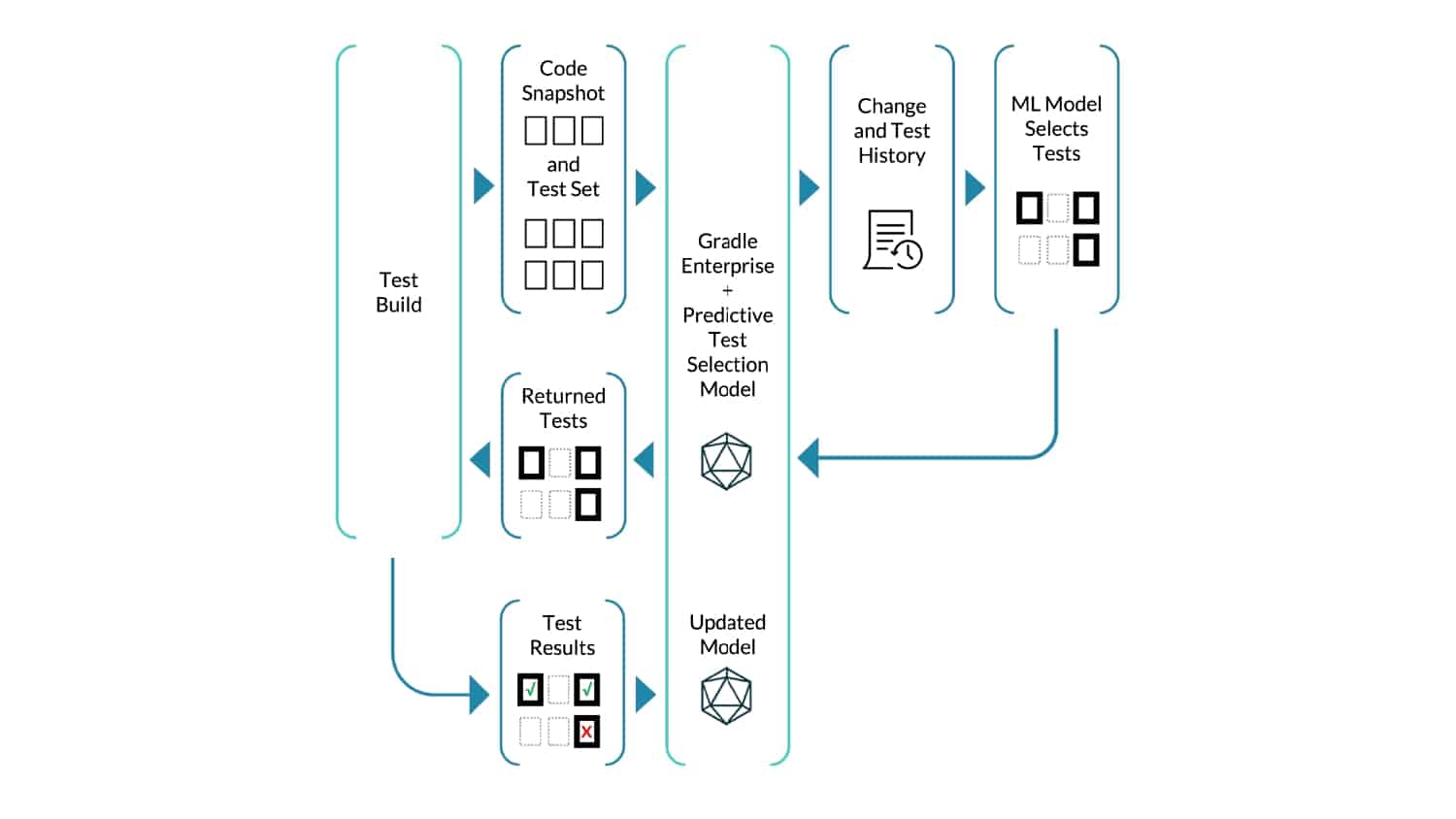
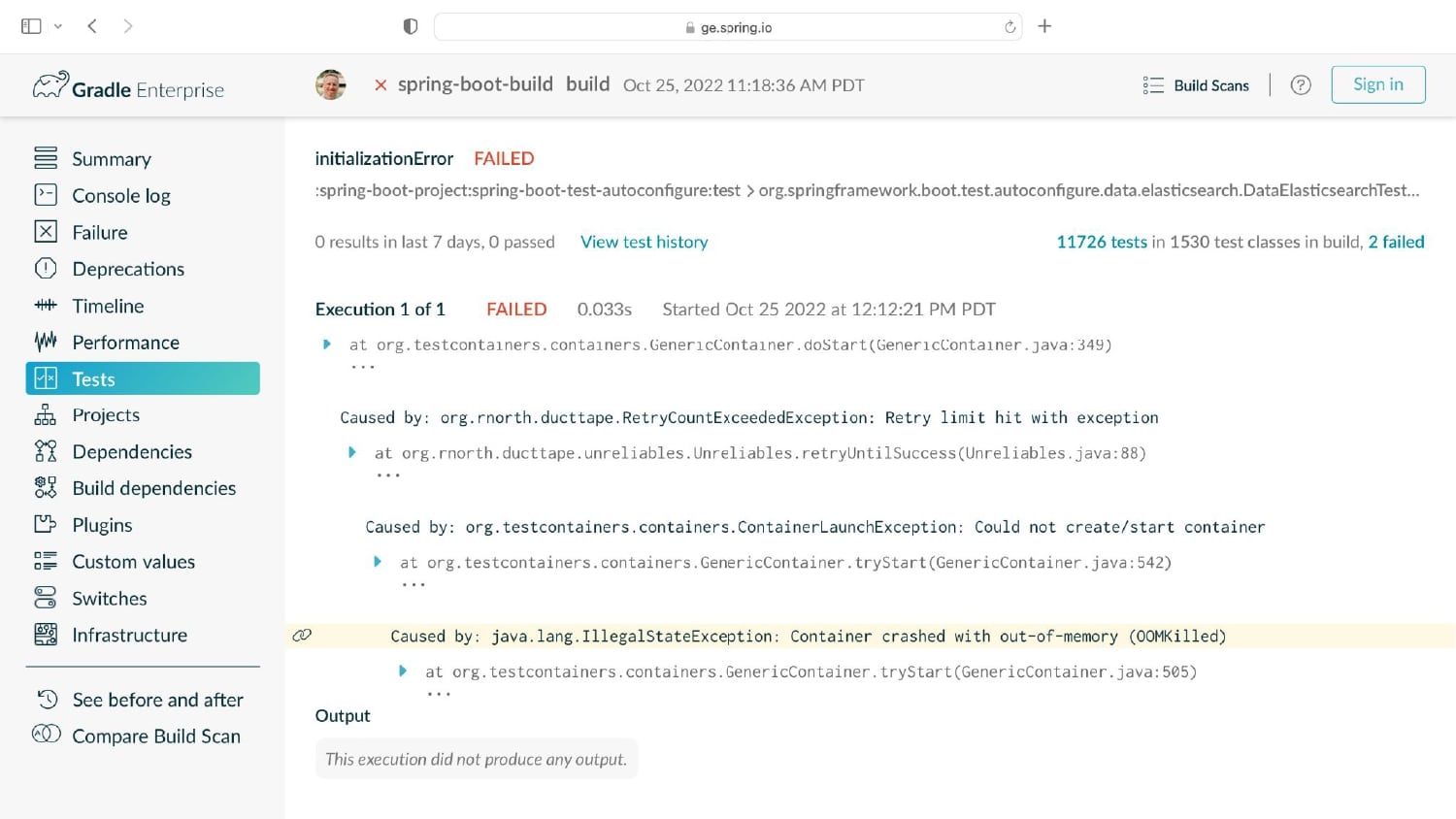
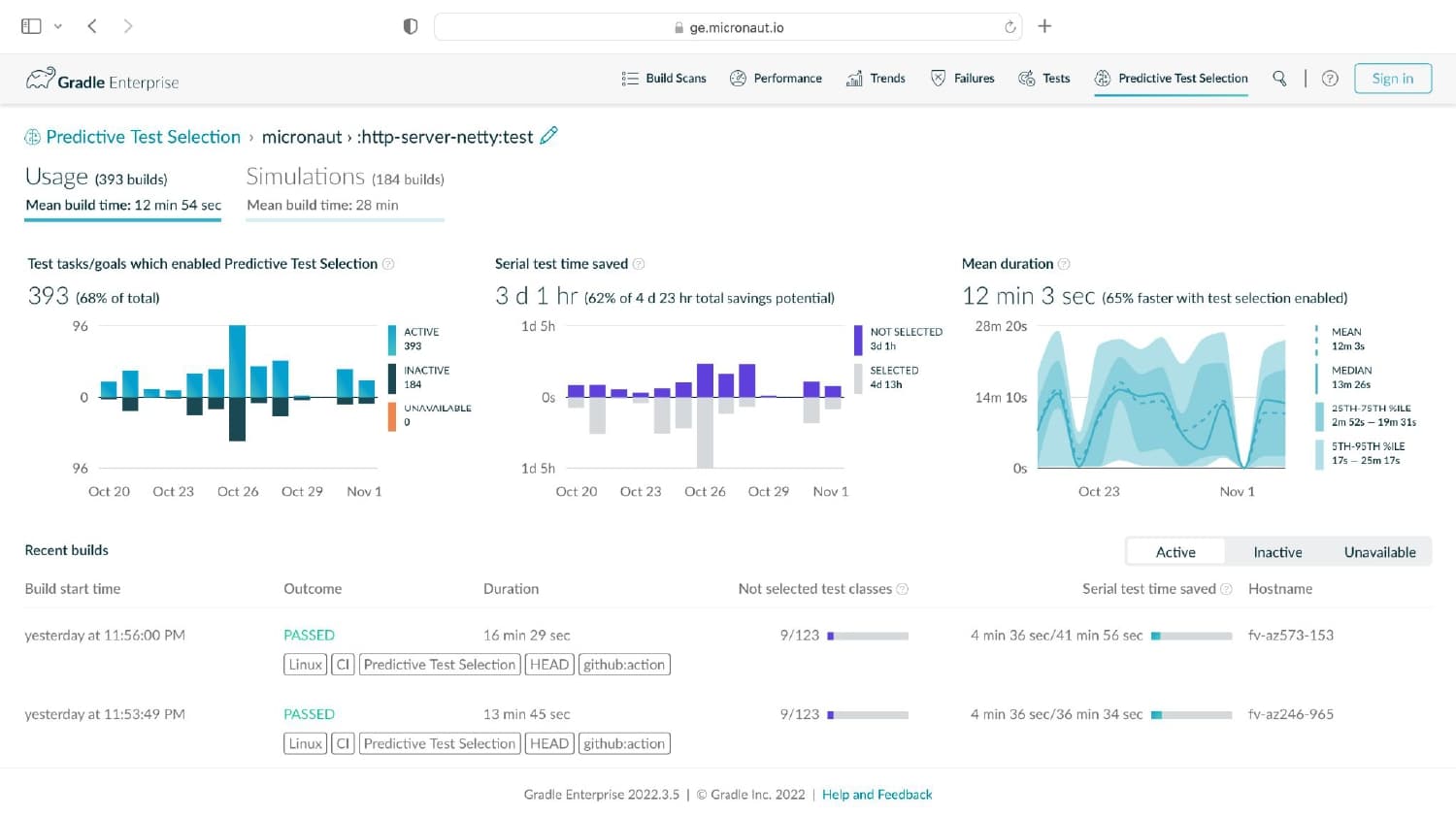
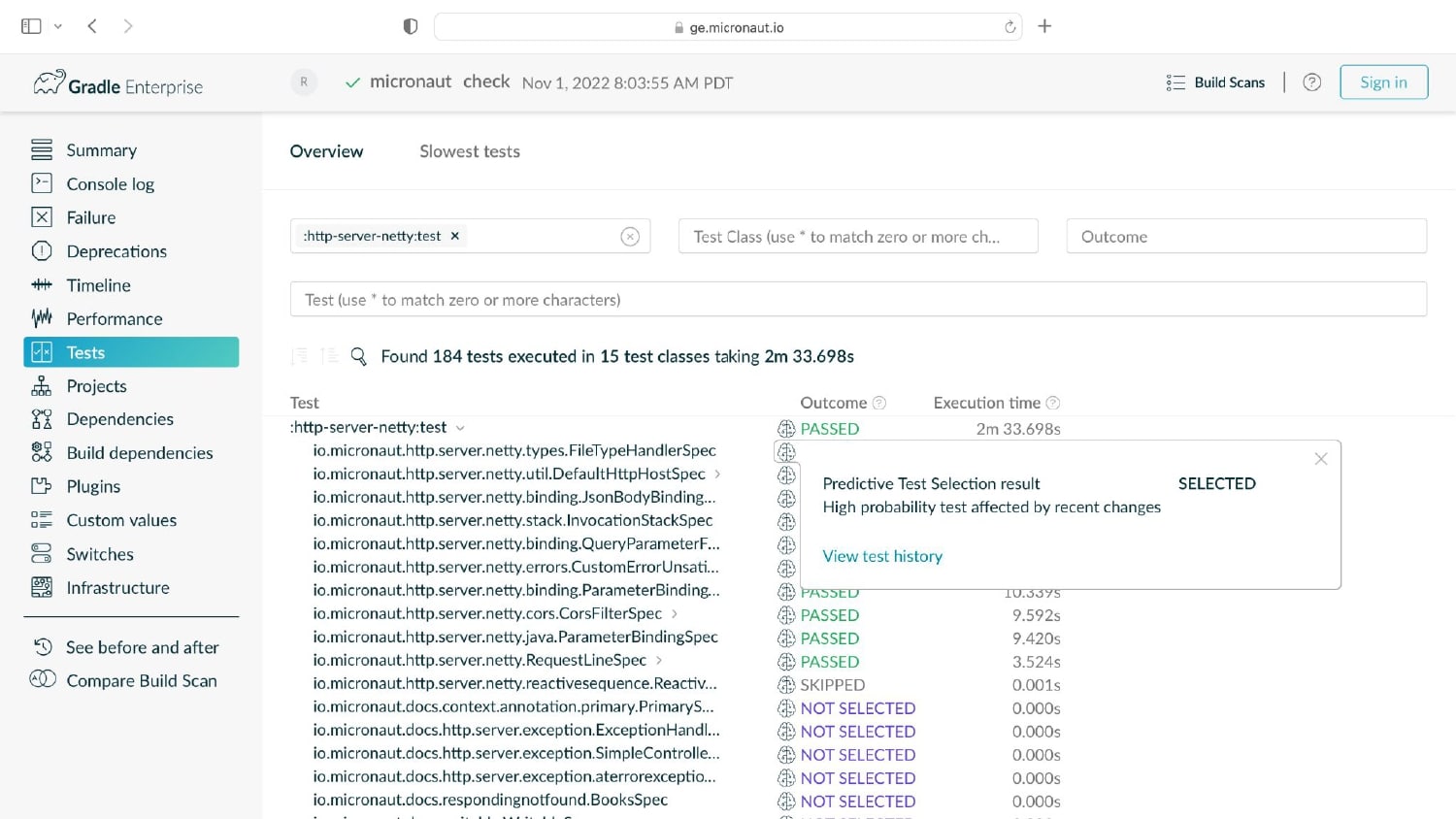
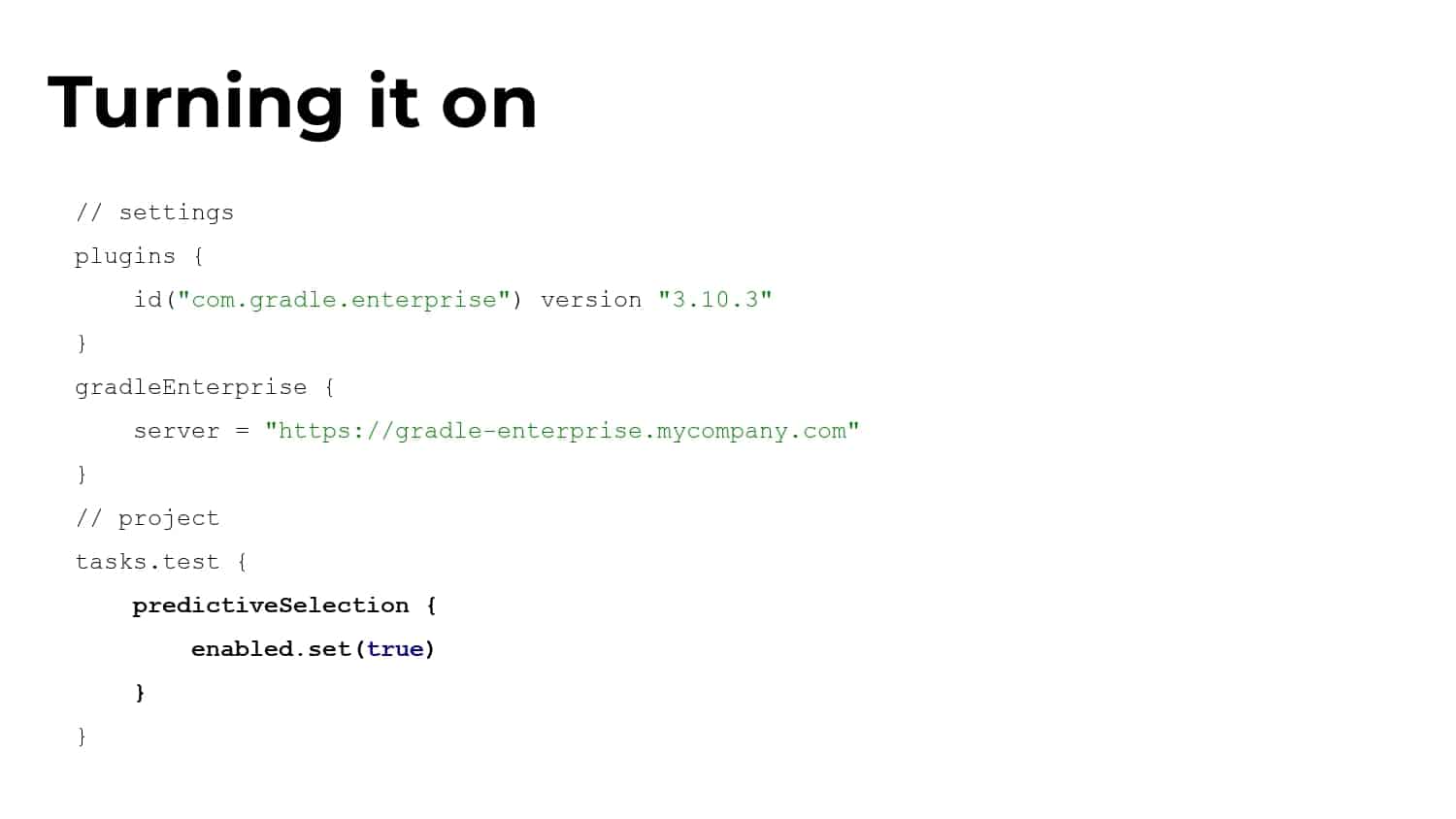
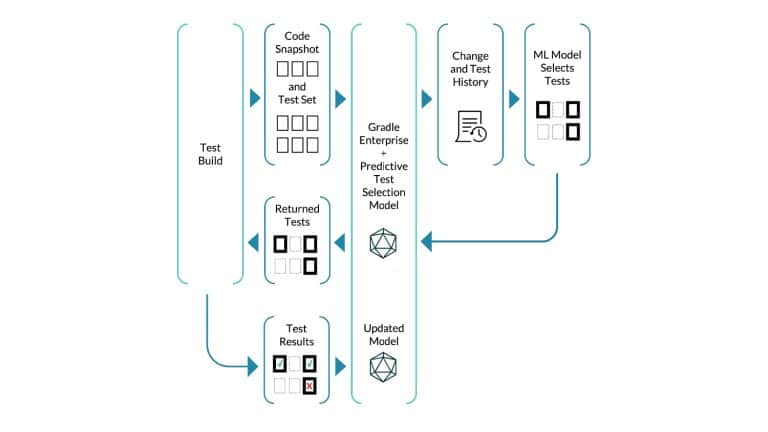
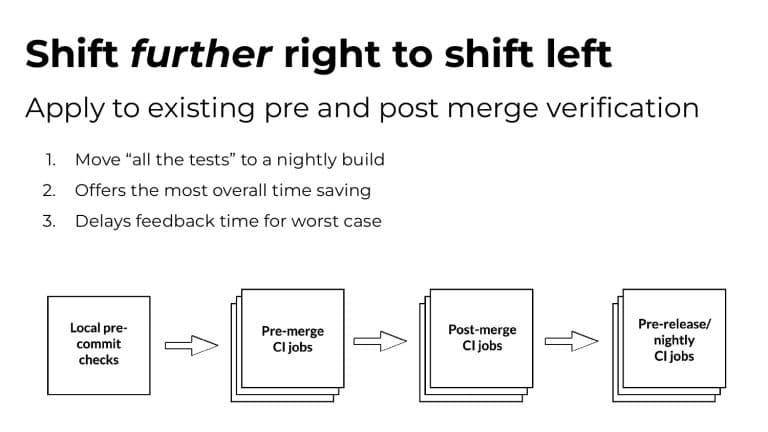
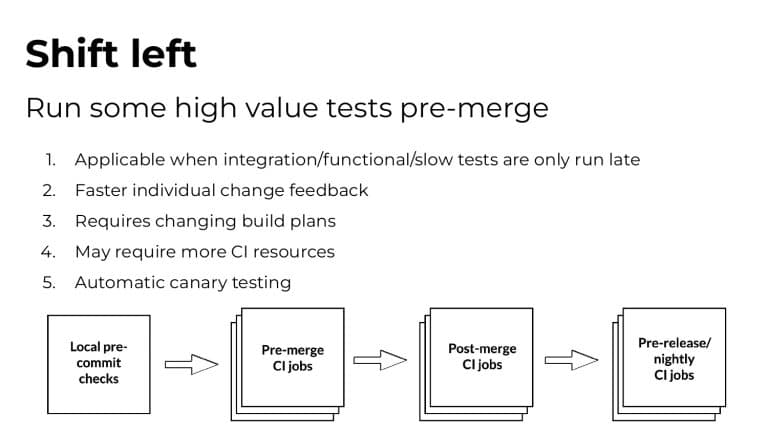
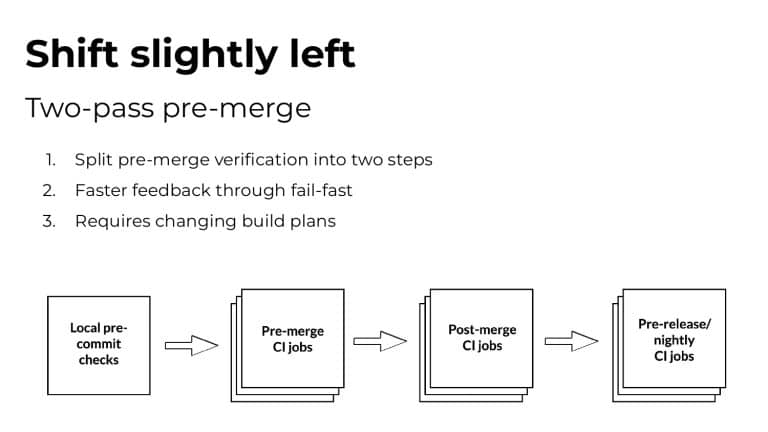
Whenever a developer makes changes to their code, it usually affects just a tiny minority of their codebase. Sadly, the tests that cover these small changes often take up 90% or more of the entire time it takes to run builds and tests! It’s easy to see why a trending concept called “Test Impact Analysis” is taking root in organizations that care deeply about developer productivity.
In this talk, Gradle shares its strategy for Predictive Test Selection, its role as a promising Test Impact Analysis solution, the tenets and tradeoffs intentionally made to provide a solid developer and build engineering experience and best practices for software teams that want to use this exciting ML-based technology.
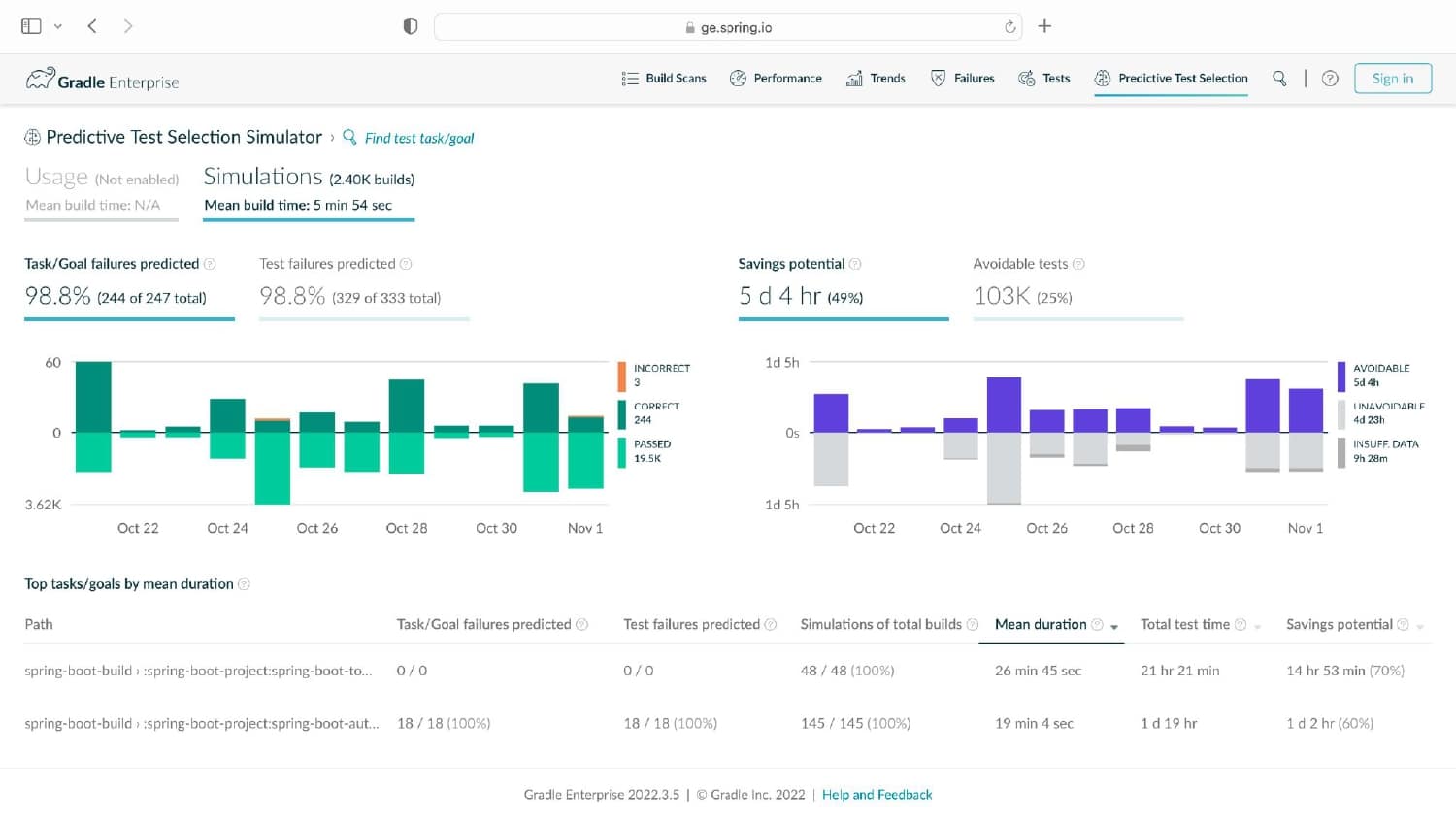
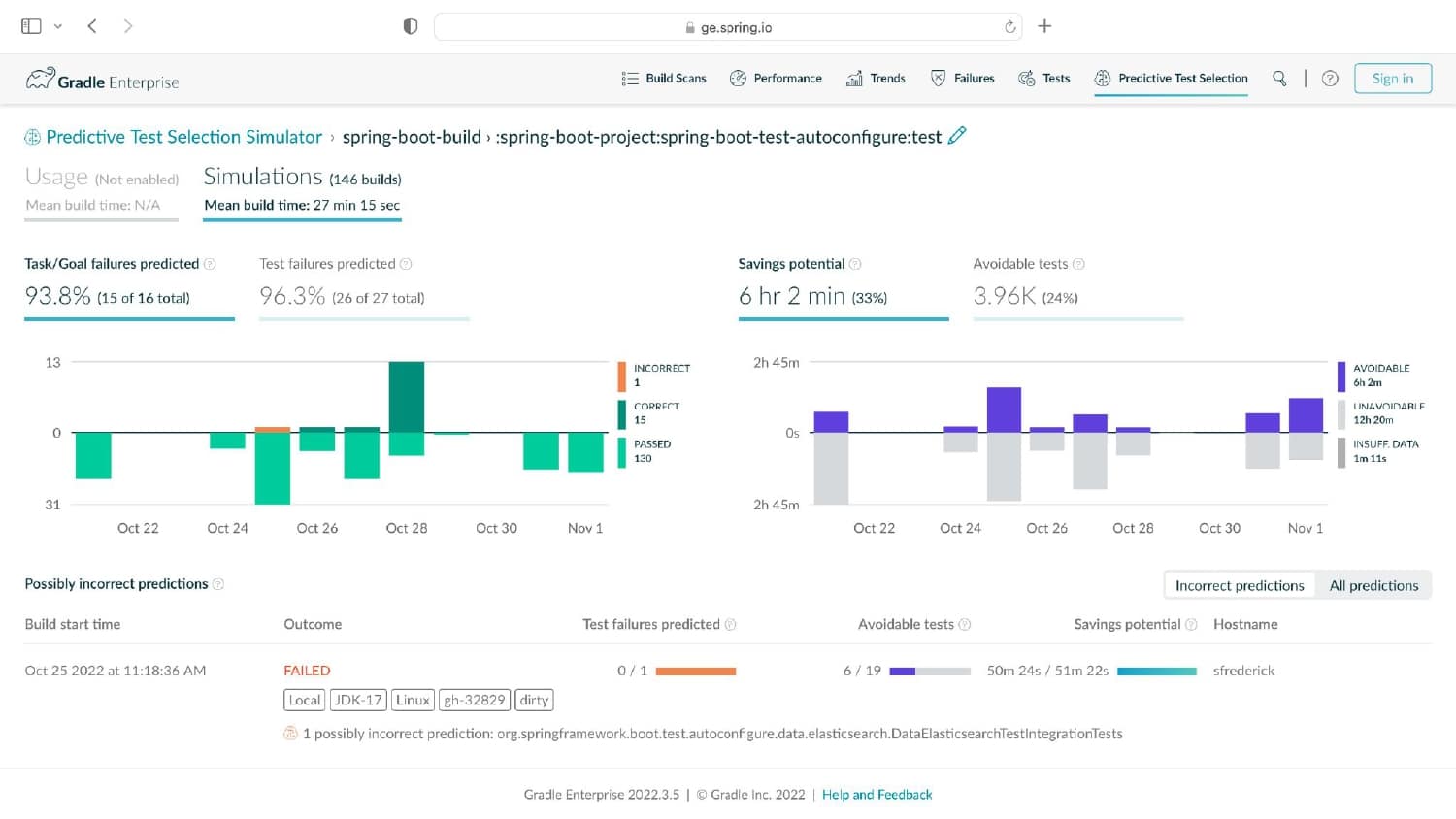
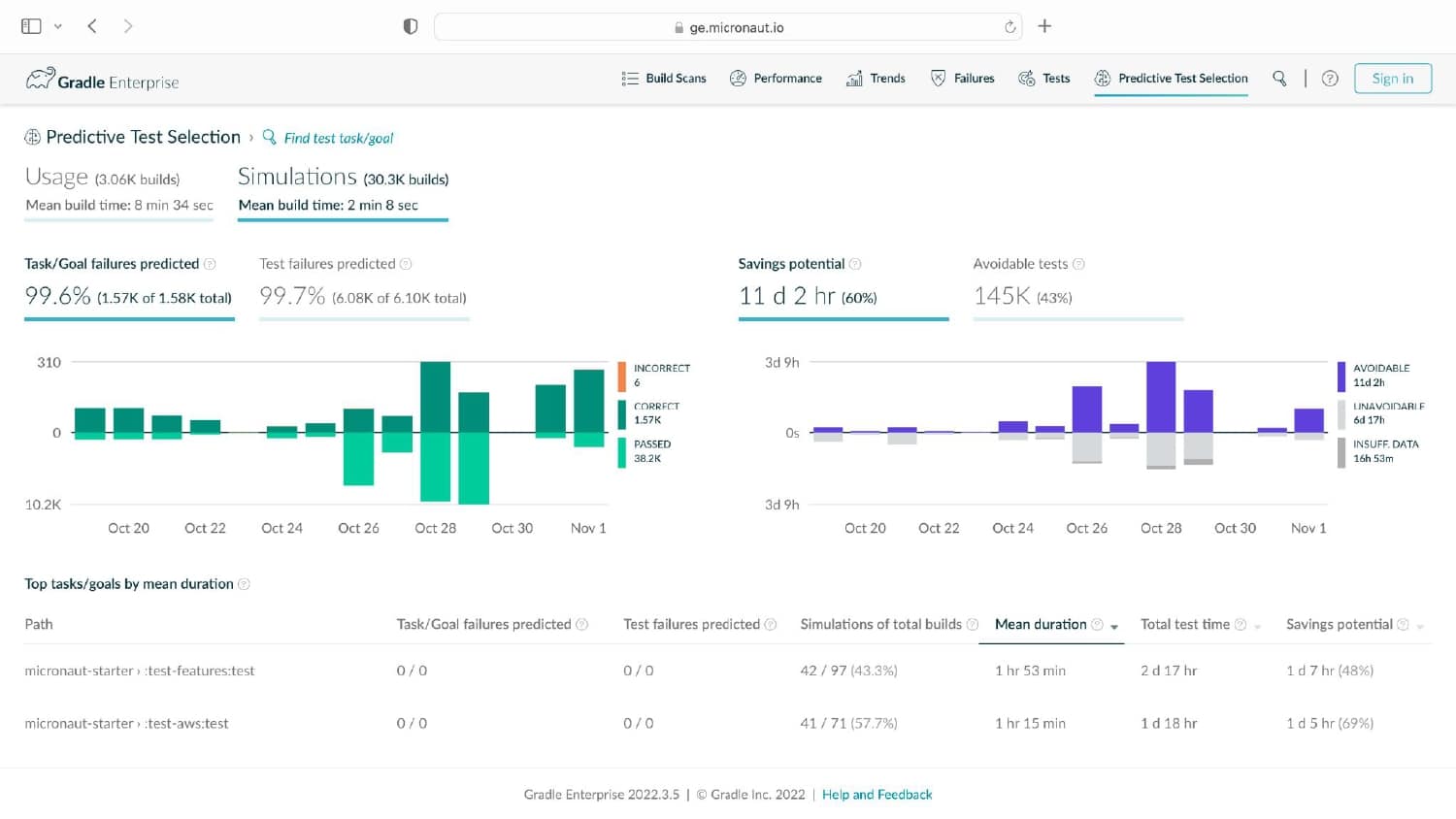
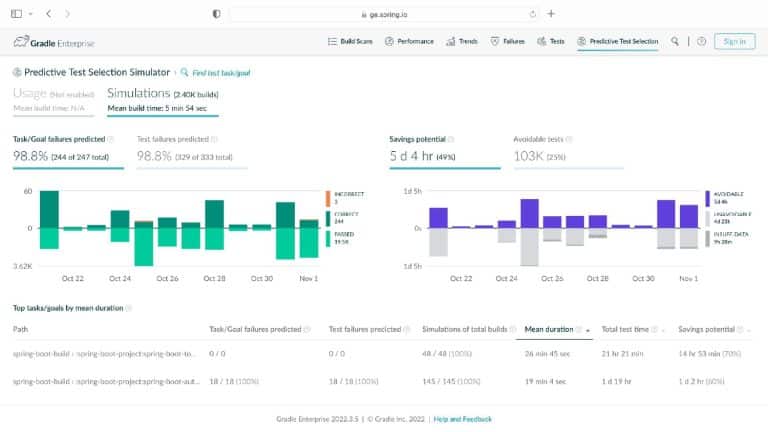
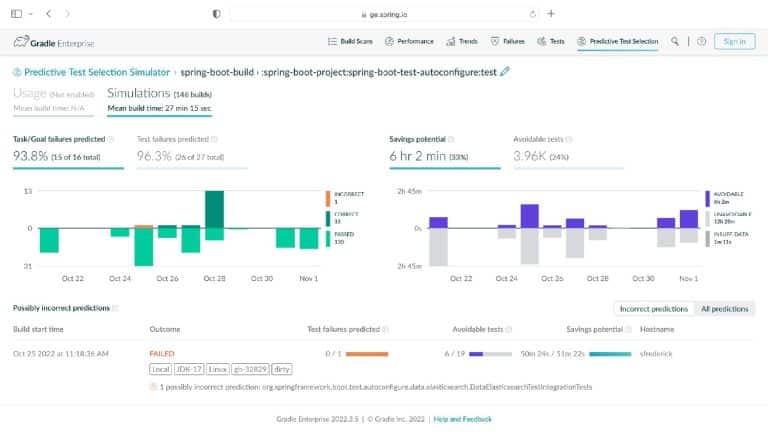
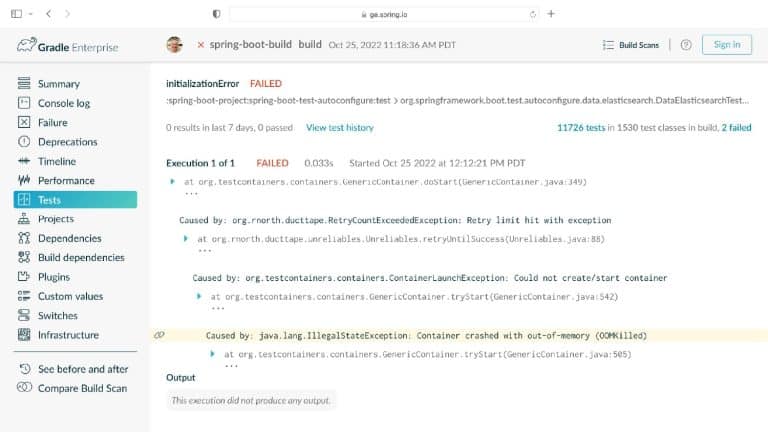
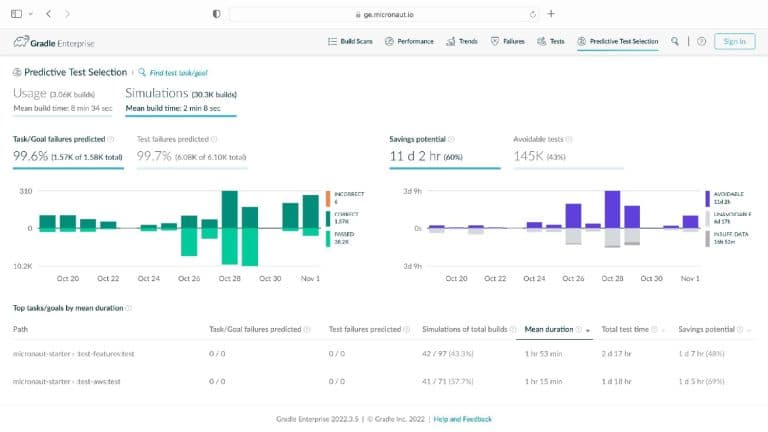
Having analyzed hundreds of millions of lines of code across thousands of projects, Gradle knows about build and test processes. You may be surprised to learn that 3% of tests take up 97% of the testing time, that the majority of testing time affects just 1% of code (and 1% of tests), and that testing more commonly uncovers problems with external systems rather than issues with the code itself.
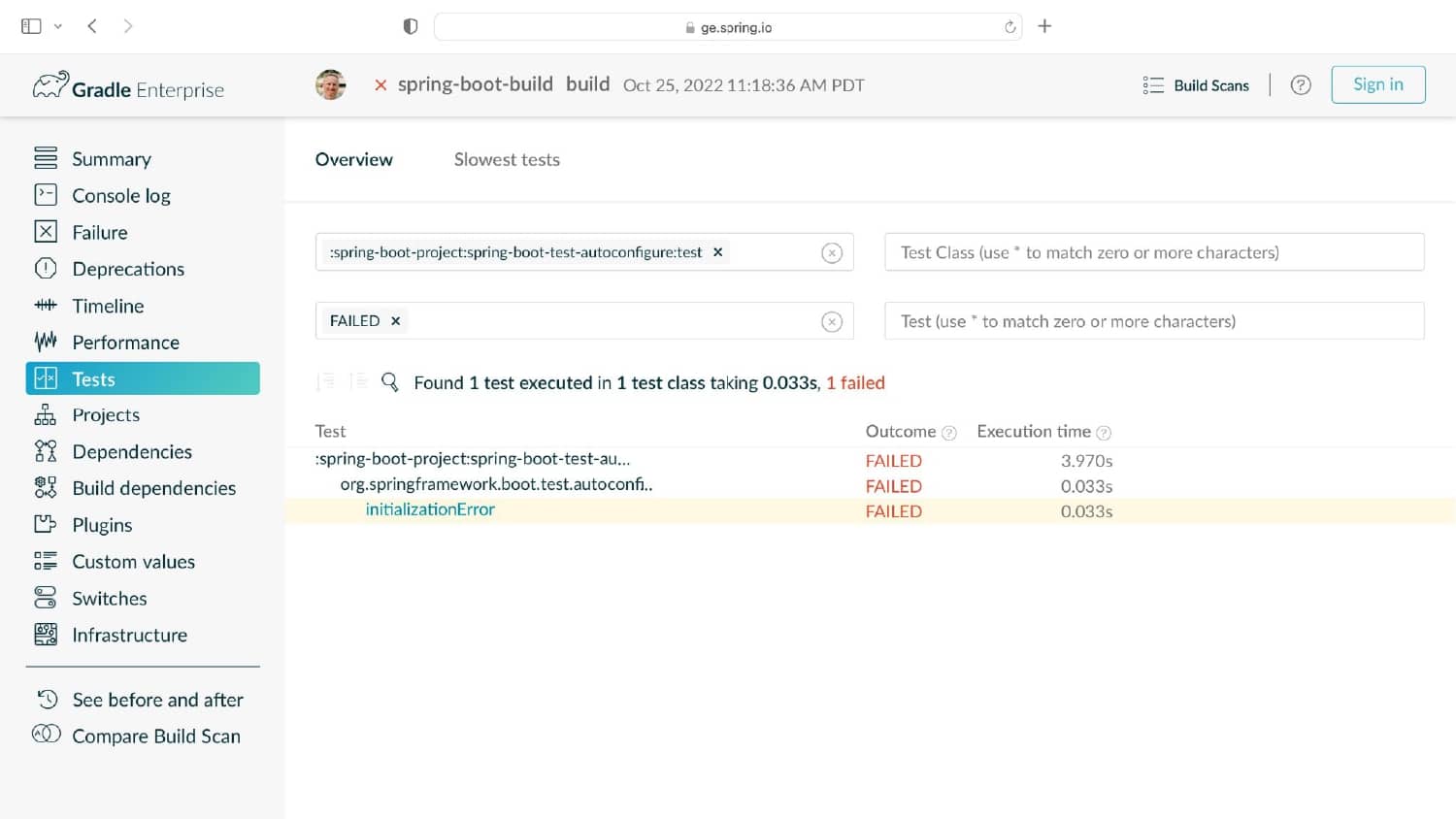
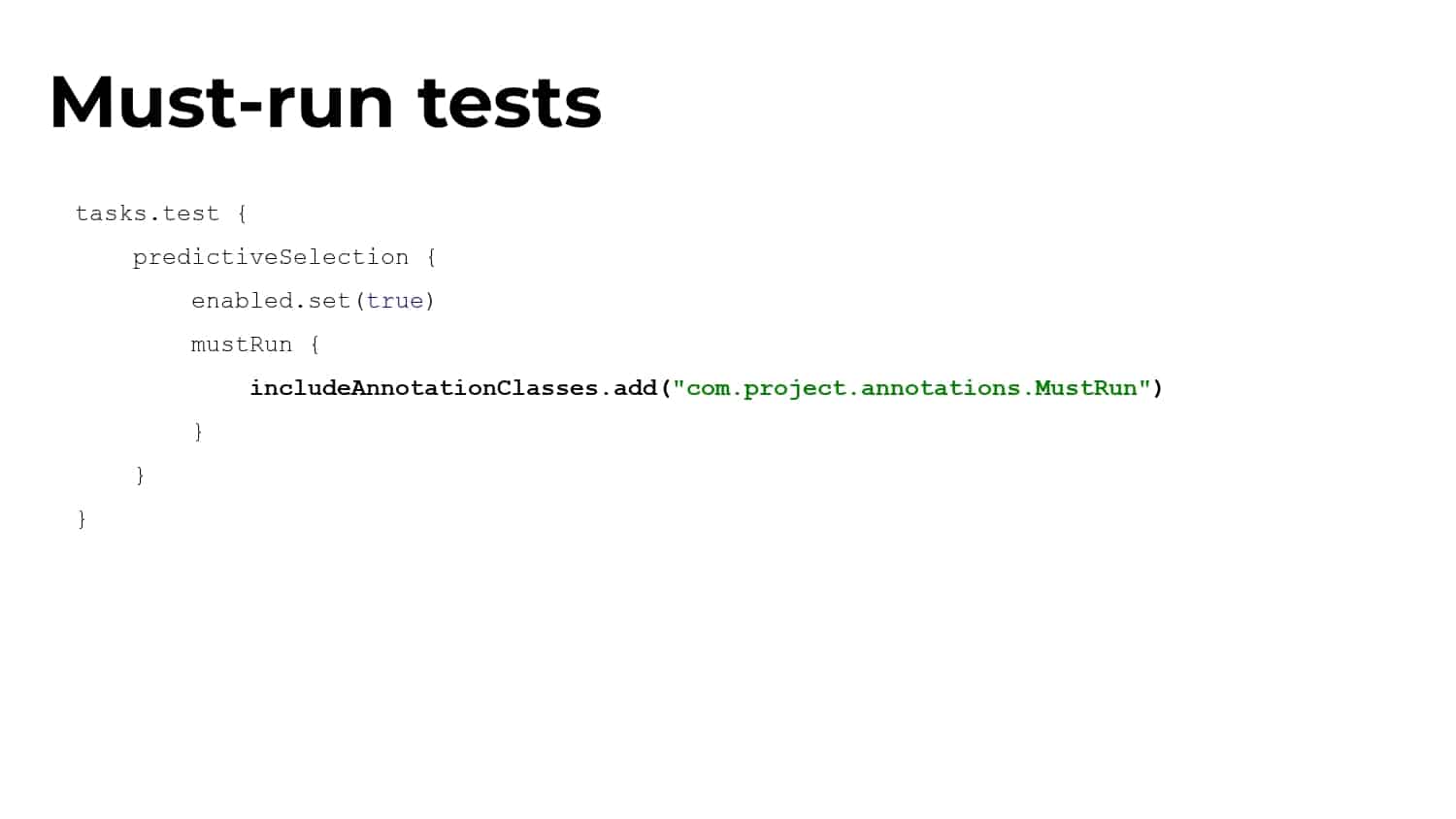
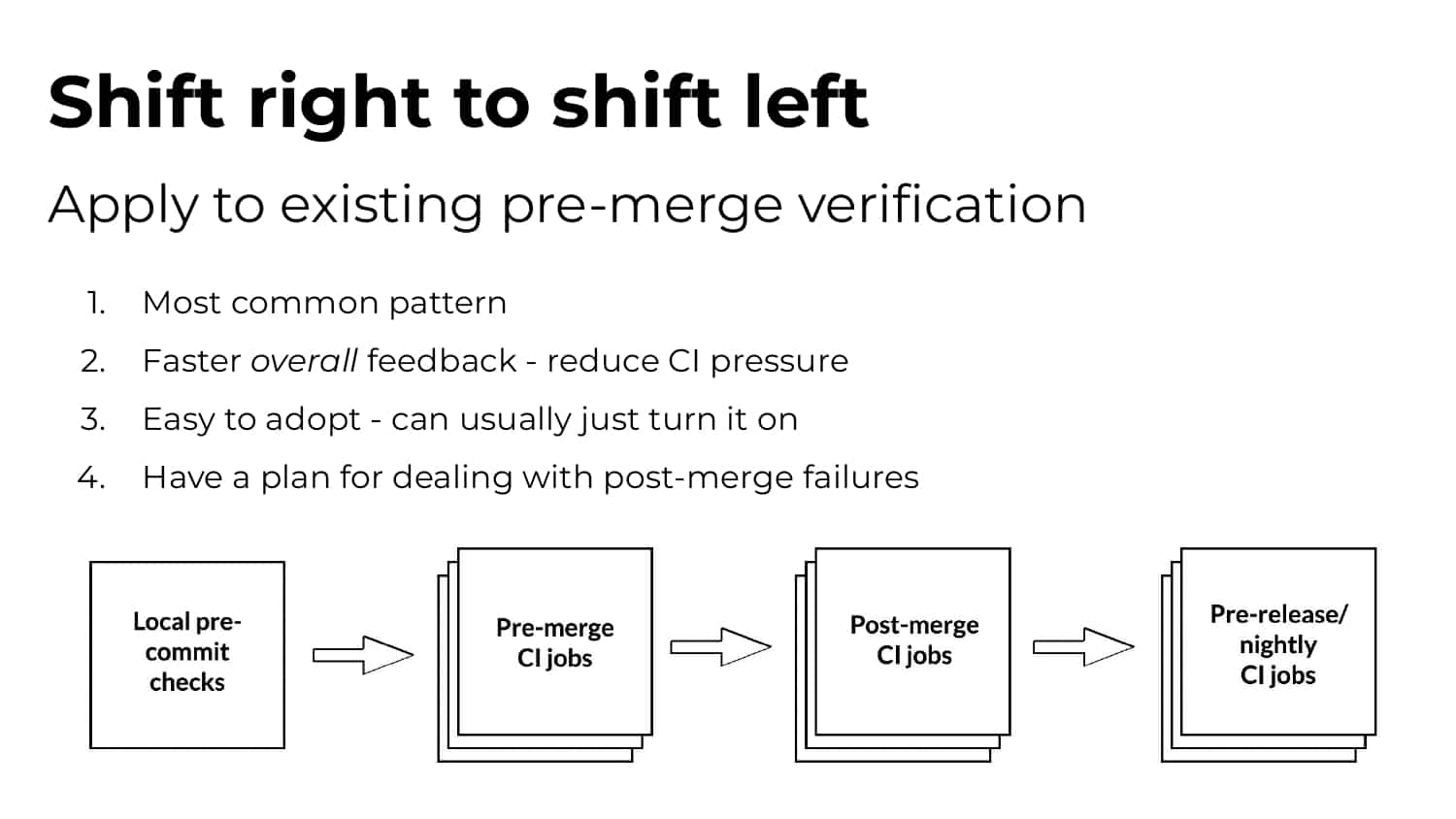
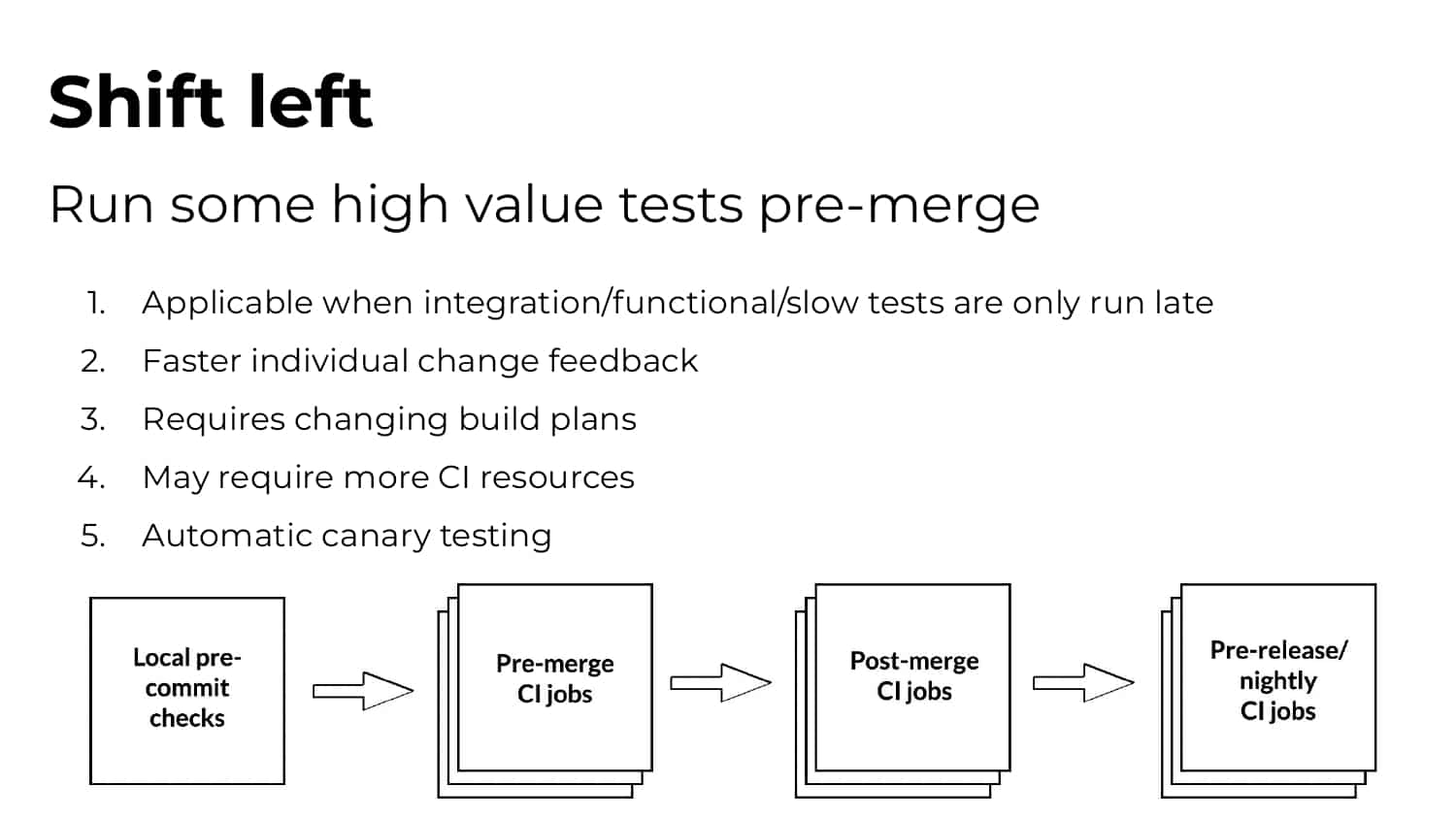
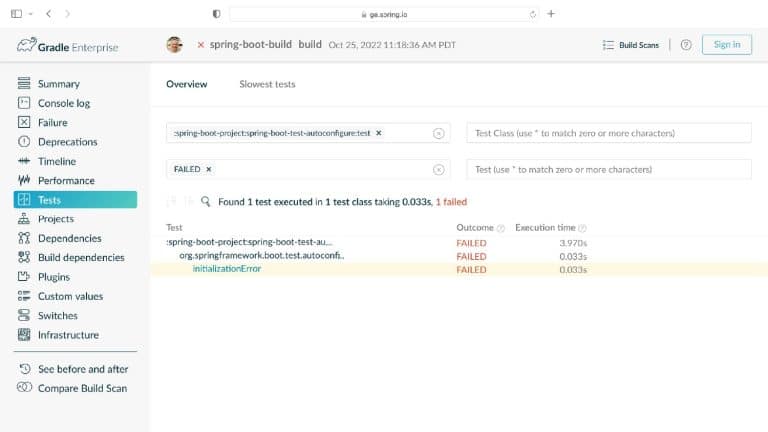
What’s needed is a smarter ML-driven testing strategy tooling that provides observable and actionable data. Predictive Test Selection provides data that is instrumented to help dev and CI teams more rapidly troubleshoot performance issues and optimize feedback cycle times. In this talk, Gradle explains the pros and cons of common test-time reduction strategies, the origins and objectives of the Predictive Test Selection feature in Gradle Enterprise, and how all of this relates to DPE practices for building confidence in the performance and reliability of your toolchain.
Luke Daley is a Principal Executive at Gradle Inc. with a penchant for building developer tools and improving developer productivity. Over the last decade he has helped build Gradle Build Tool and Gradle Enterprise.
Eric Wendelin is a Sr. Software Development Engineer at AWS, and formerly led data science and research initiatives for Gradle Enterprise as a Principal Data Scientist at Gradle Inc. Previously, he led the Gradle core team and data engineering teams at Apple and Twitter.

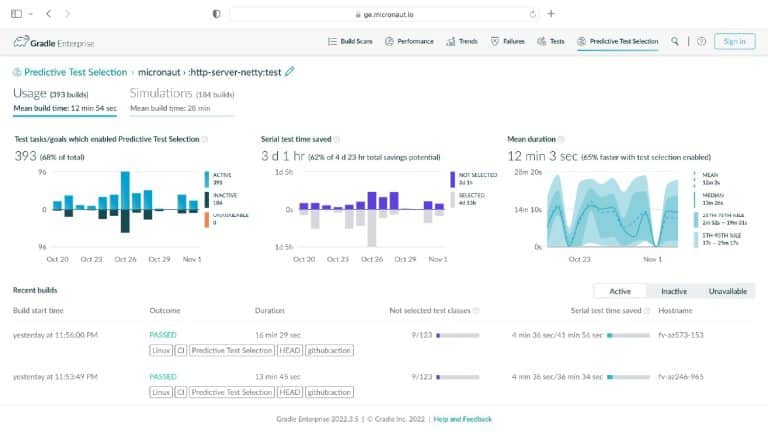
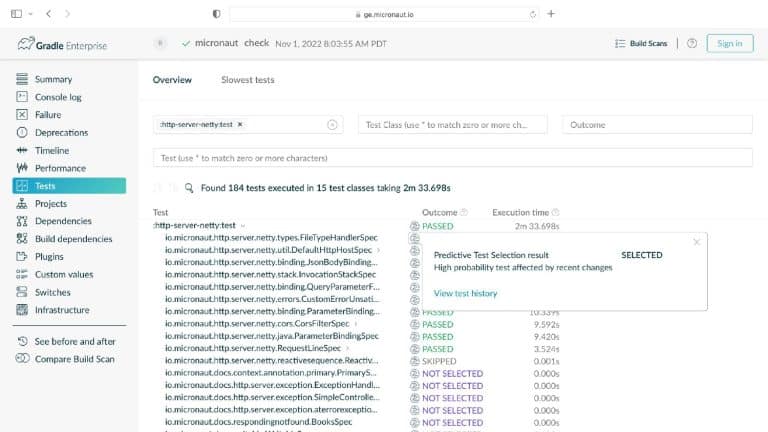
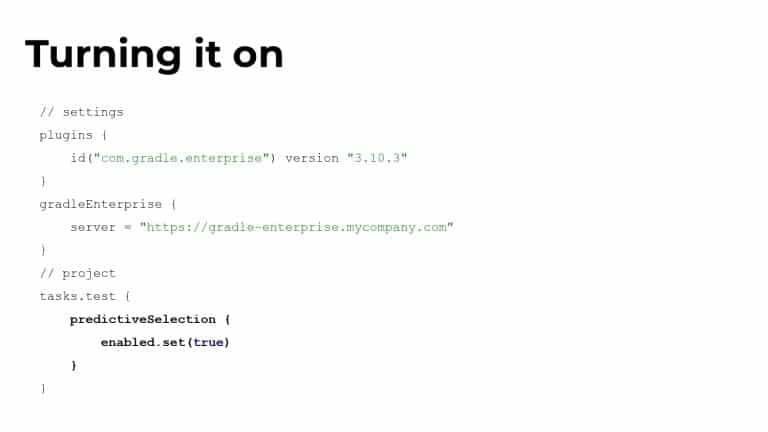
Gradle Enterprise customers use Predictive Test Selection to save significant time by using machine learning to predict and run only tests that are likely to provide useful feedback. Other acceleration technologies are available in Gradle Enterprise, such as Build Cache, which reduces build and test times by avoiding re-running code that hasn’t changed since the last successful build, and Test Distribution, which further reduces time wasted by parallelizing tests across all available infrastructure. You can learn more about these features by starting with a free Build Scan™ for your Maven and Gradle Build Tool projects, watching videos, and registering for our free instructor-led Build Cache deep-dive training.