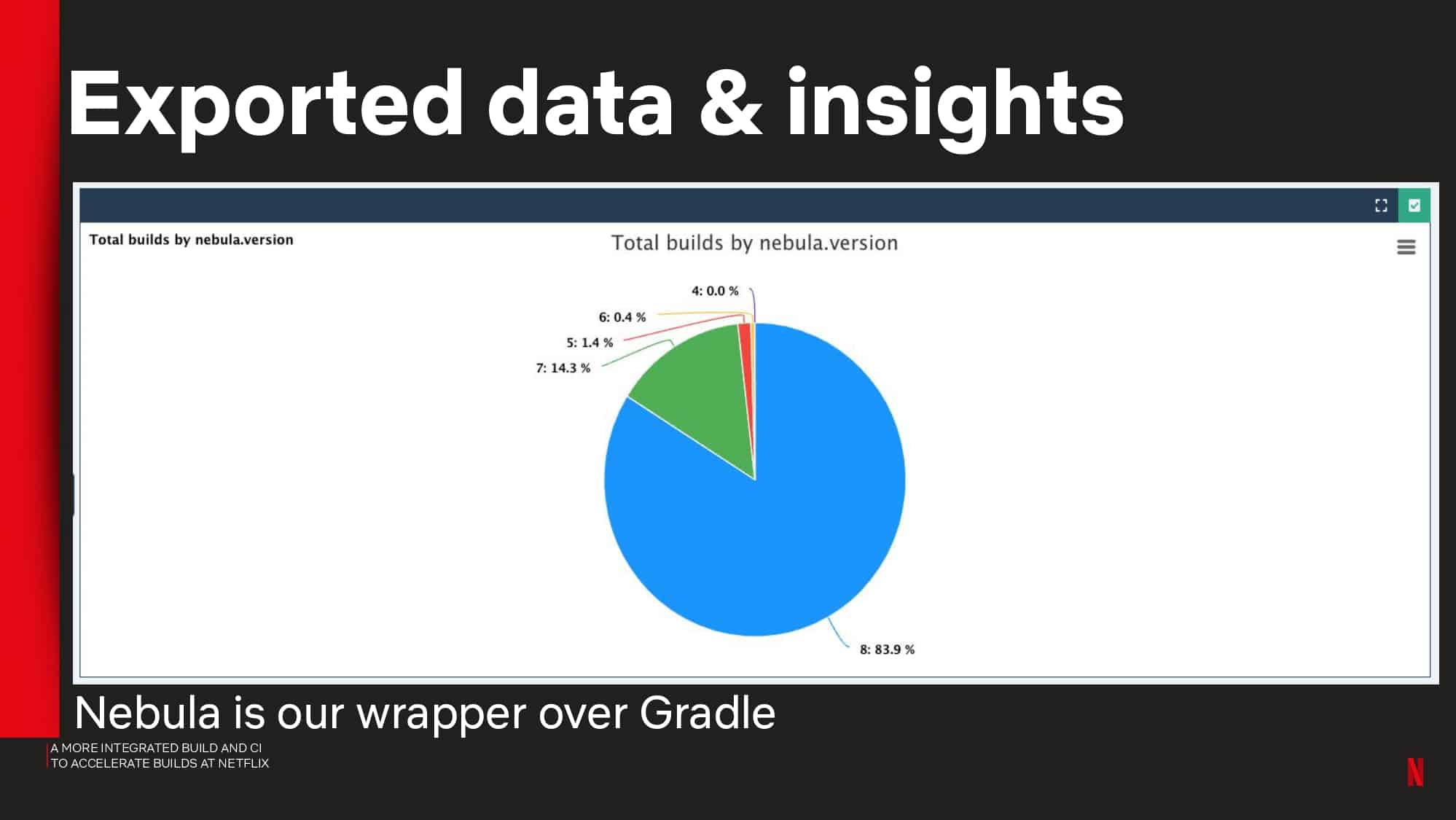
- Improving self serviceability and the build performance and consistency experience
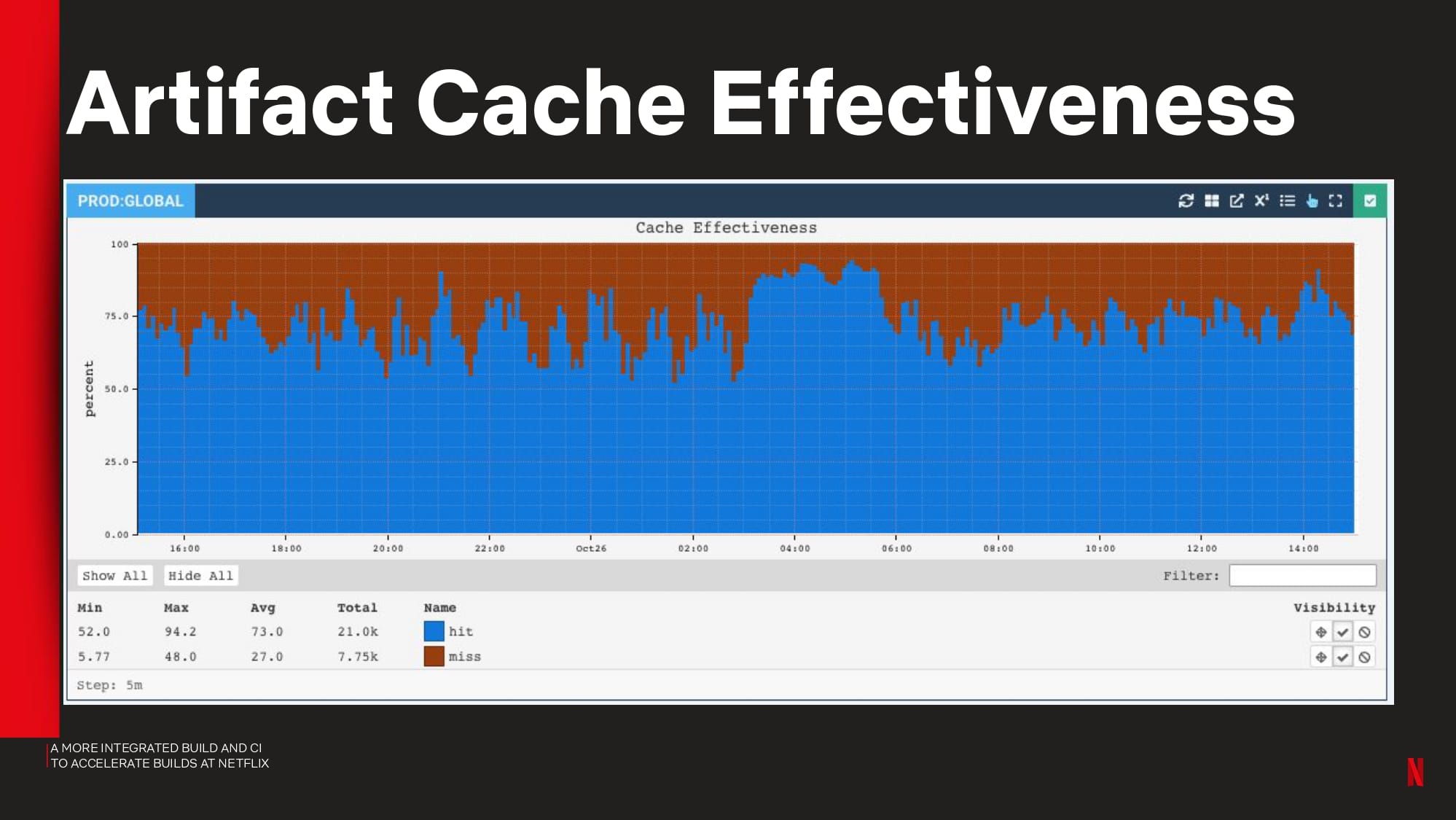
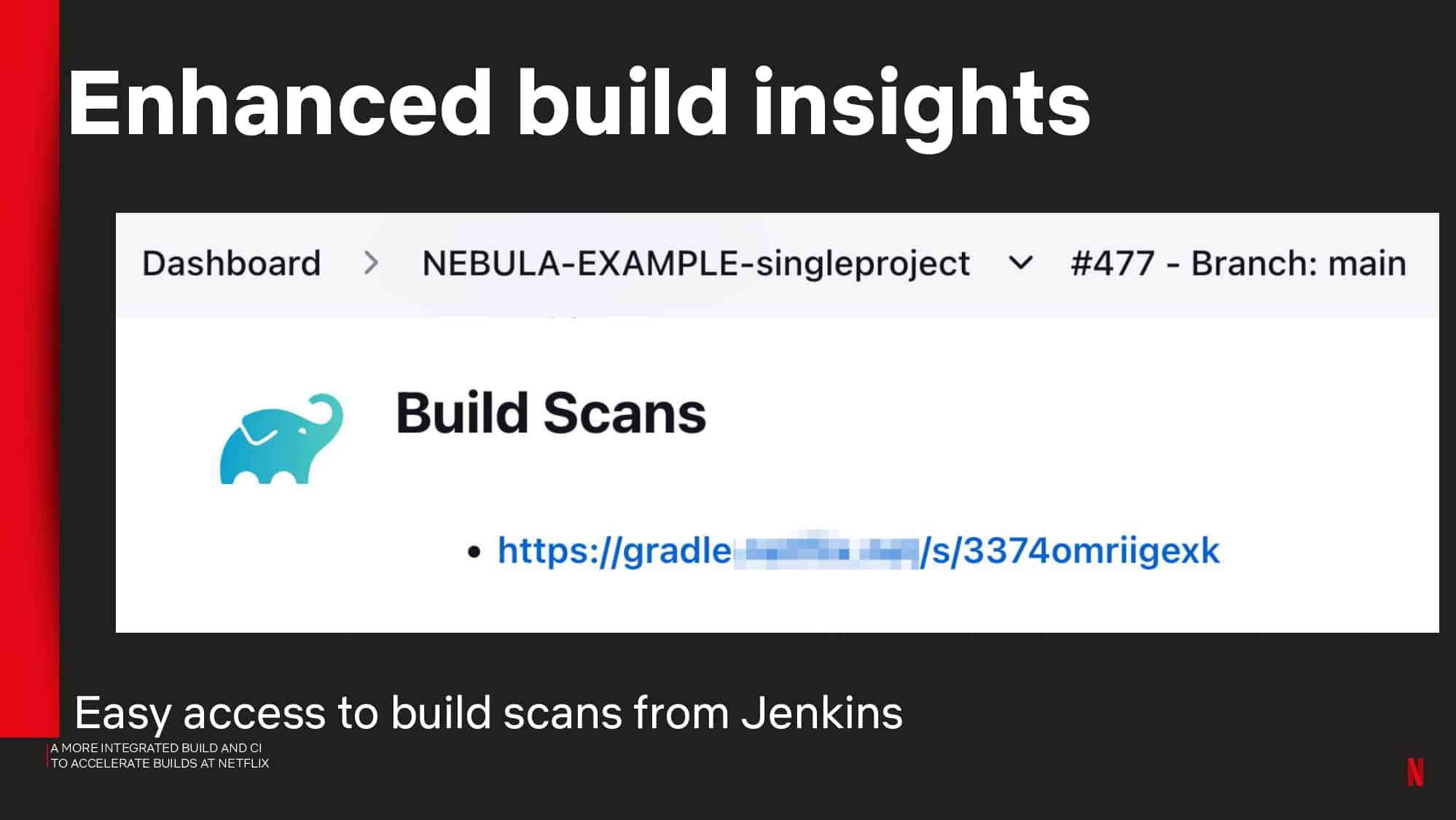
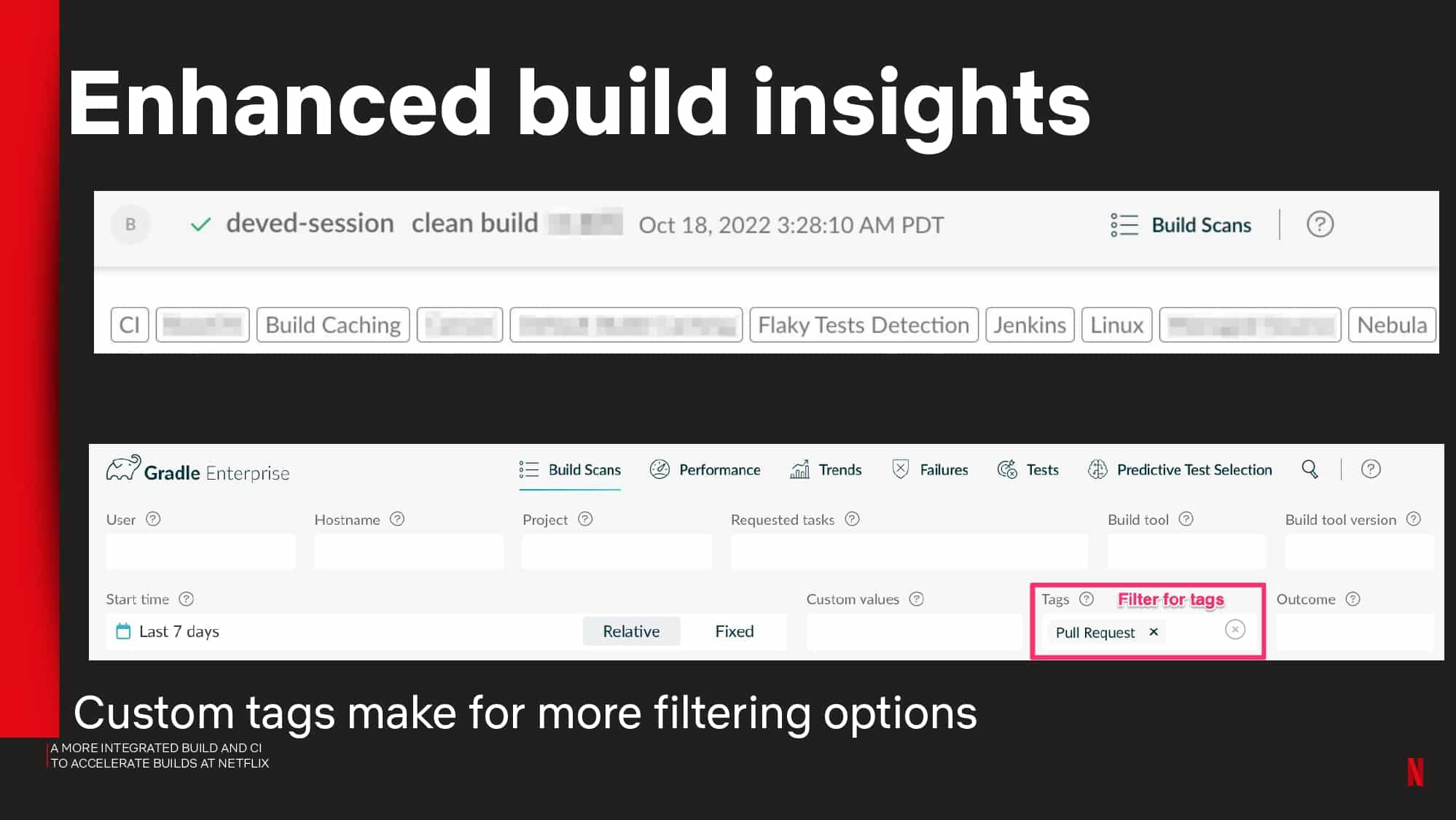
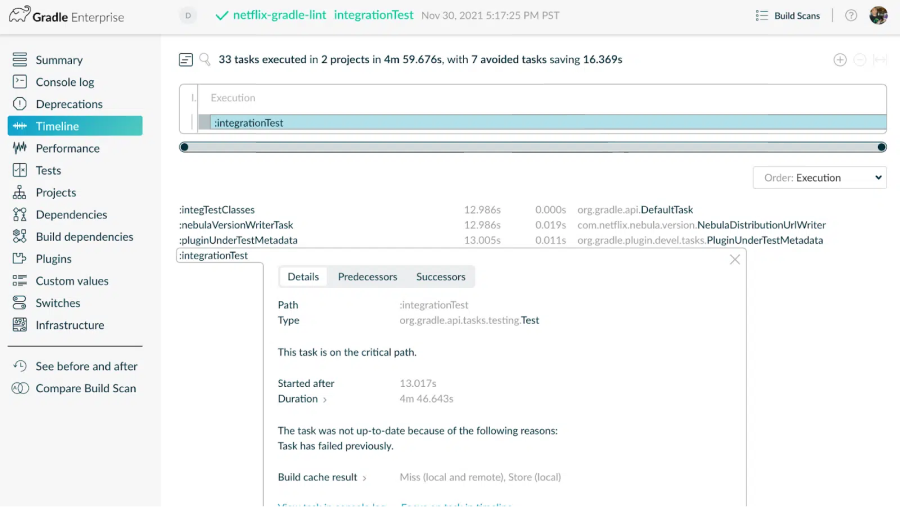
- CI observability and insights using tools like Gradle Build Scan™
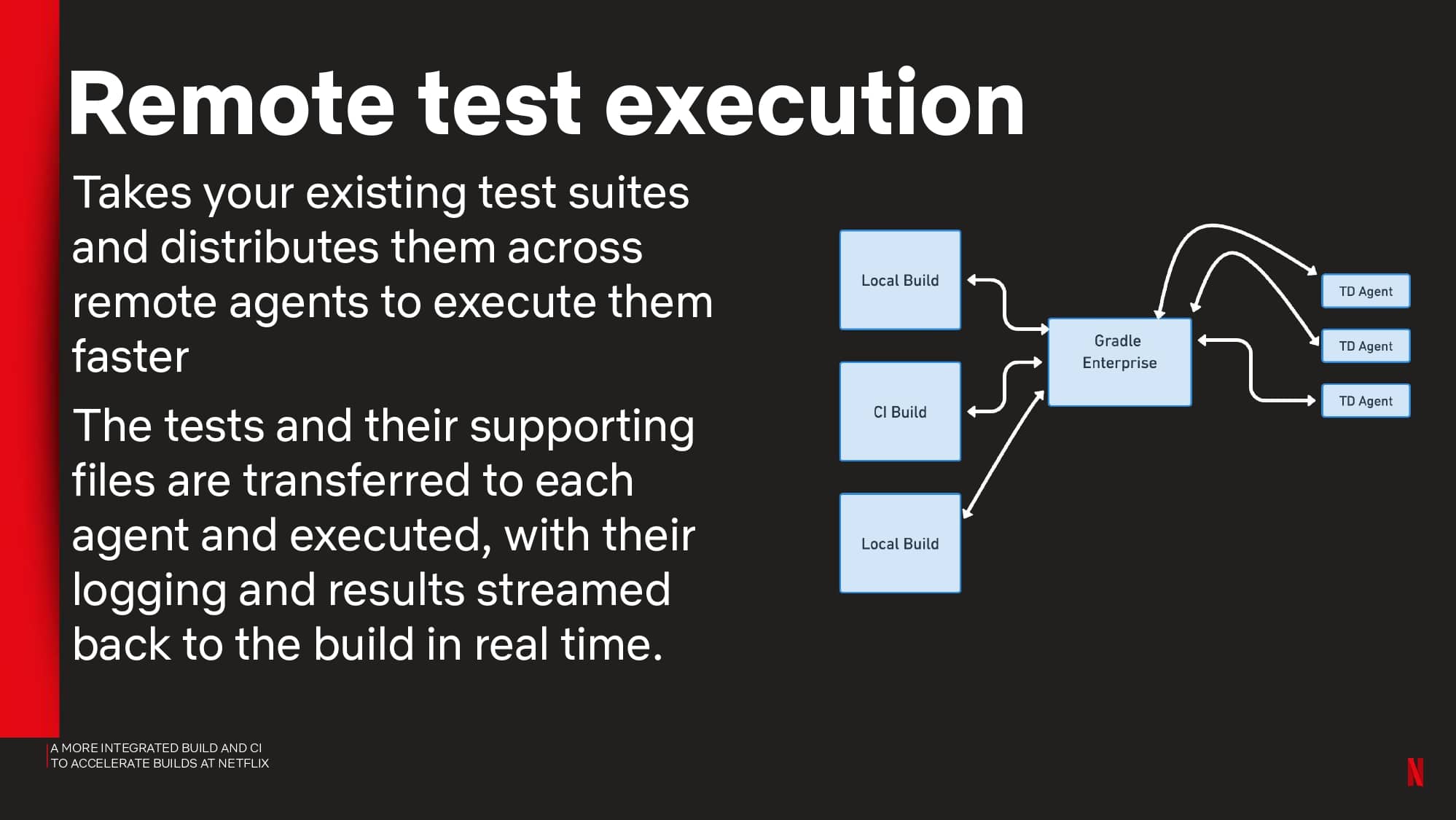
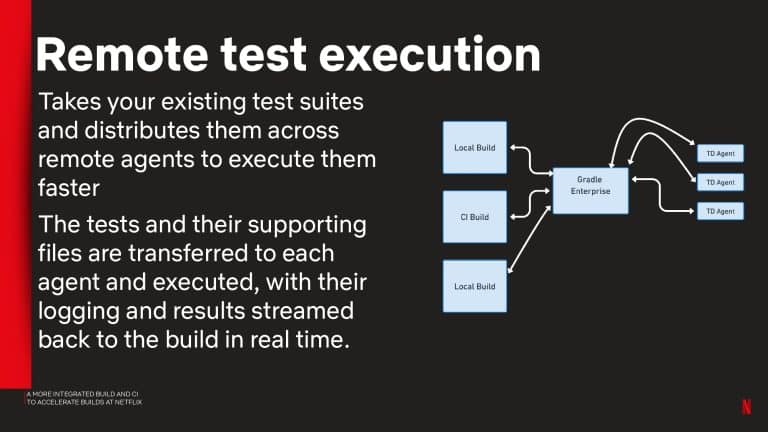
- Pipeline acceleration using remote test execution with Gradle Enterprise Test Distribution
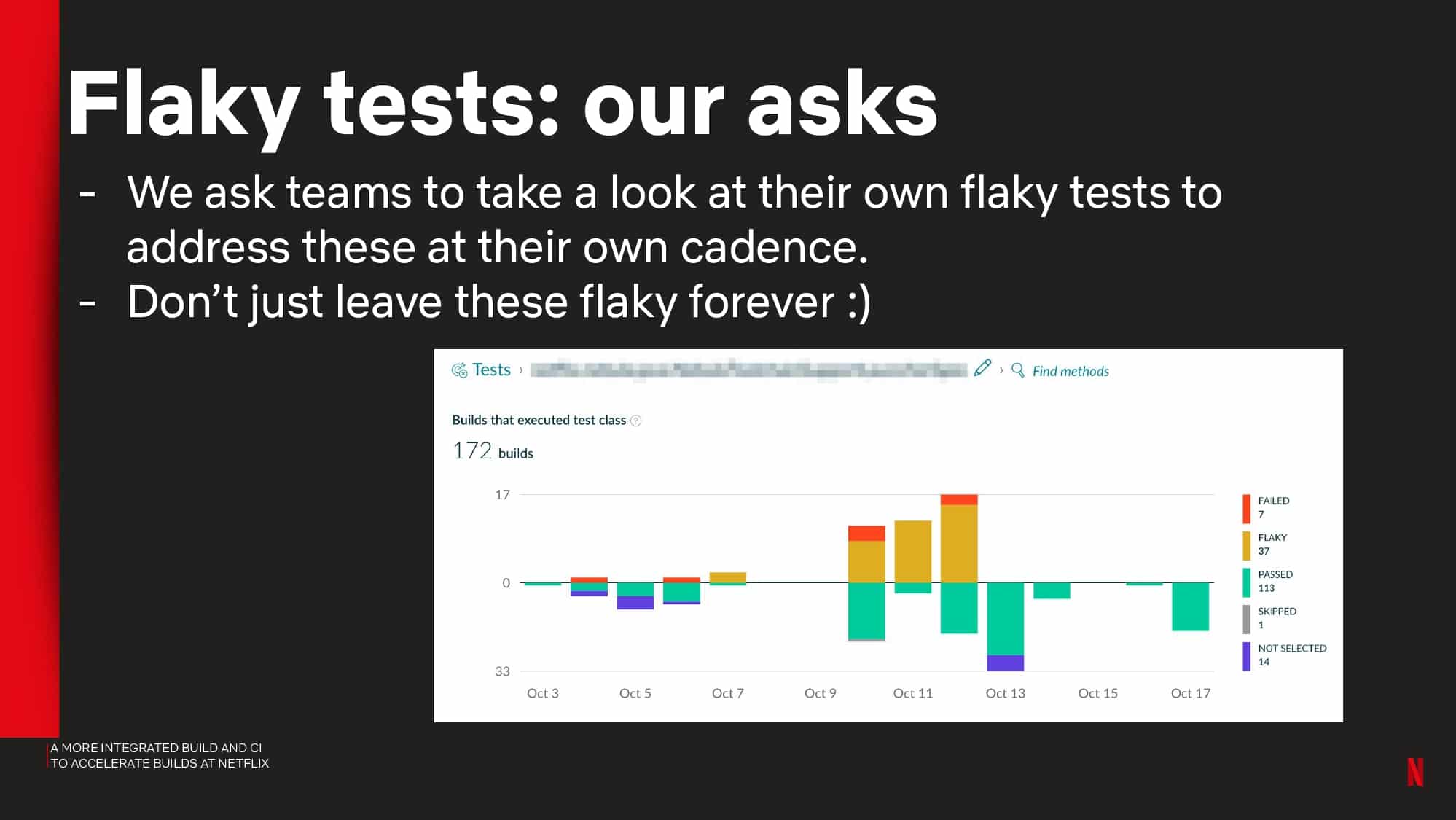
- Flaky test detection and other avoidable failures using test and failure analytics
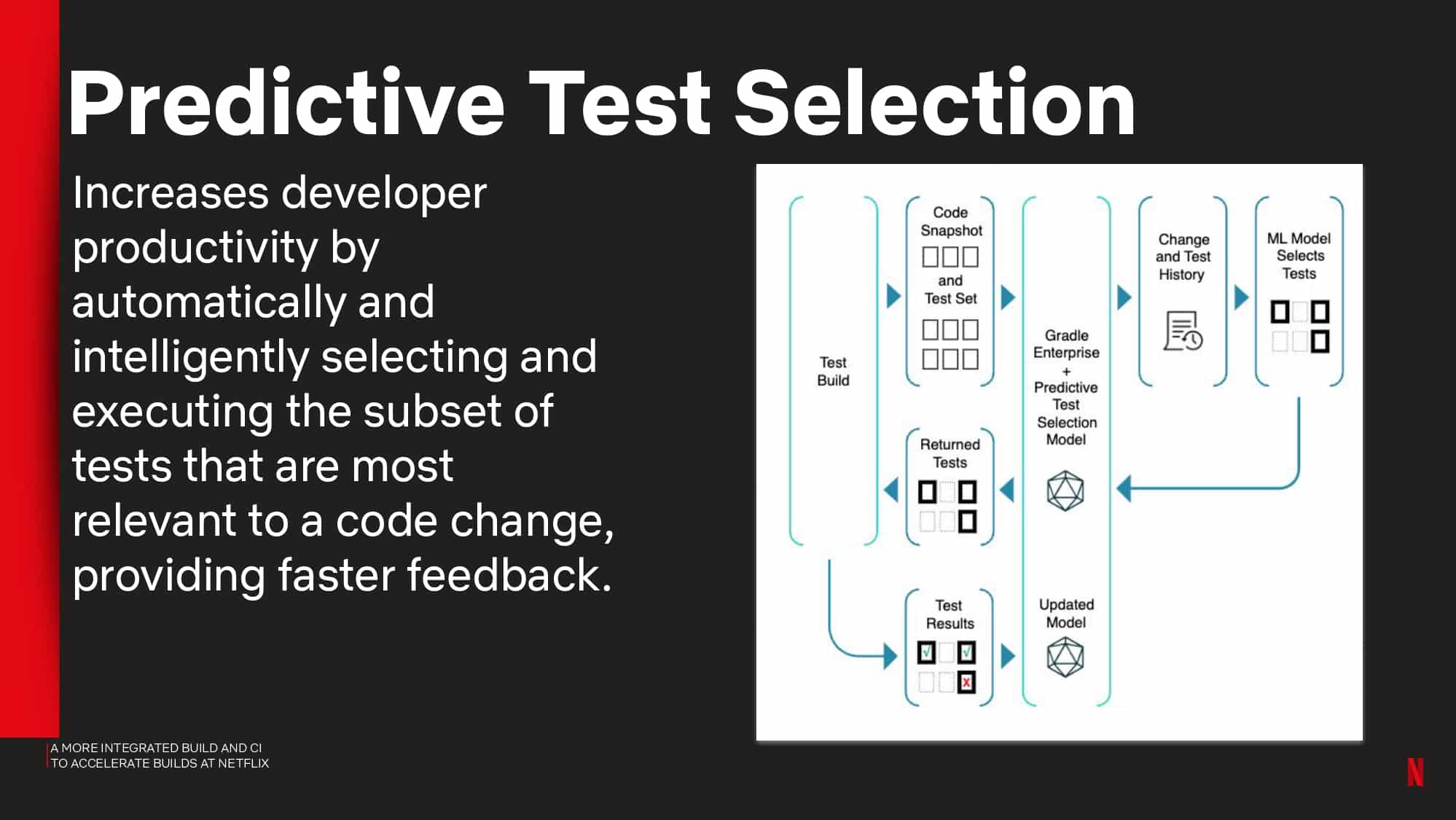
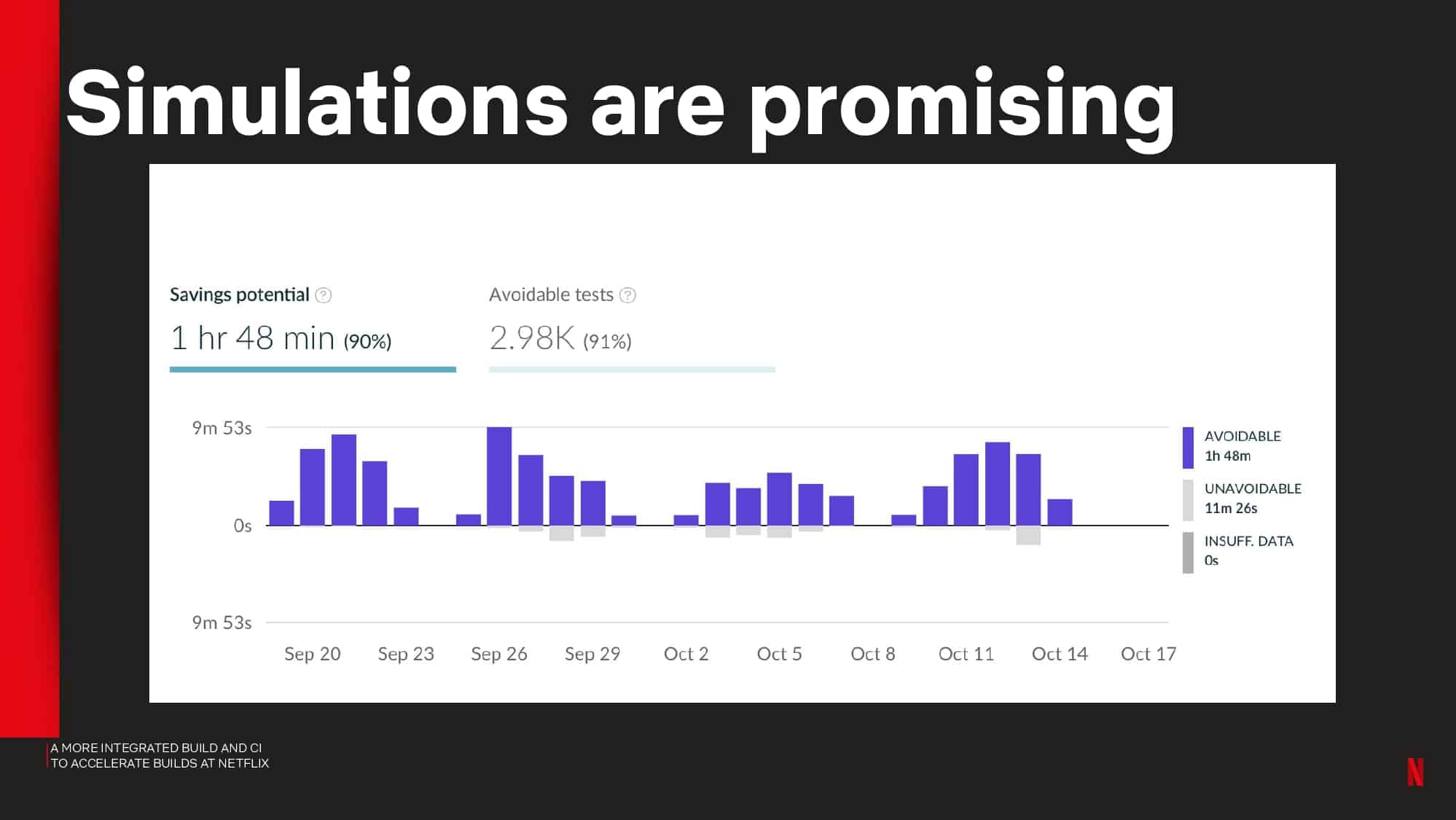
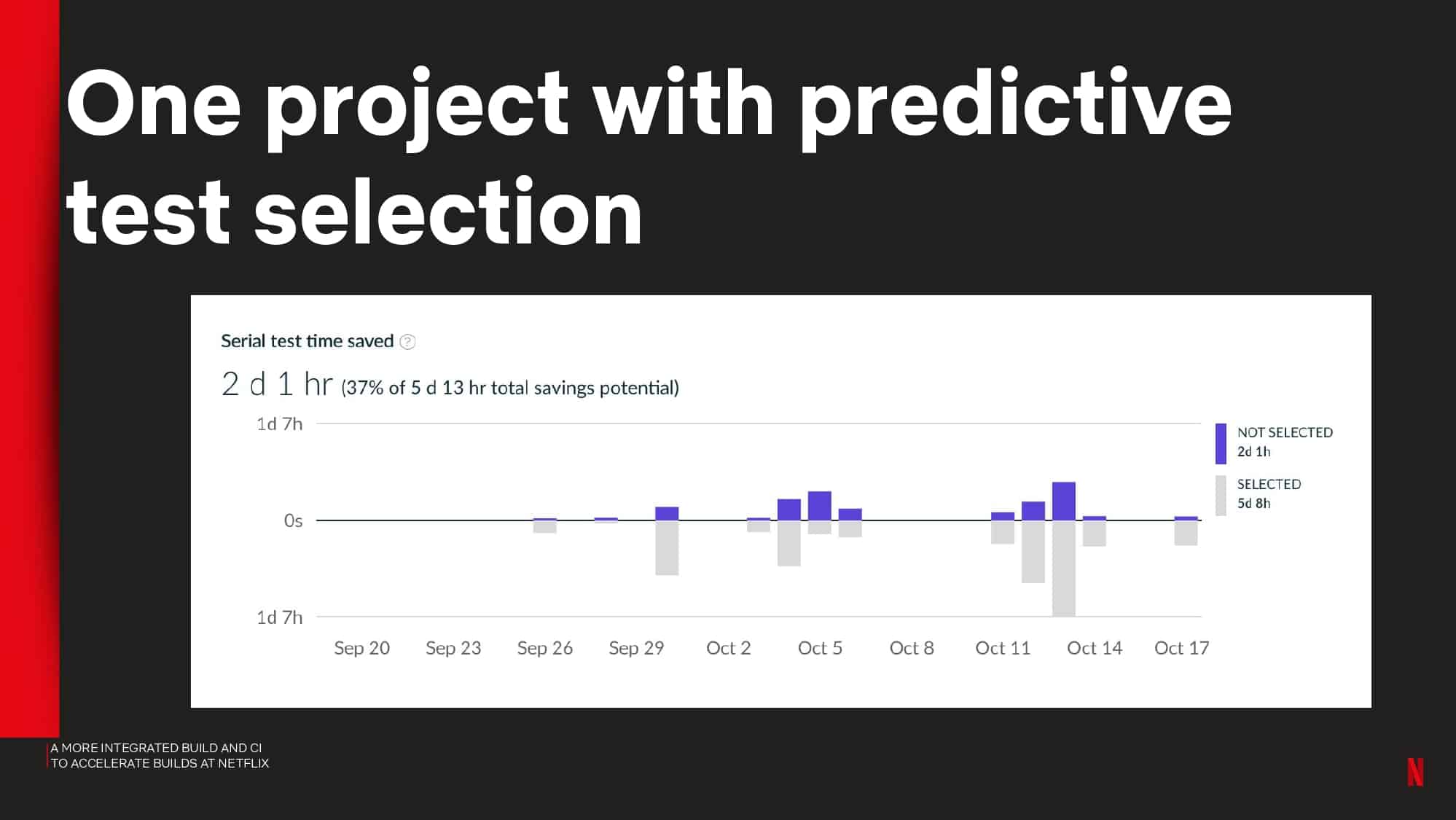
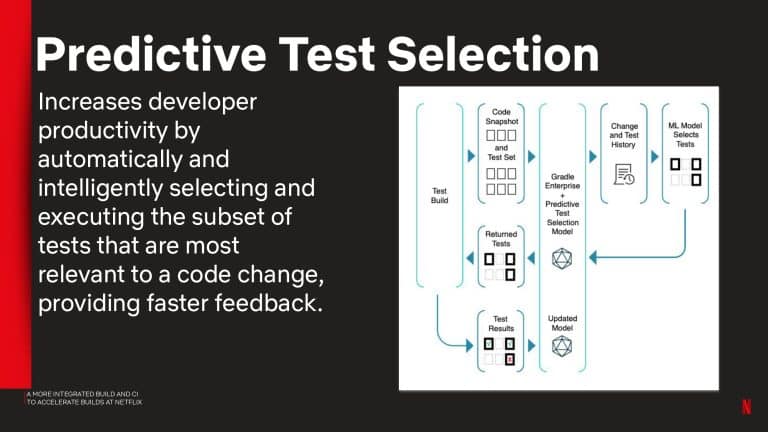
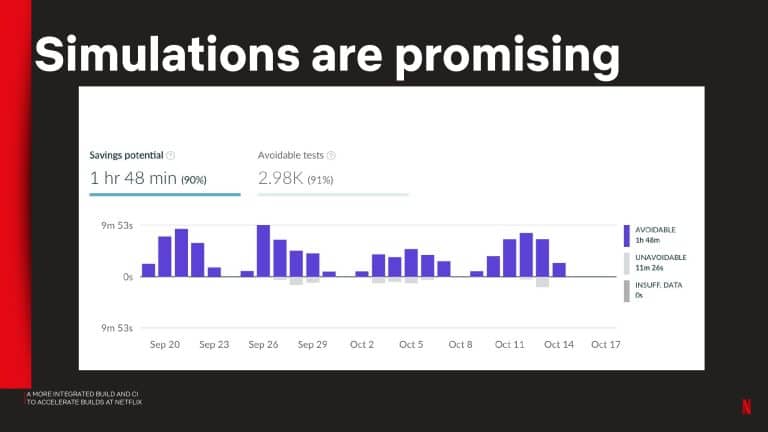
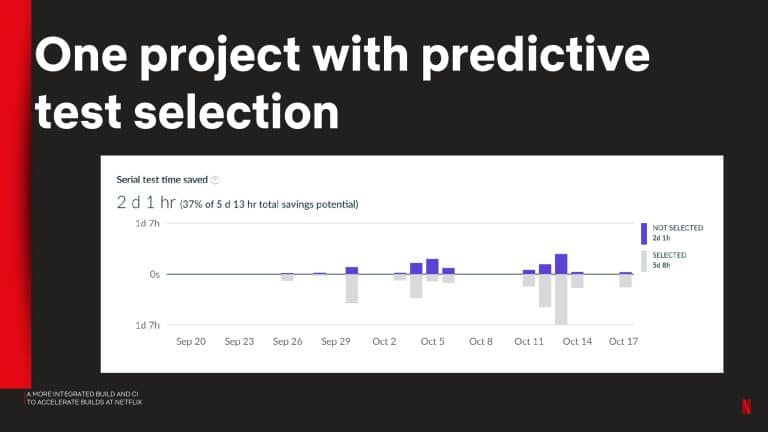
- Using the Predictive Test Selection simulation capability to estimate test feedback cycle-time savings
About Aubrey
Aubrey Chipman loves to work on developer tooling/developer experience. She loves being part of a team where they can grow, support, and elevate each other to help others. She has a passion for development work and the associated coaching, influencing, and generally making ecosystems better
Aubrey Chipman loves to work on developer tooling/developer experience. She loves being part of a team where they can grow, support, and elevate each other to help others. She has a passion for development work and the associated coaching, influencing, and generally making ecosystems better
About Roberto
Roberto Perez Alcolea is an experienced software engineer focused on microservices, cloud, developer productivity and continuous delivery. He’s a self-motivated, success-driven, and detail-oriented professional interested in solving unique and challenging problems.
Roberto Perez Alcolea is an experienced software engineer focused on microservices, cloud, developer productivity and continuous delivery. He’s a self-motivated, success-driven, and detail-oriented professional interested in solving unique and challenging problems.
More information related to this topic
Gradle Enterprise
Solutions for CI
Observability and Build Optimization

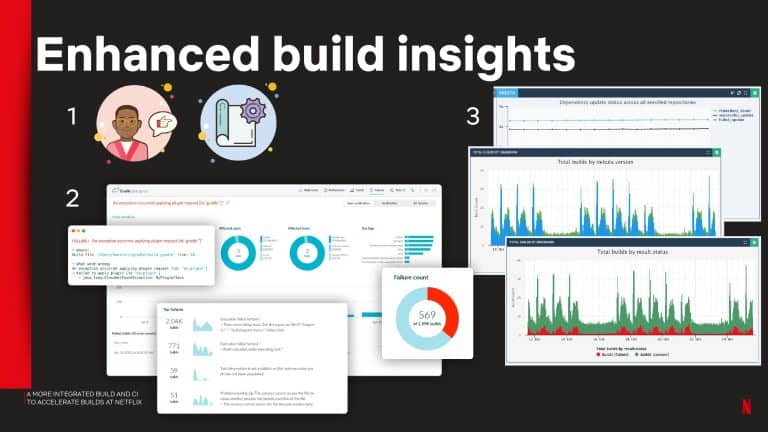
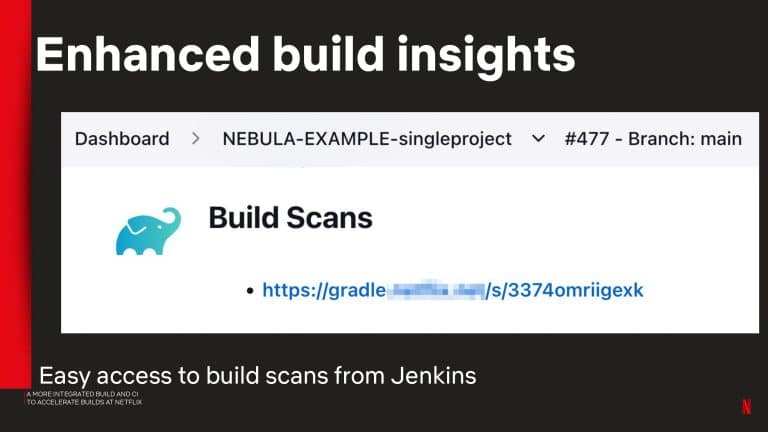
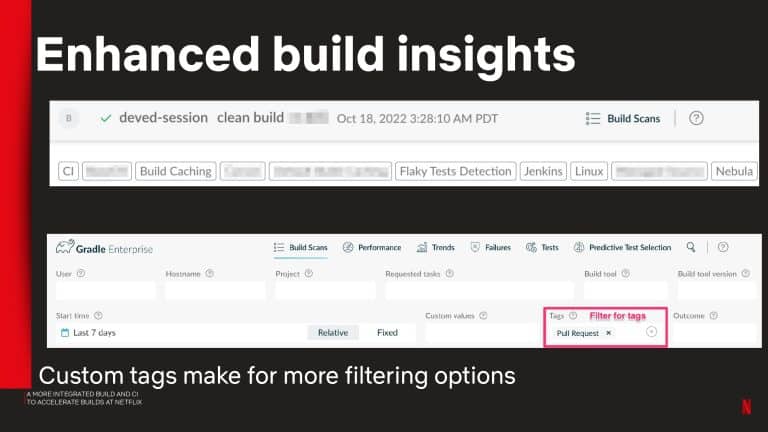
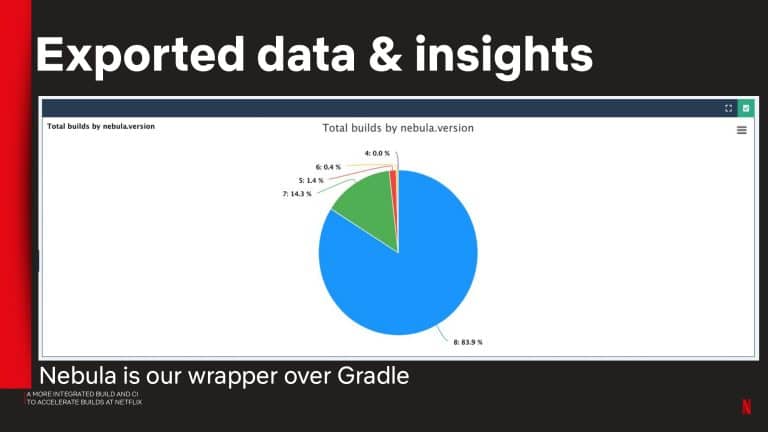
Gradle Enterprise build and test acceleration technologies address the pain of unnecessary developer idle time waiting for builds and tests to complete. Build Scan gives you granular analytic information for every build, so you can quickly fix problems and debug performance issues. Test and Failure Analytics leverages historical data to proactively find unreliable builds and flaky tests, report on the people and environments affected by the problem, and guide teams to the root cause efficiently.
Slides




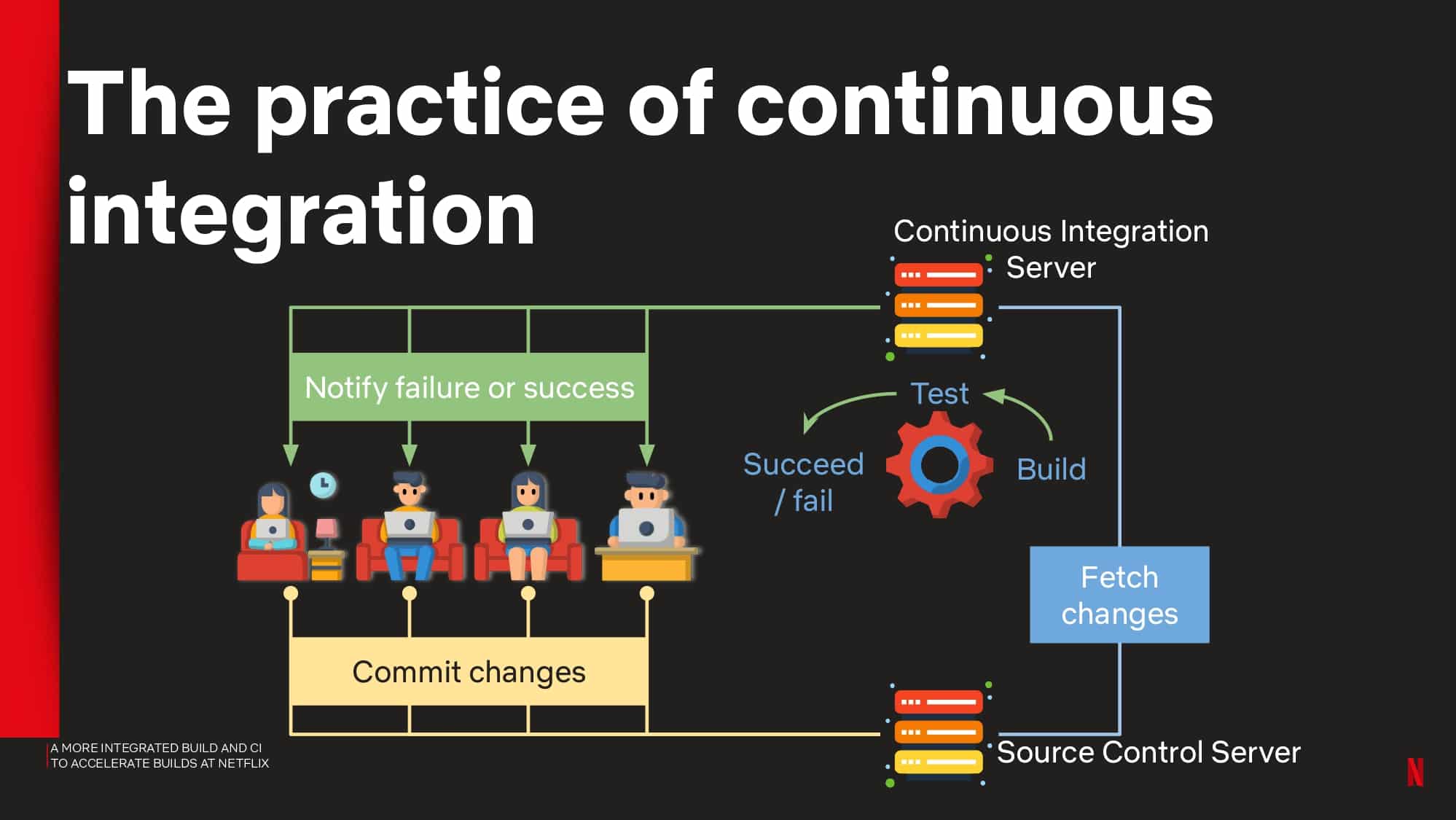









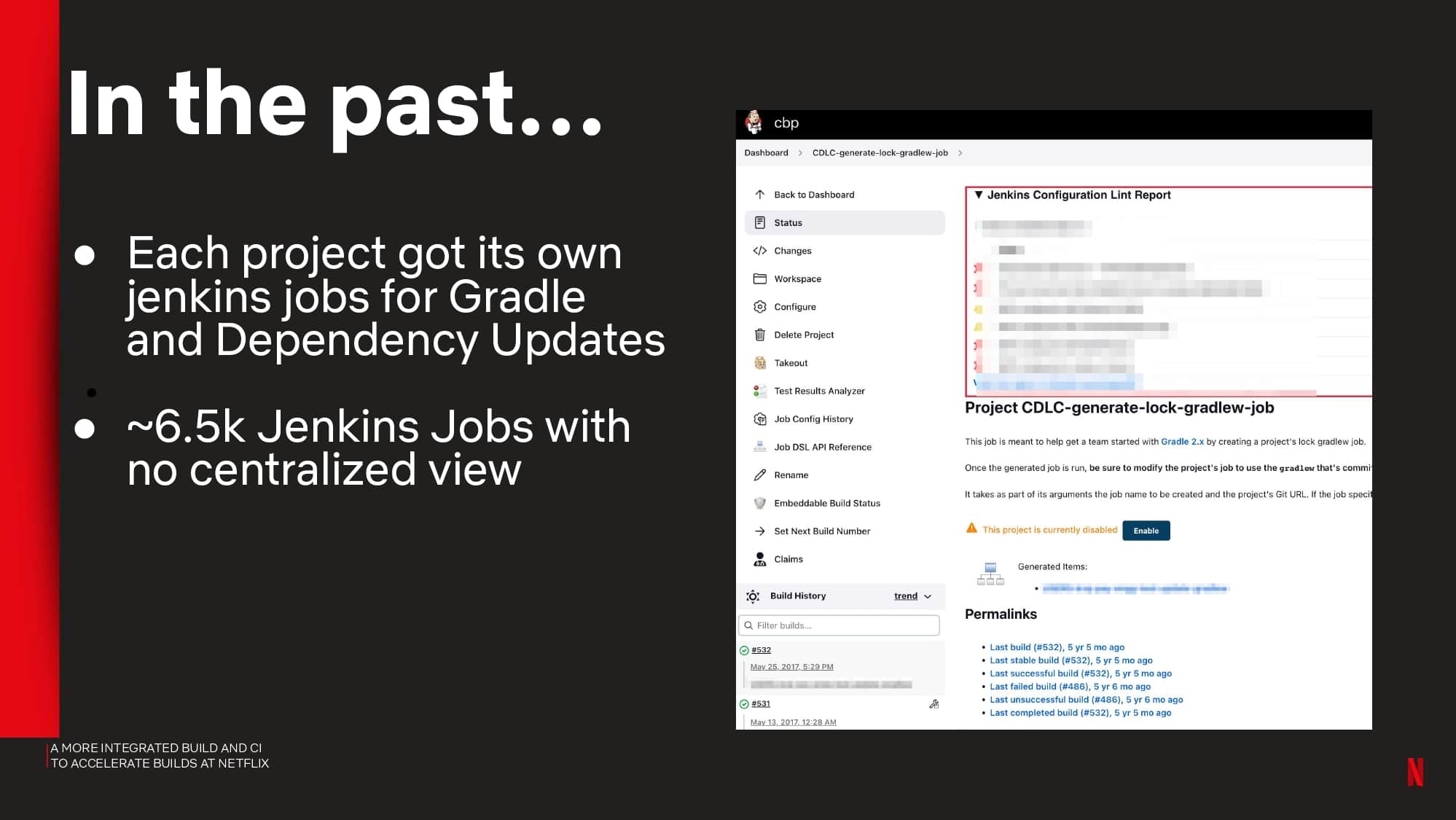
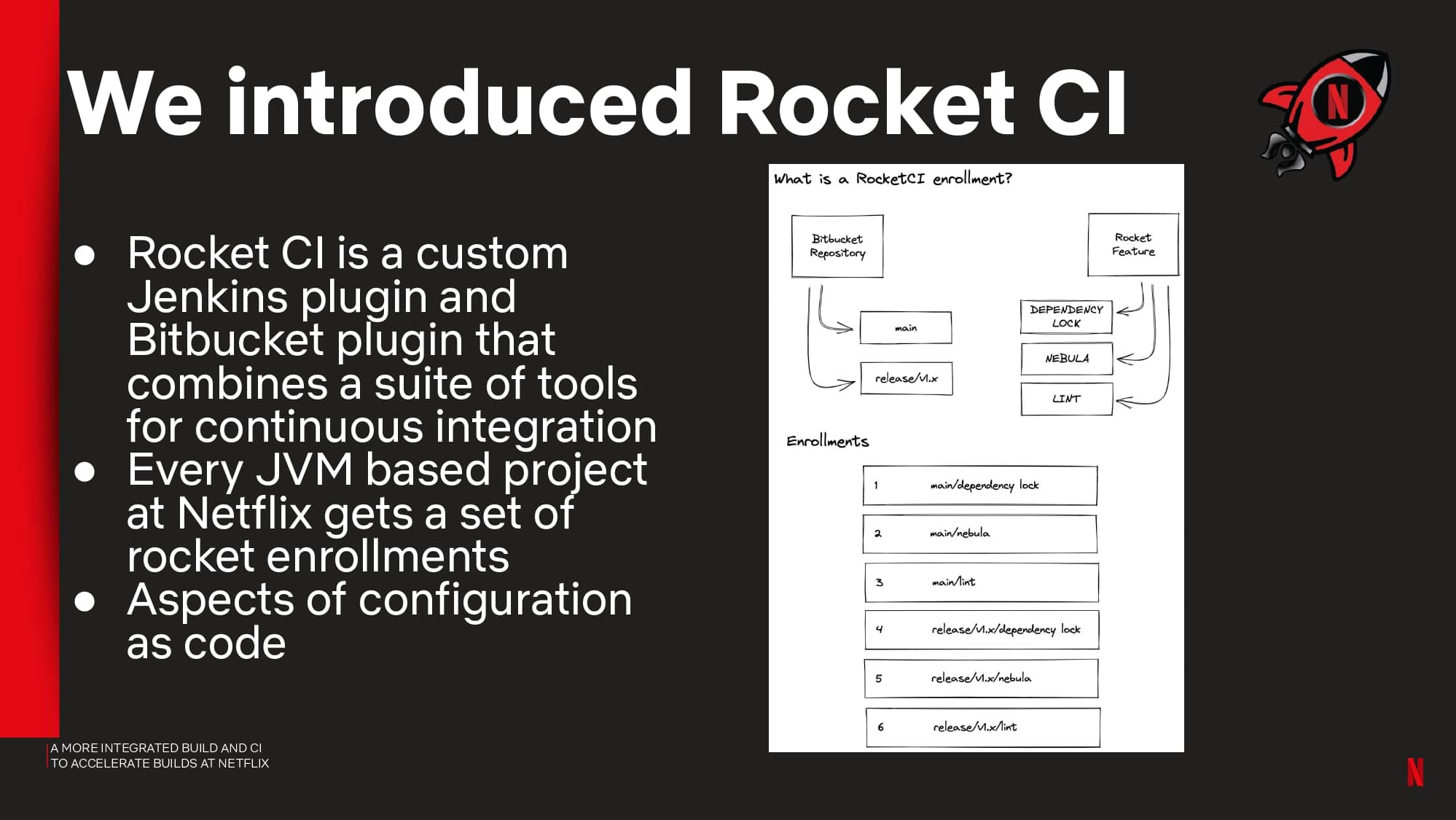
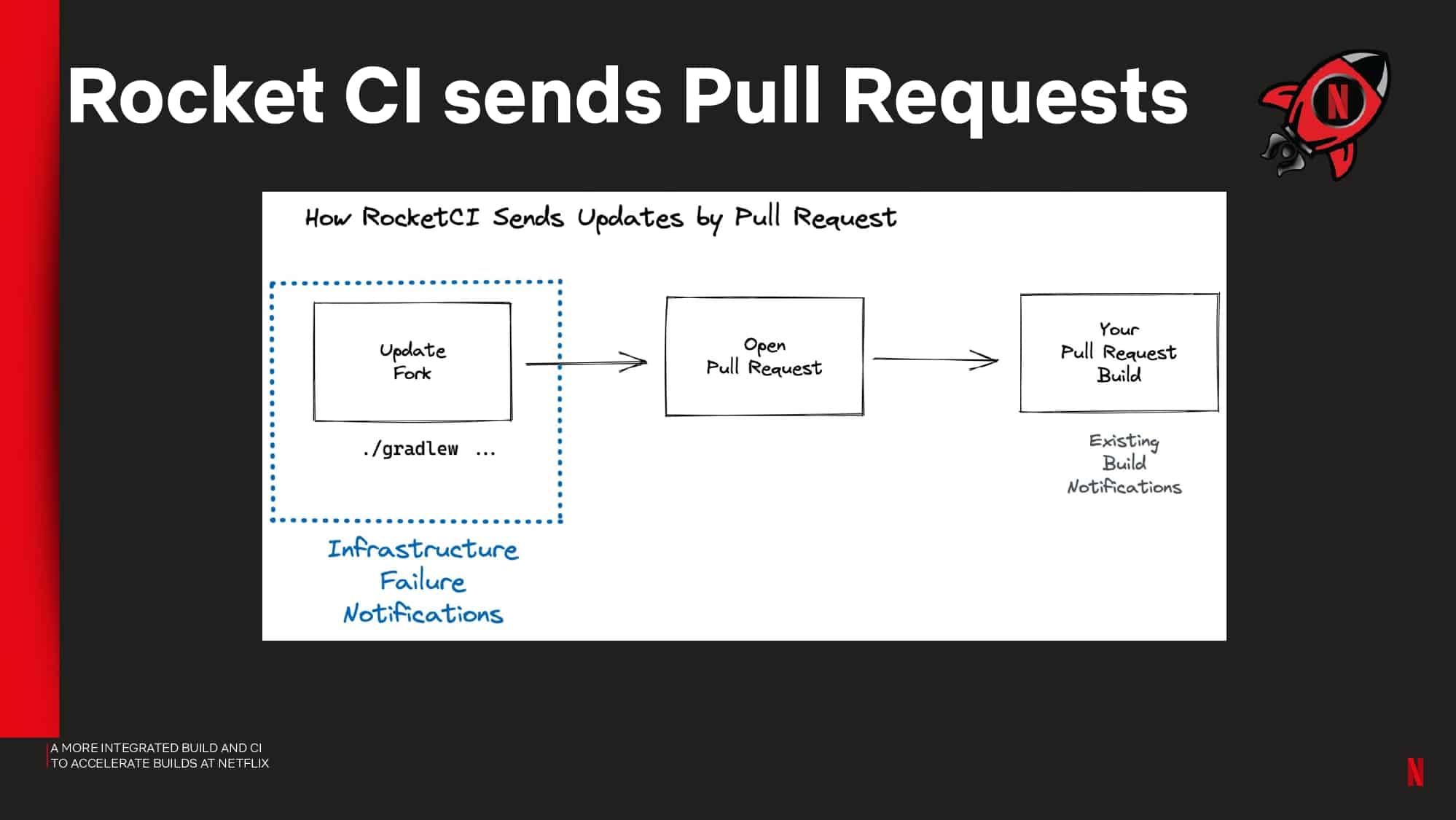
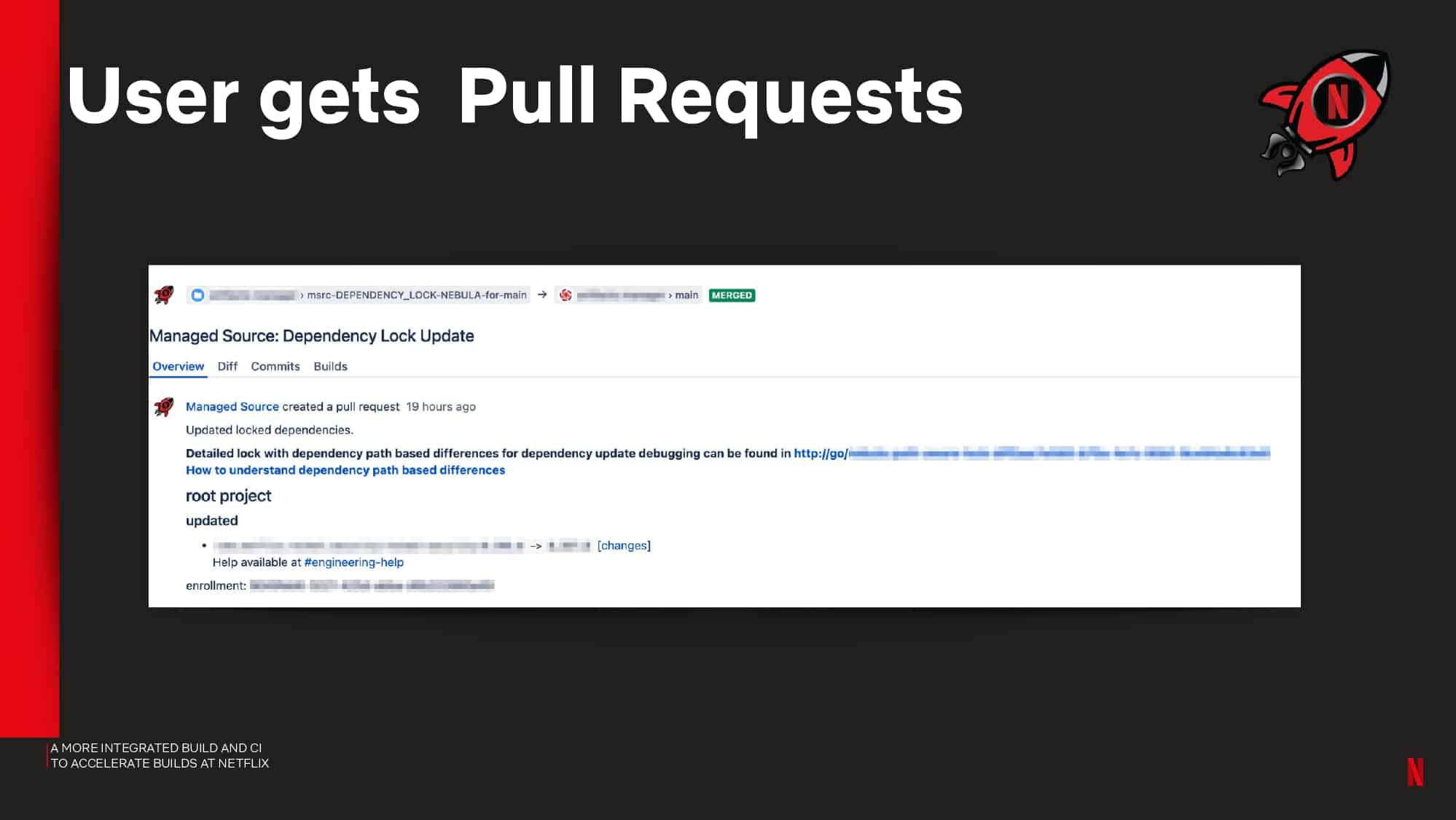
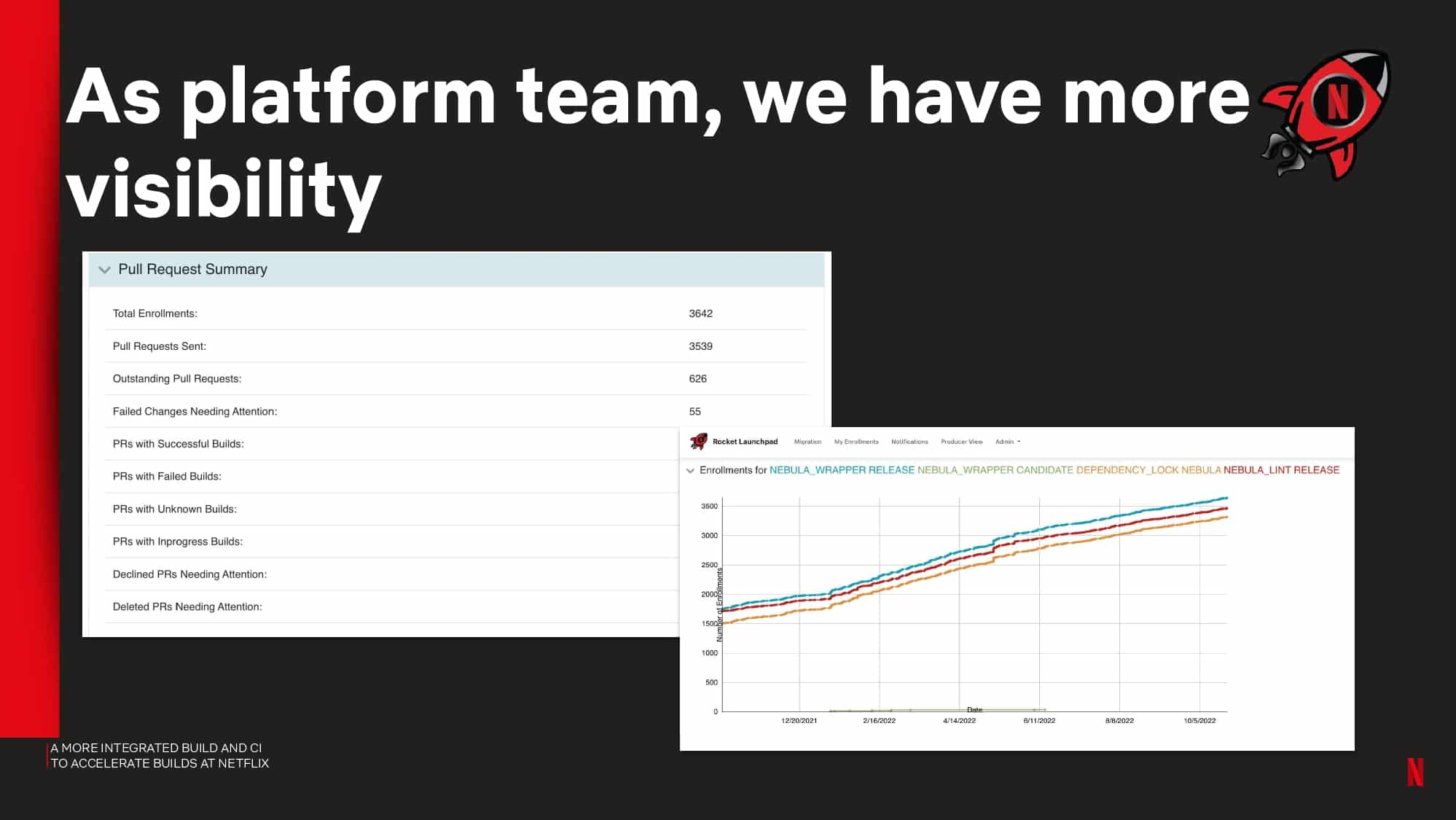

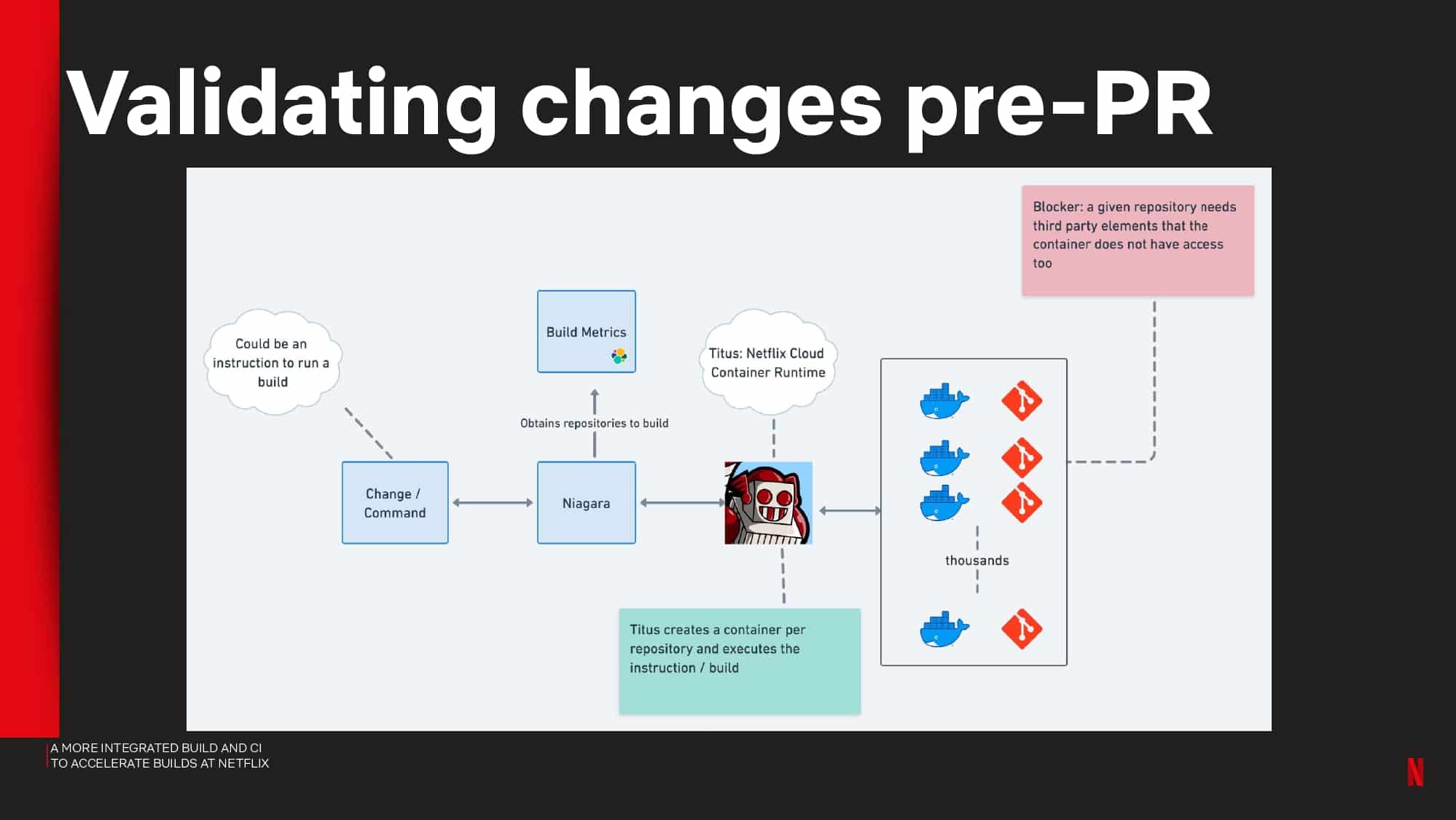


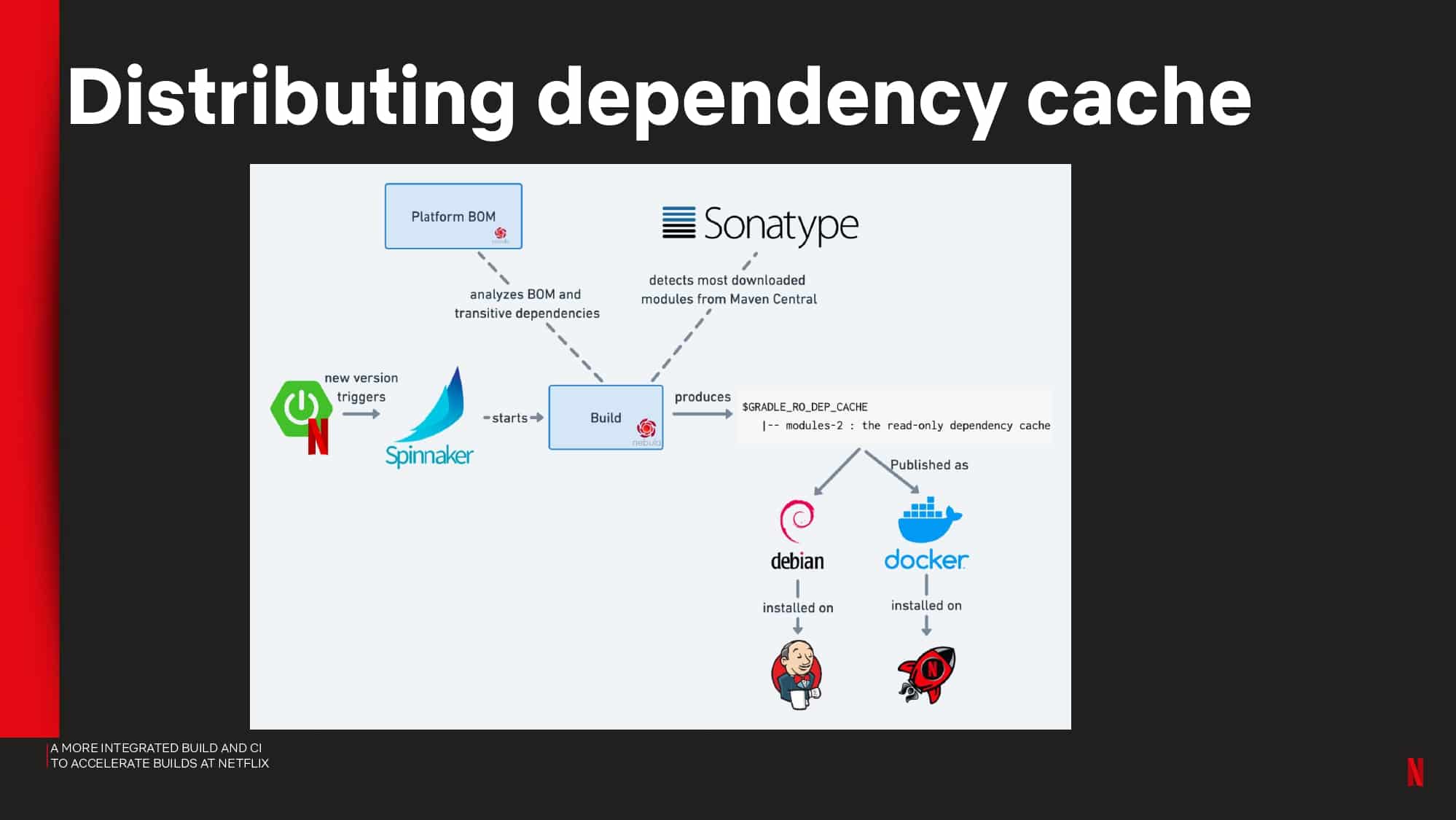








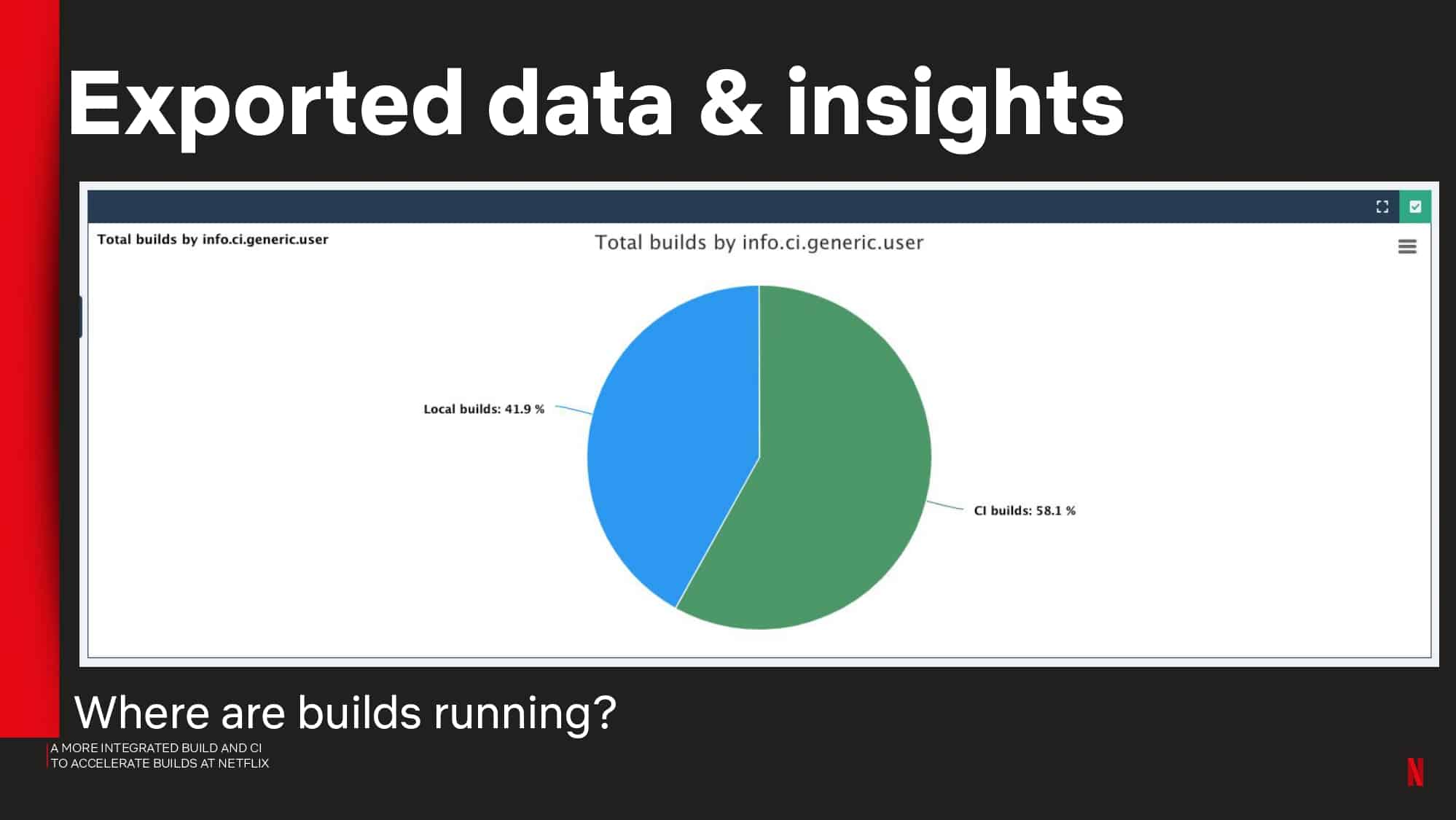
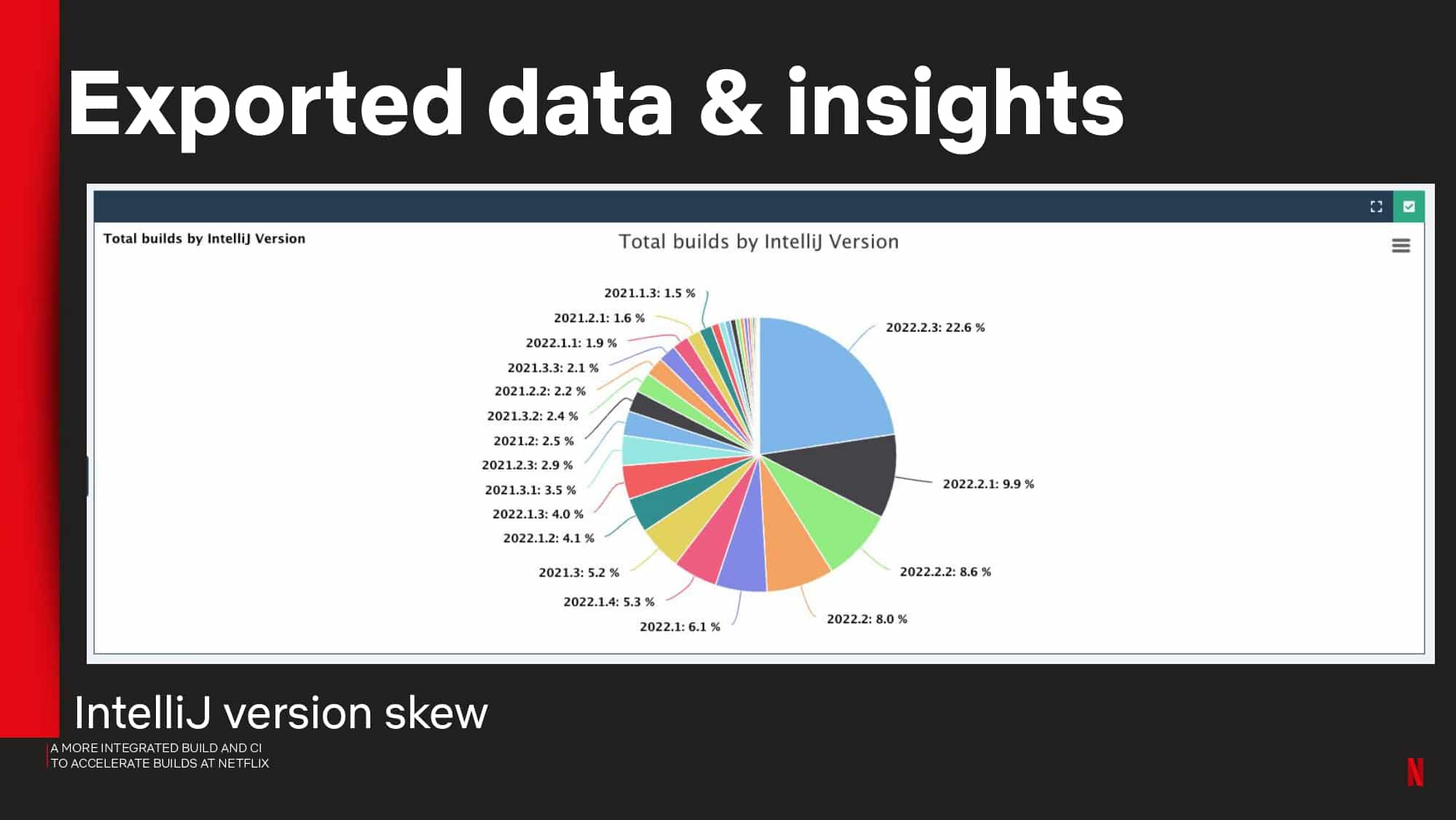


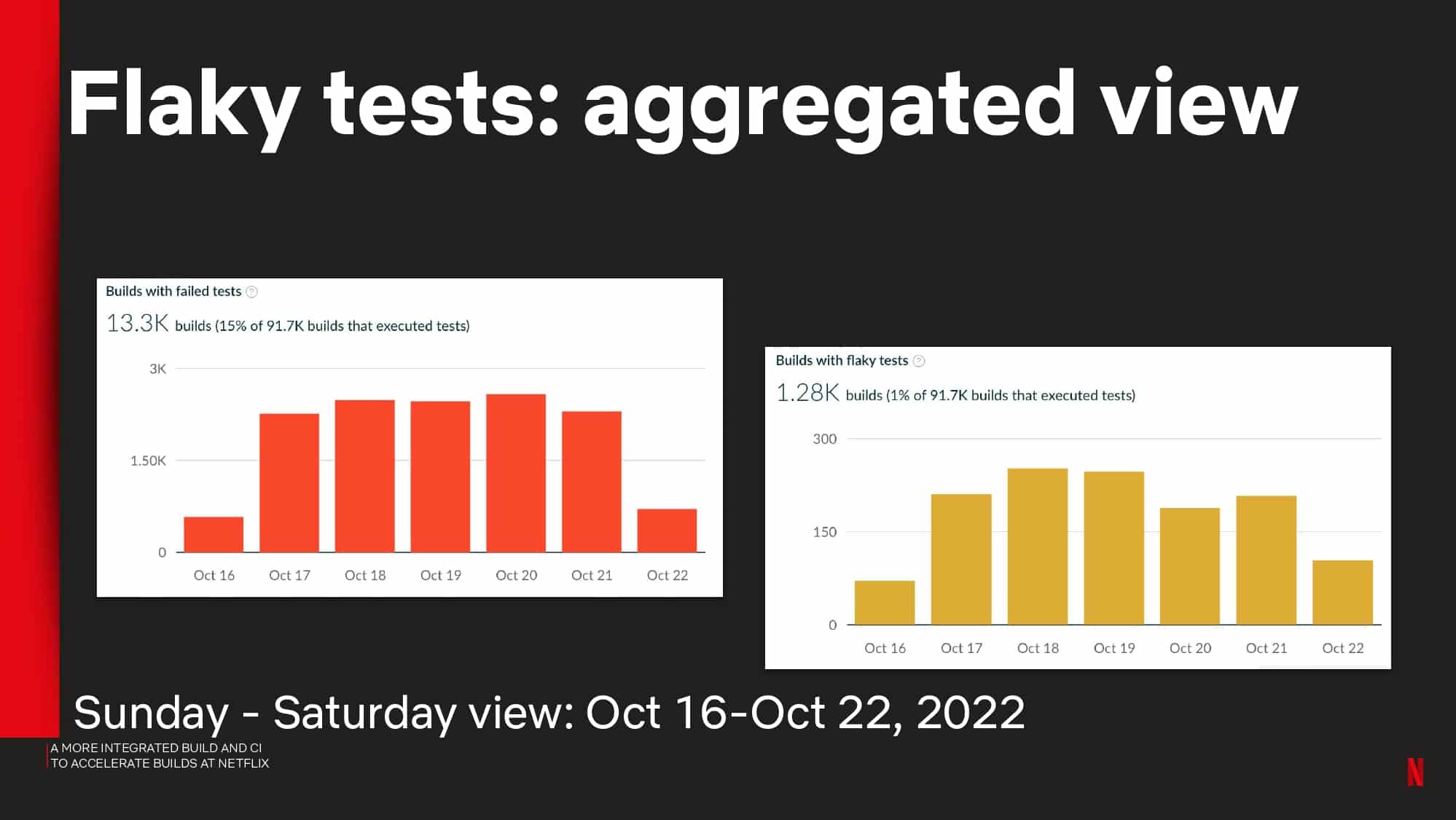
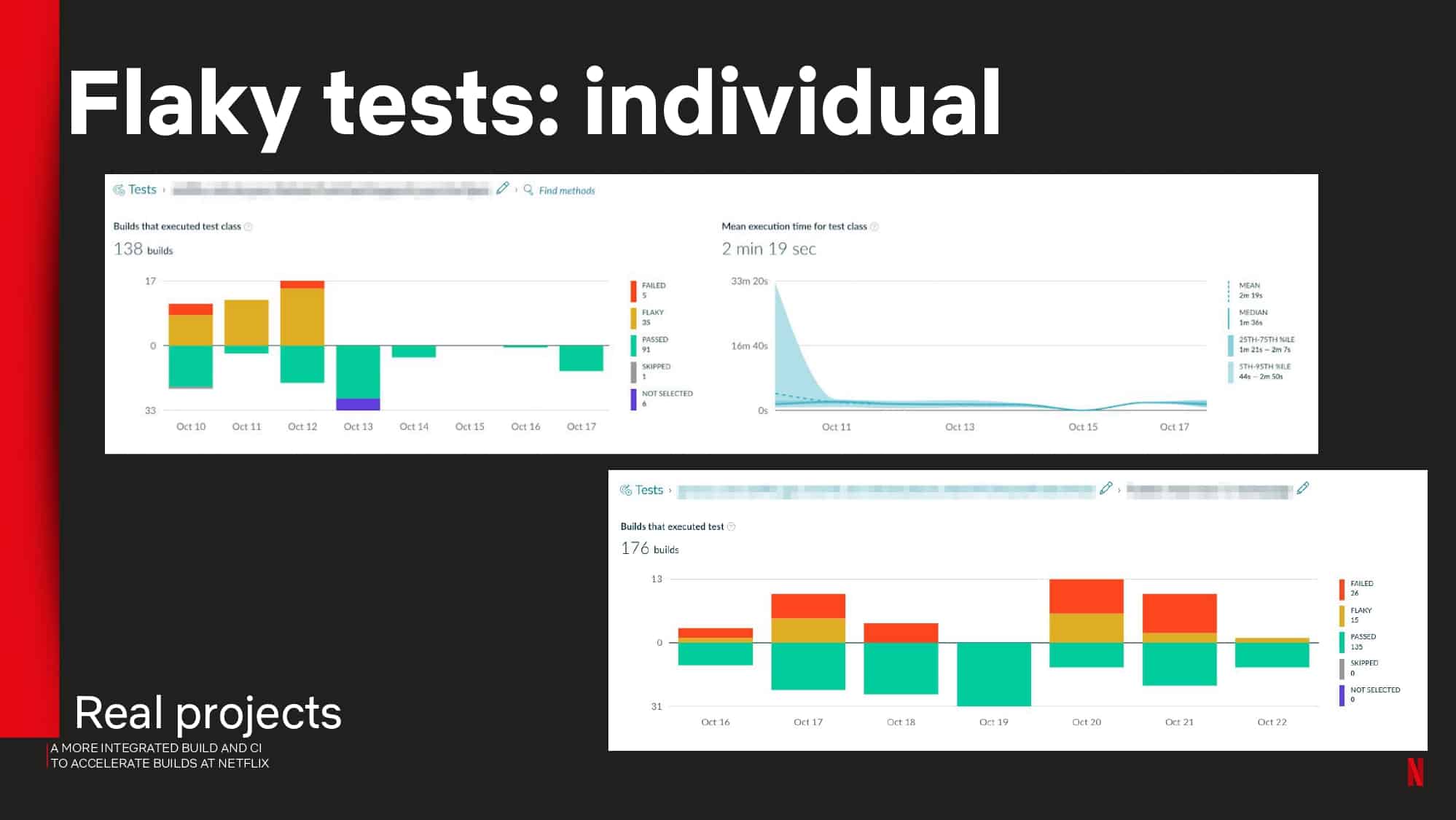

















































Interested in CI Observability and Build Optimization?
Netflix
Pursues Soft DevEx Goals with Hard DevProd Metrics using Test Distribution
6-minute read

Improve Gradle & Maven Build Reliability with Build Failure
Analytics
9-minute watch

Gradle Enterprise for Developers
1-hour training