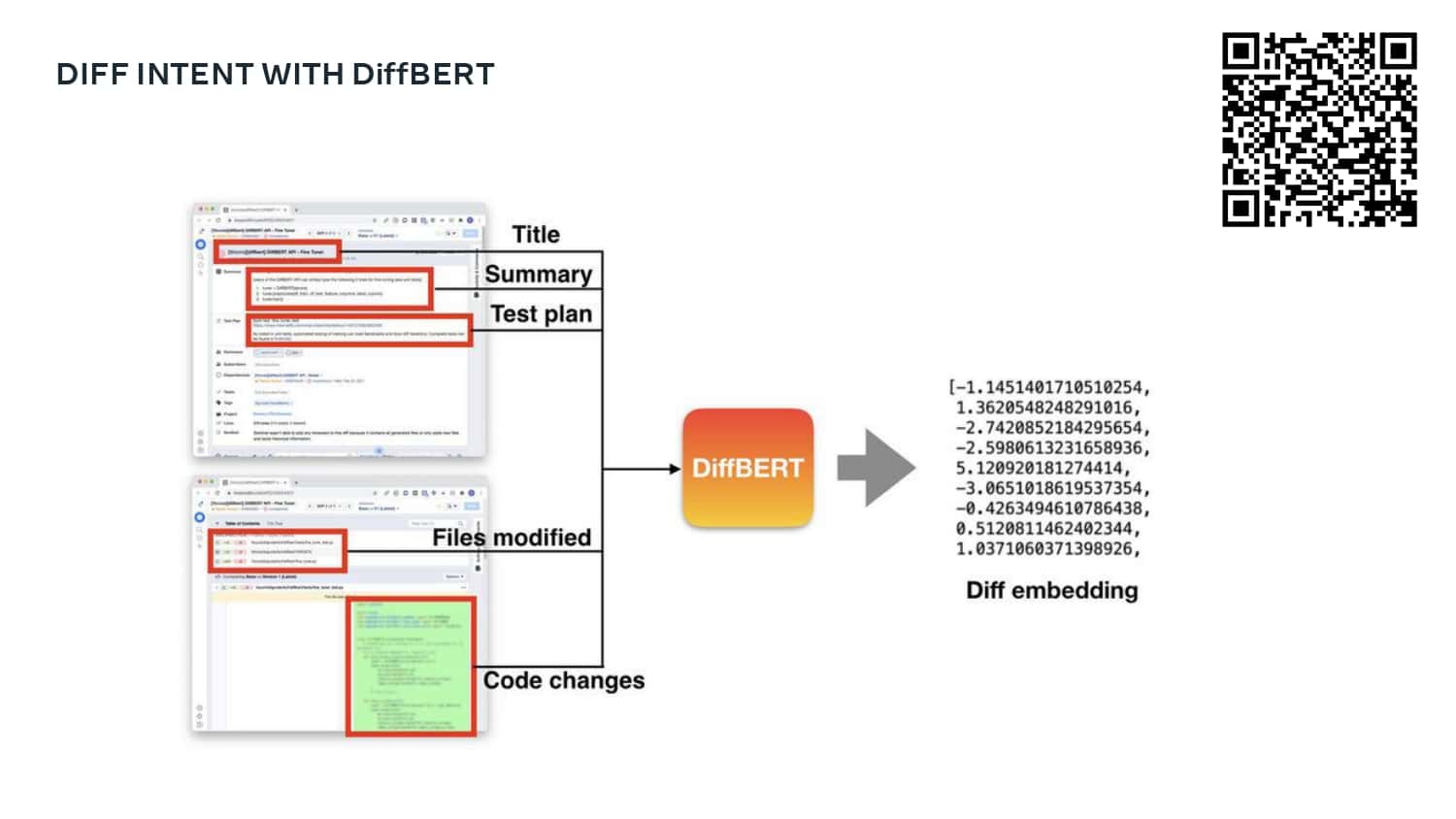
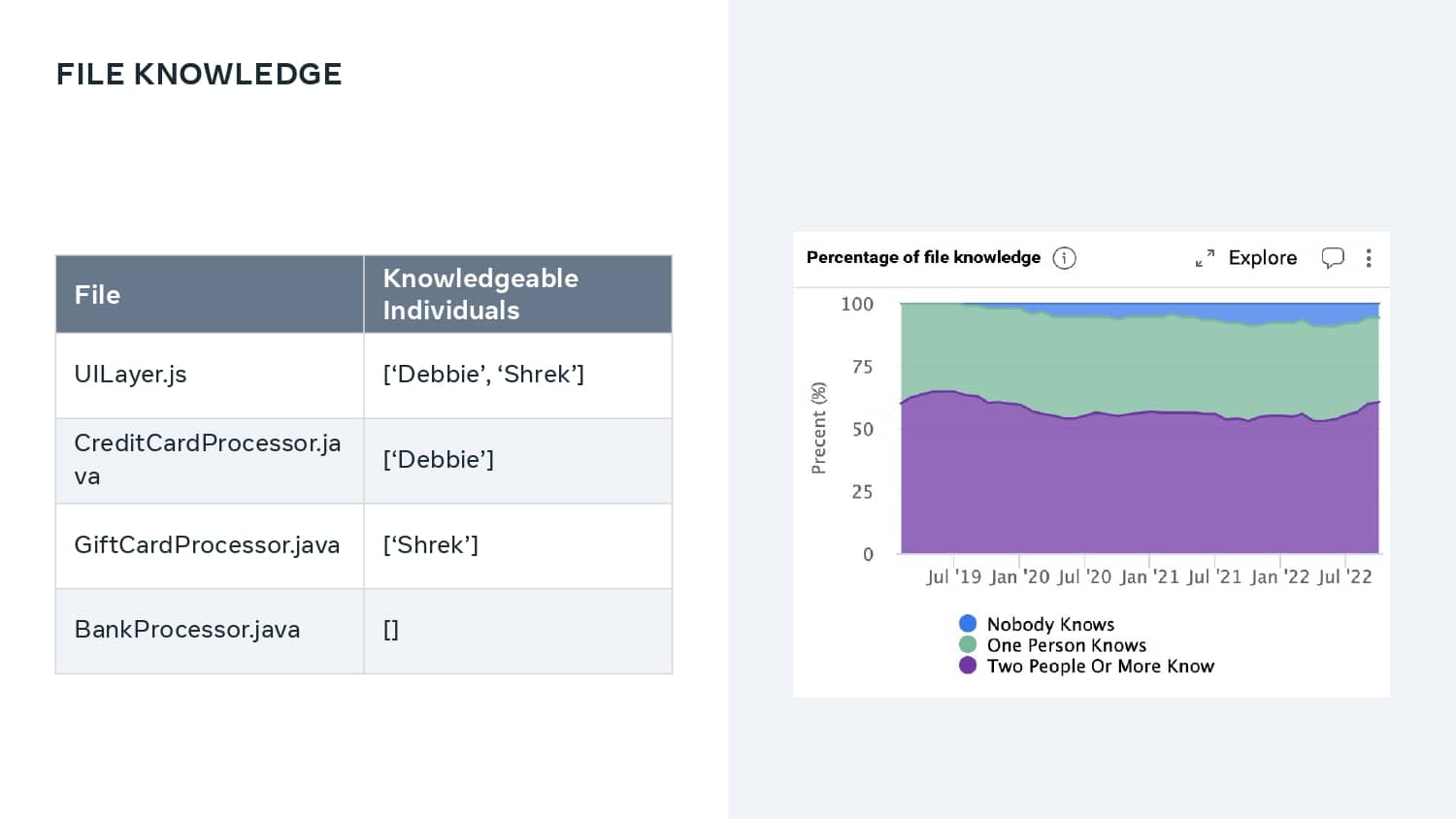
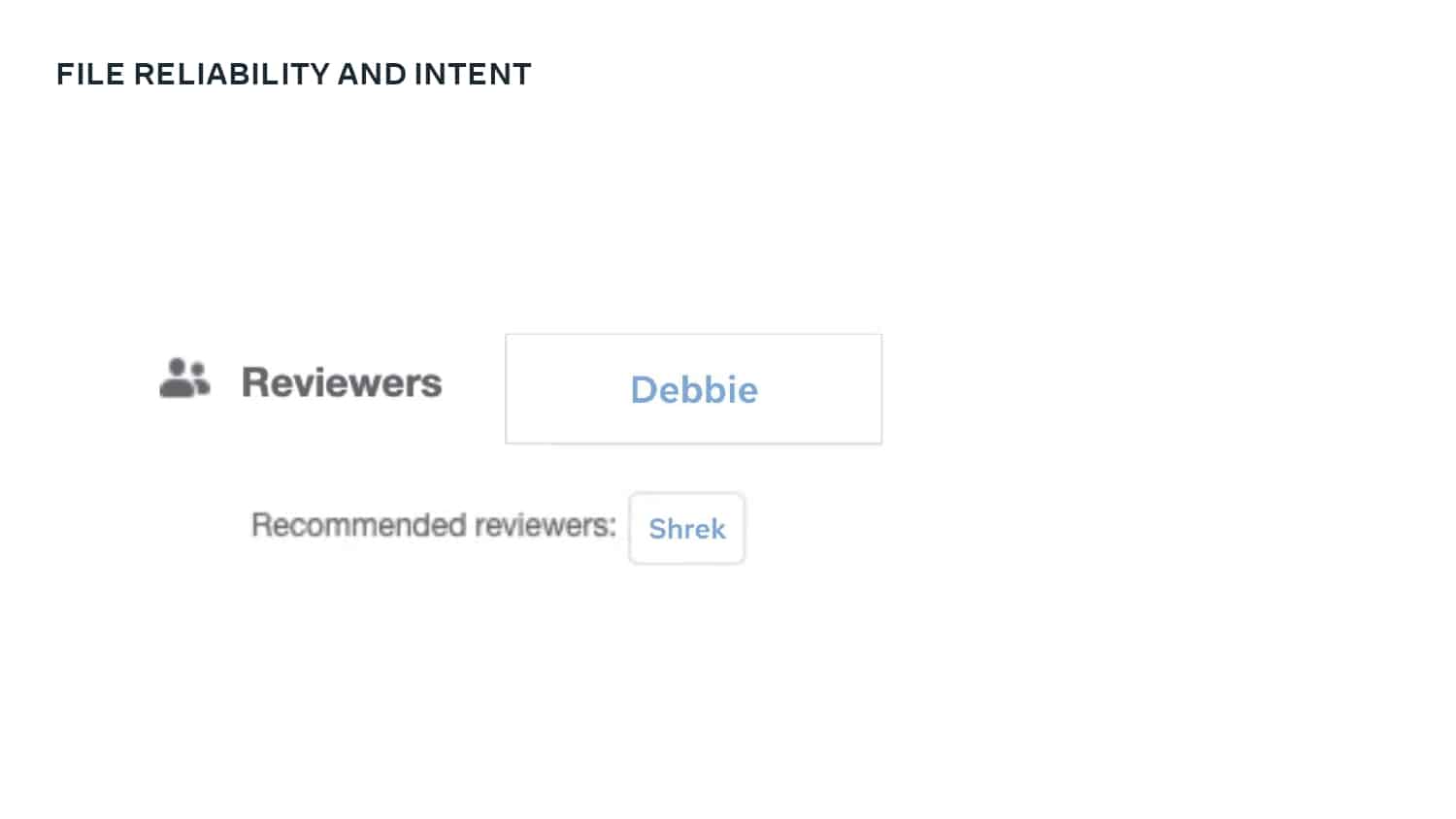
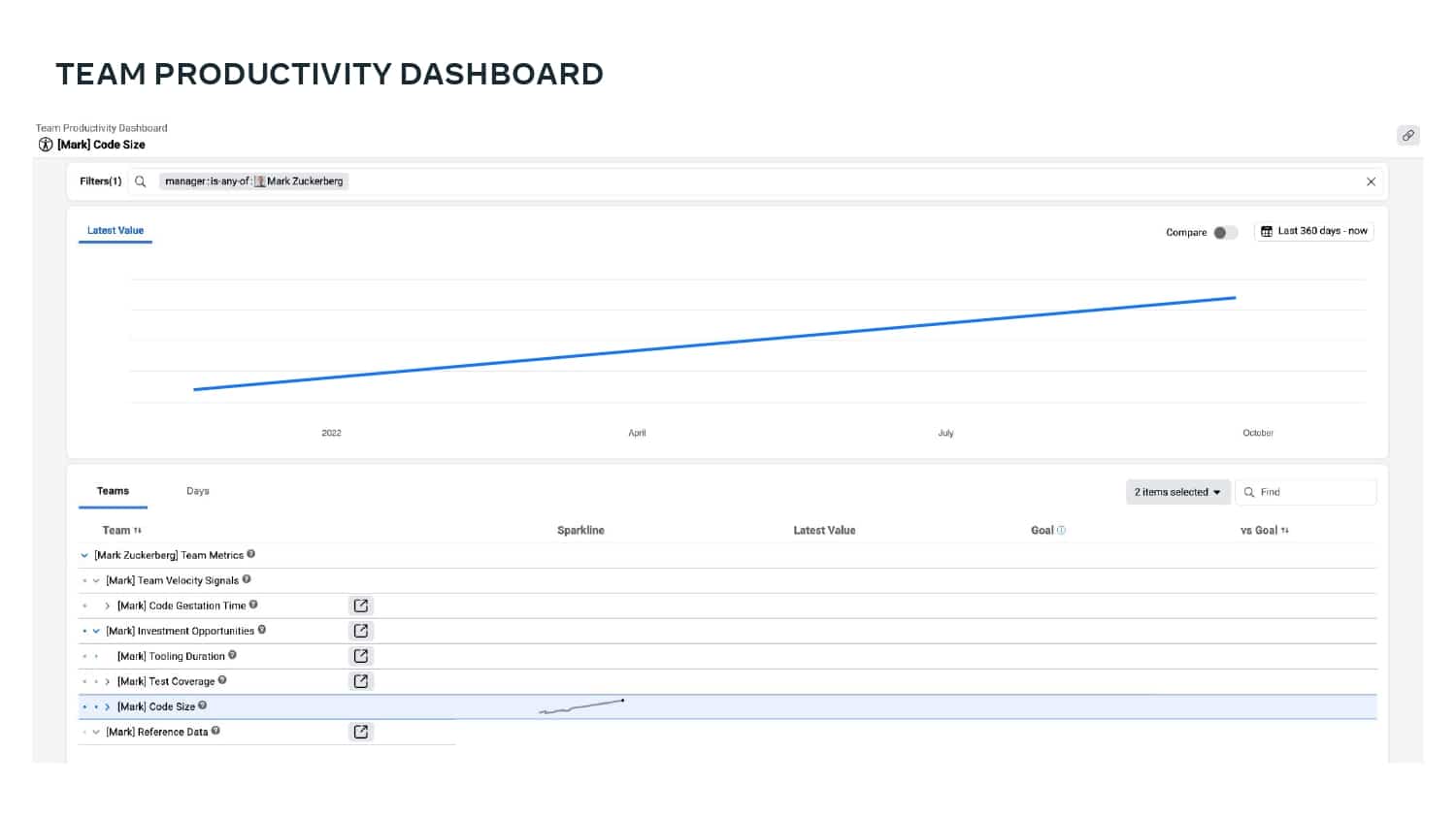
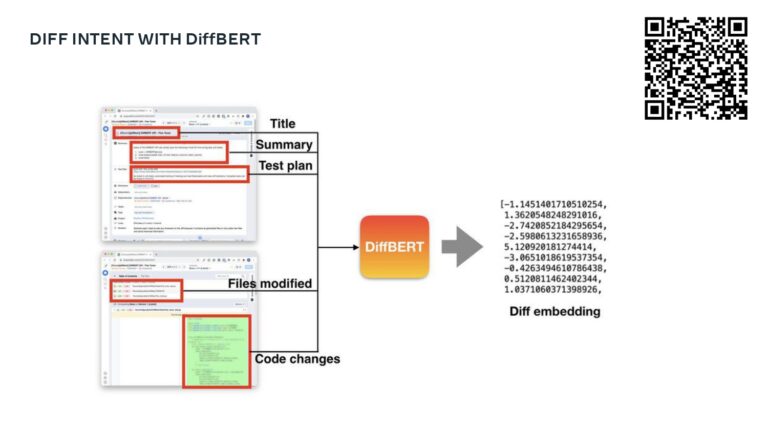
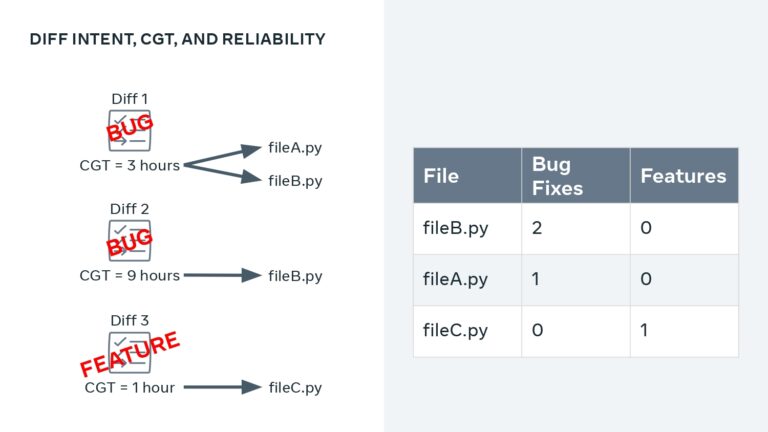
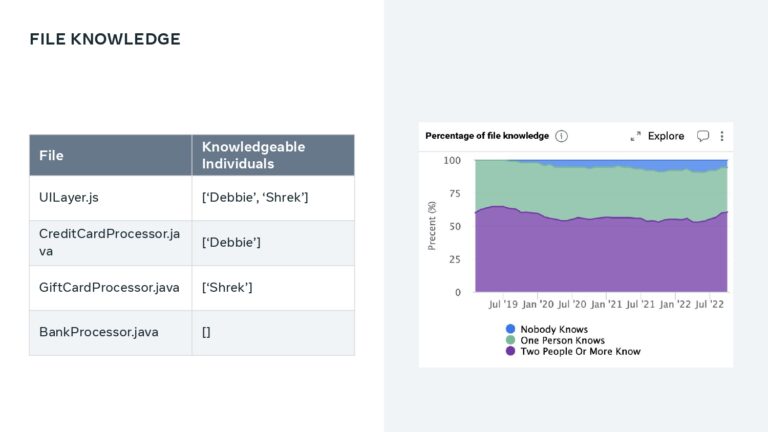
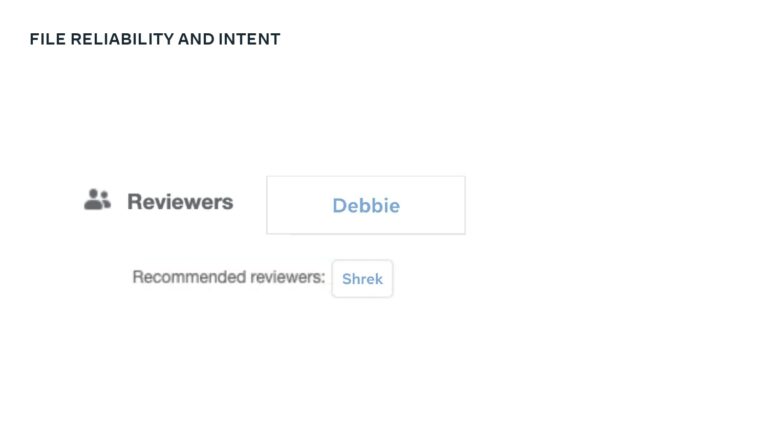
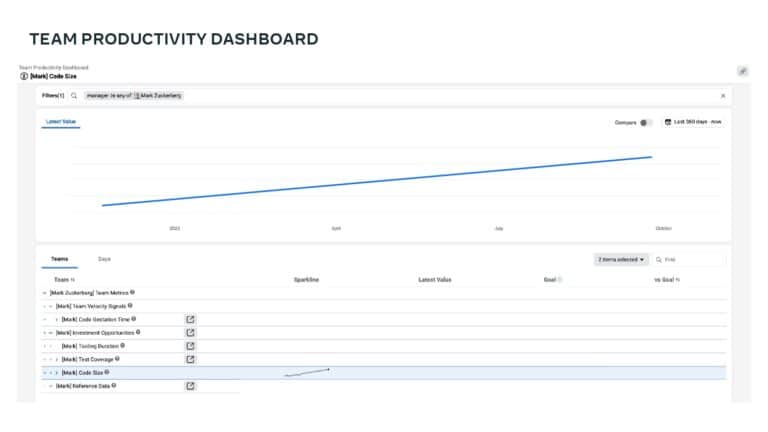
A major priority for Meta is to help their development teams move quickly and safely. To do this, they use a standardized metric that quantifies developer velocity and enables them to expose issues like regressions, flaky tests, and problematic areas of the codebase. Learn how Meta leverages DPE with practices like categorizing “diffs” to show code that is most often affected by bugs and incidents, tracking knowledge dispersal within a team, and exposing a team dashboard that helps teams visualize the state of their code, processes, and velocity.
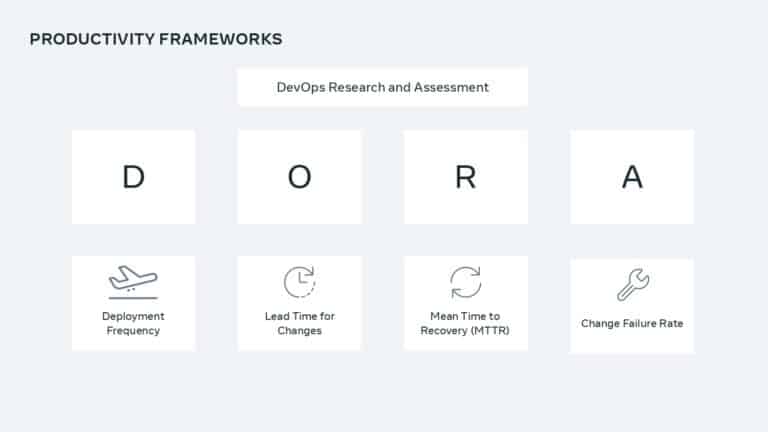
Measuring developer productivity can be hard. Actually, improving developer productivity can be even harder. Meta tackles this challenge at scale with their Productivity Organization, whose focus is on uncovering inefficient processes and removing bottlenecks.
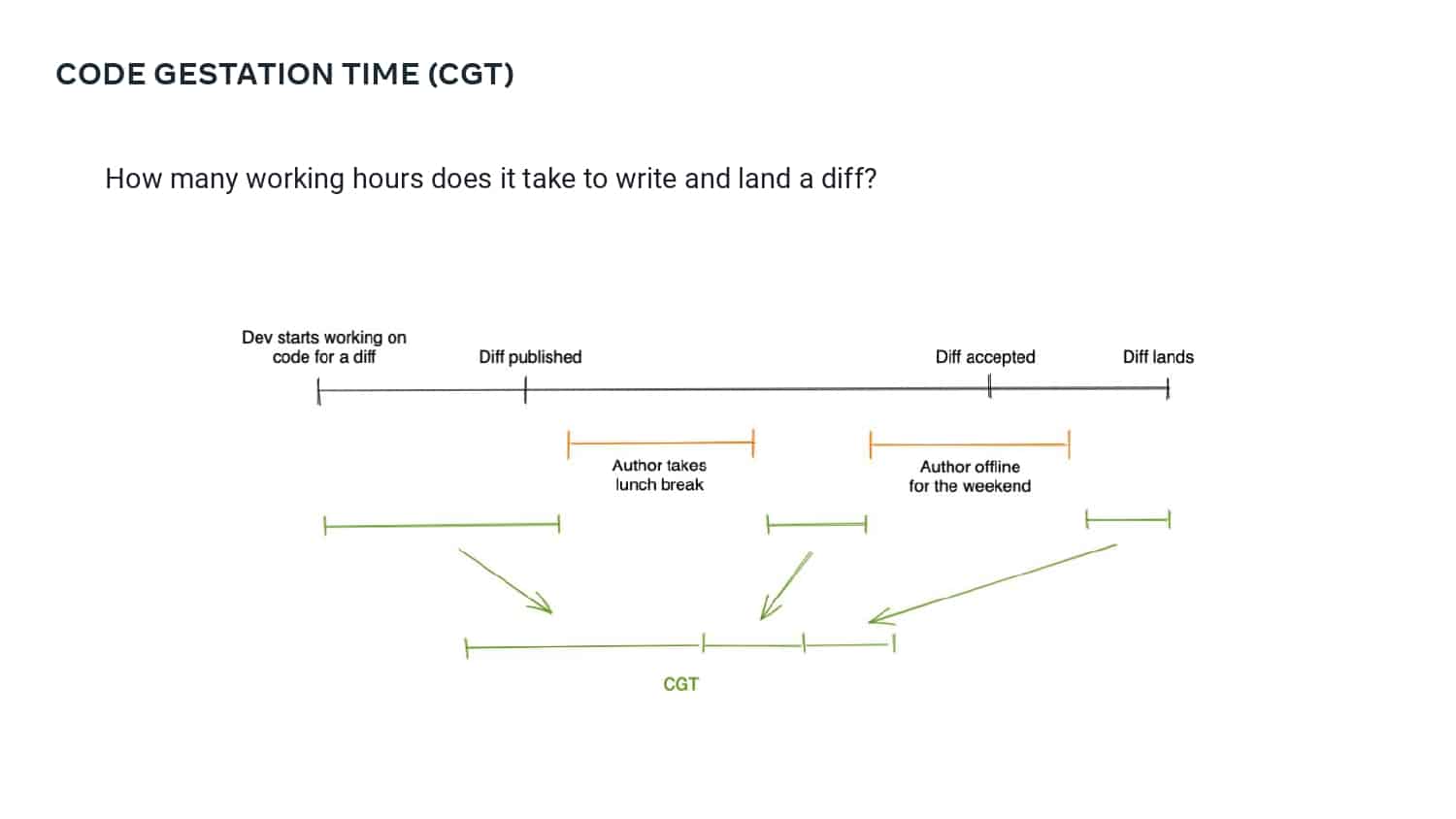
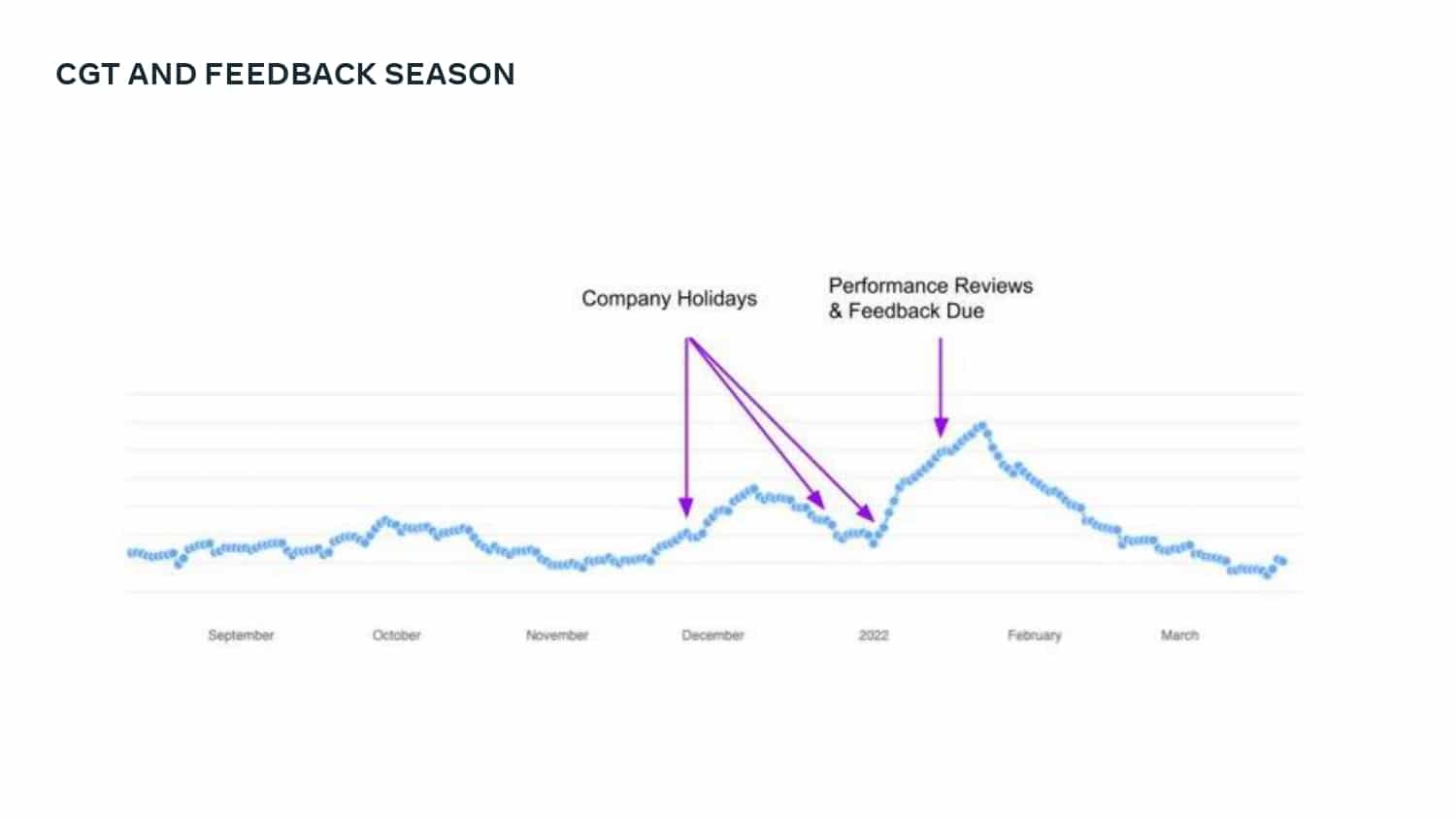
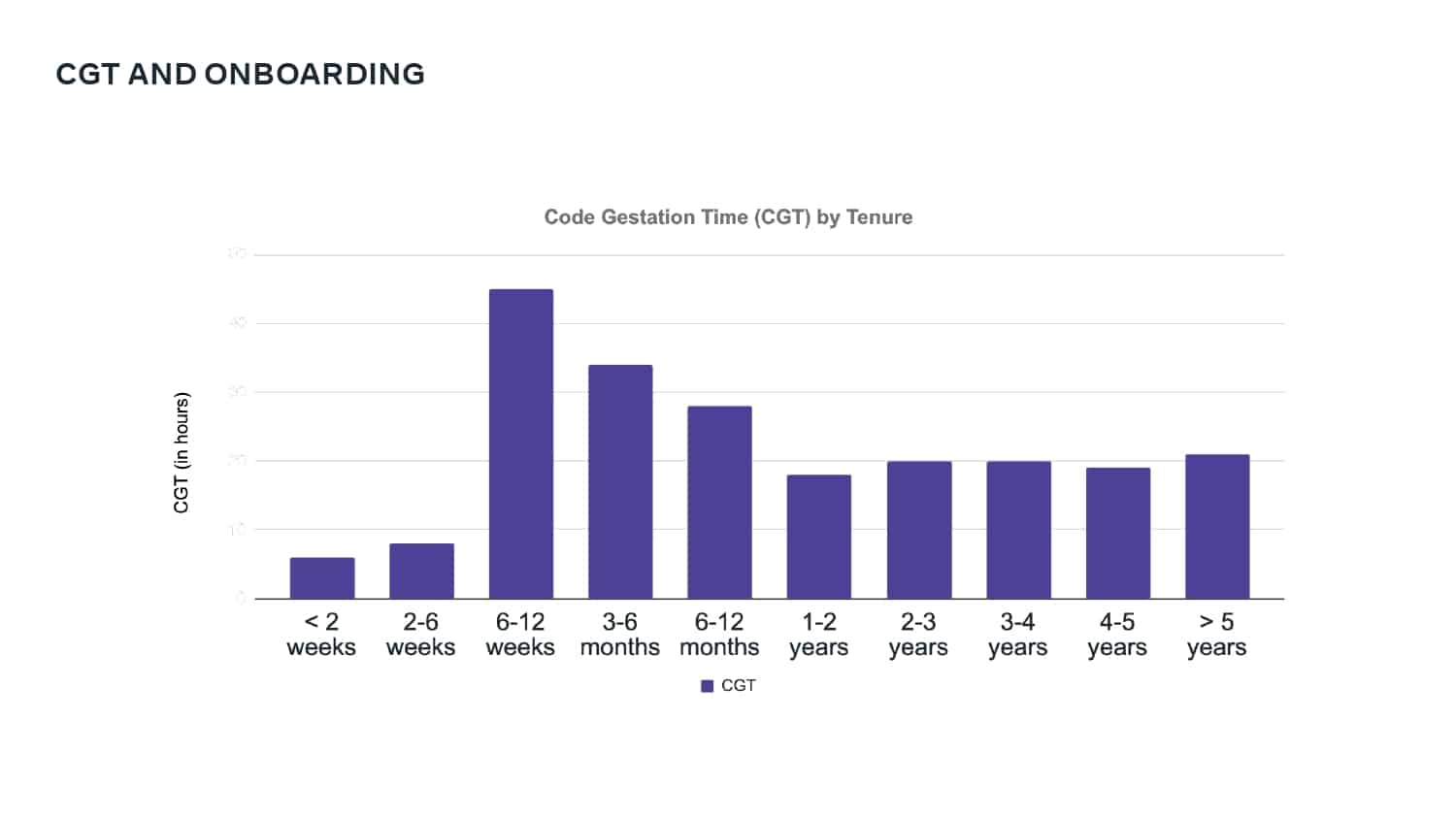
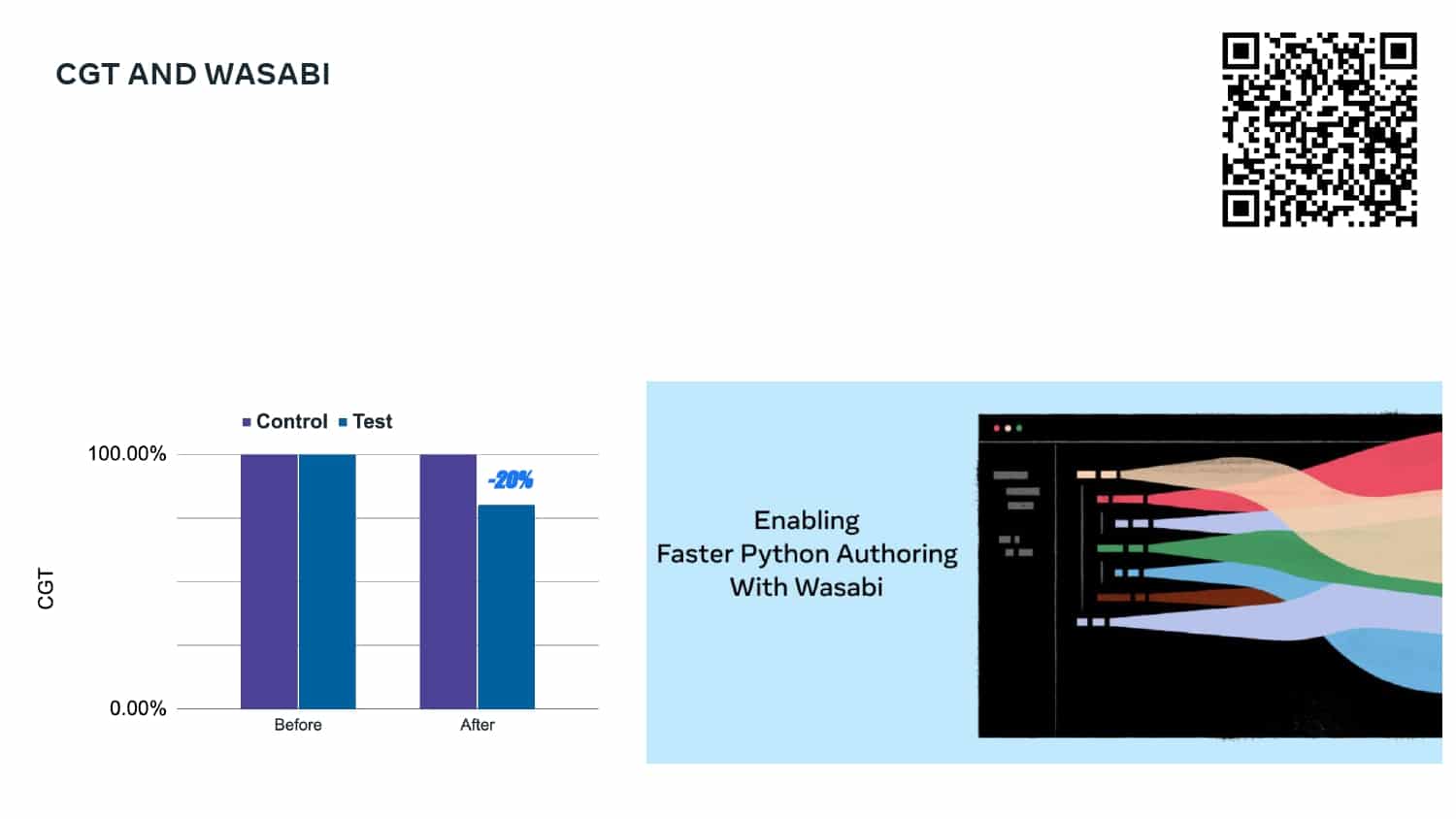
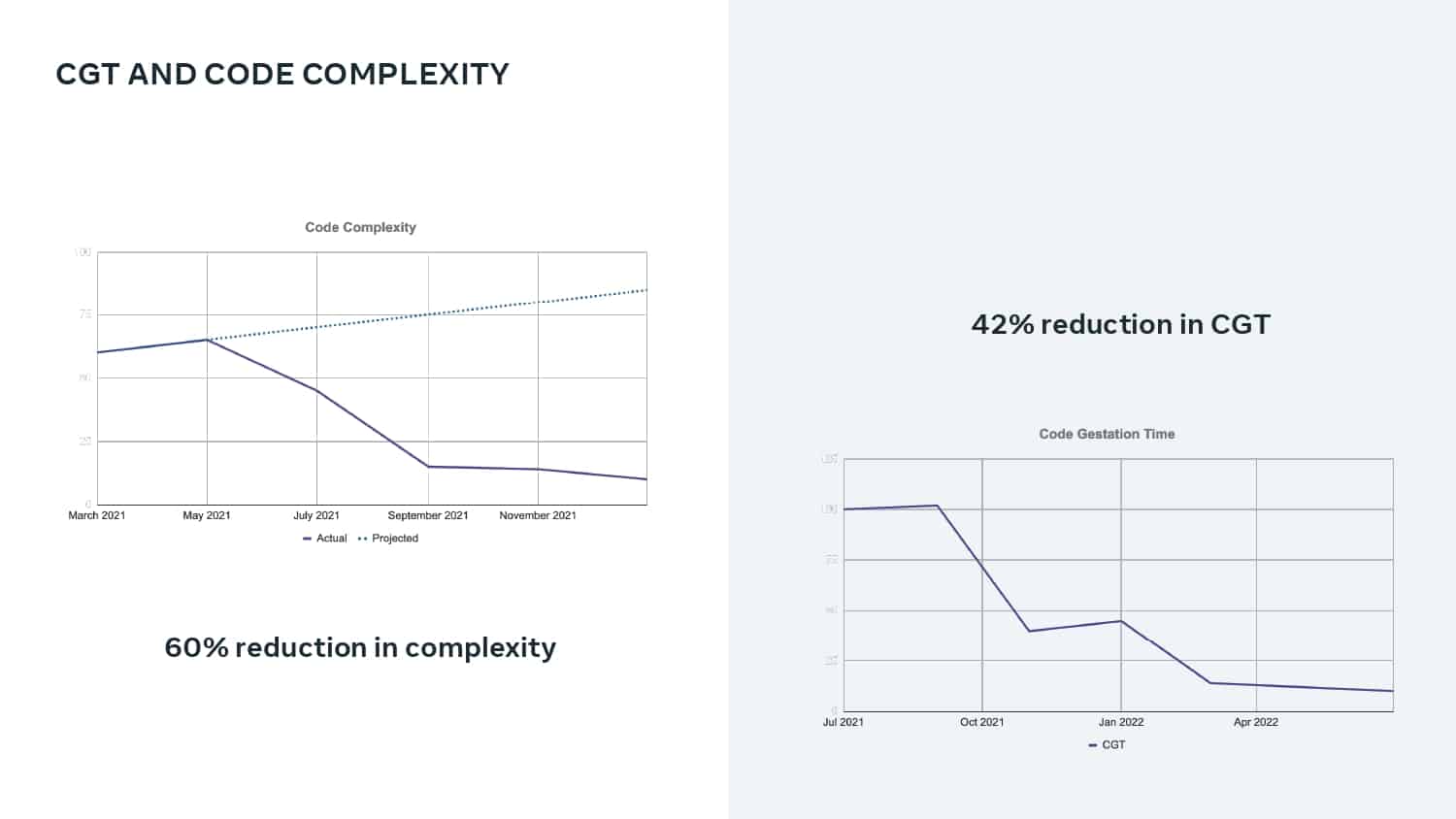
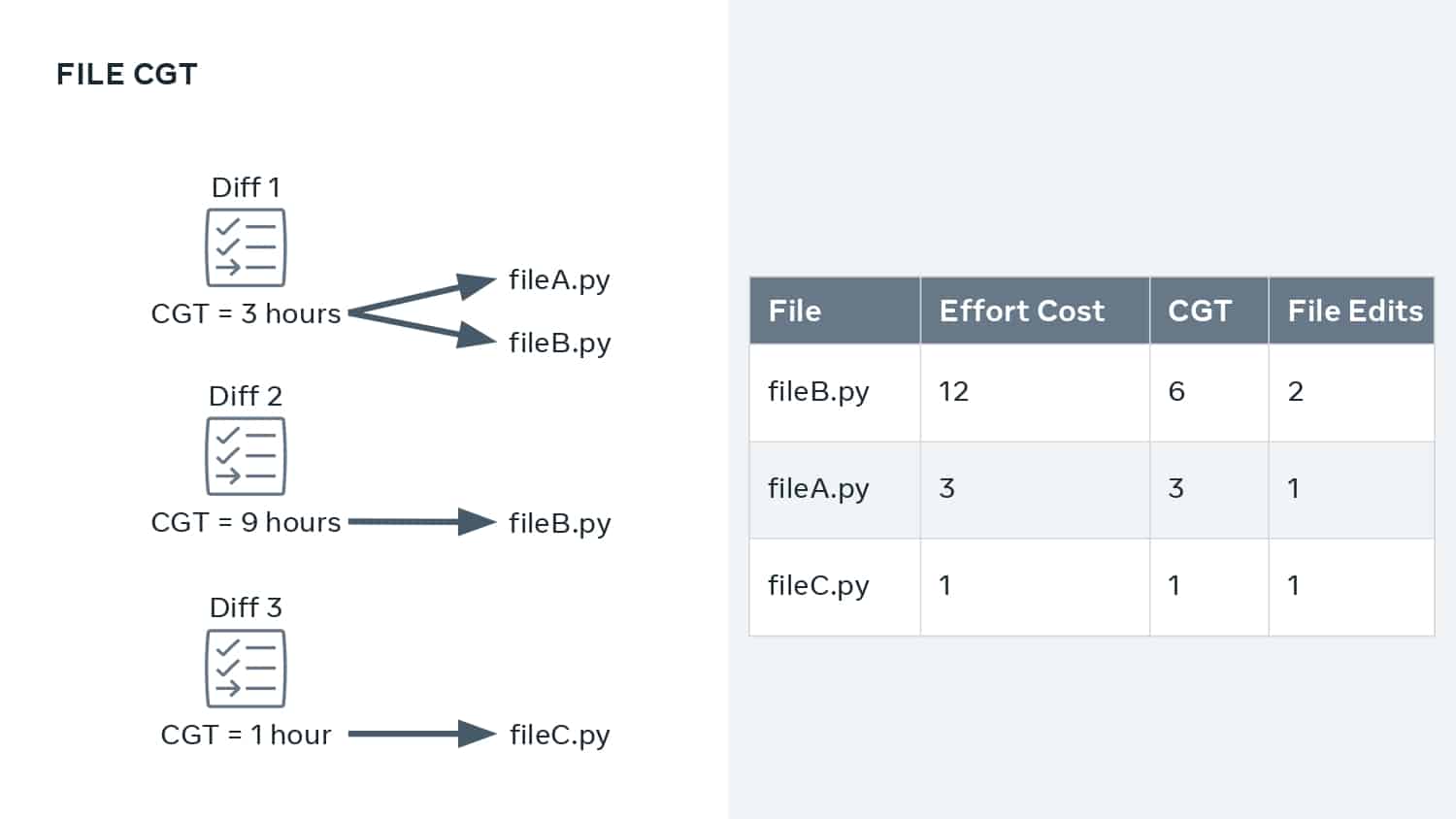
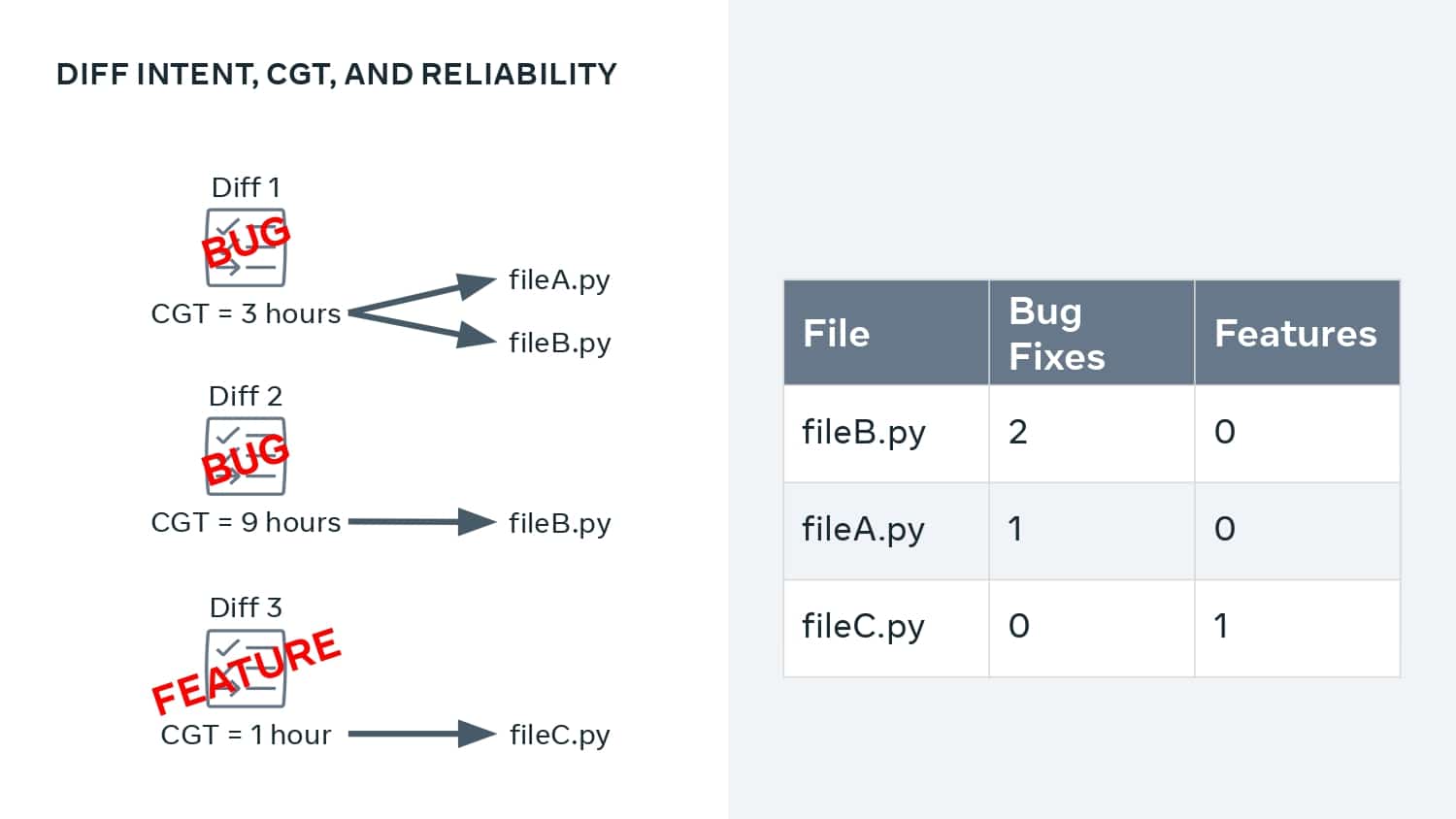
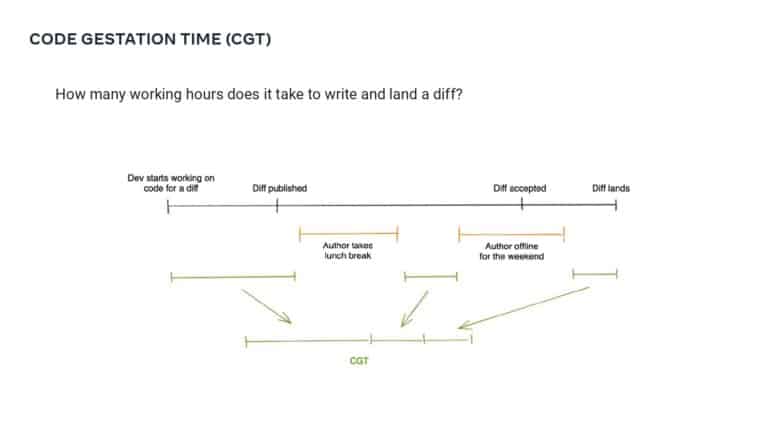
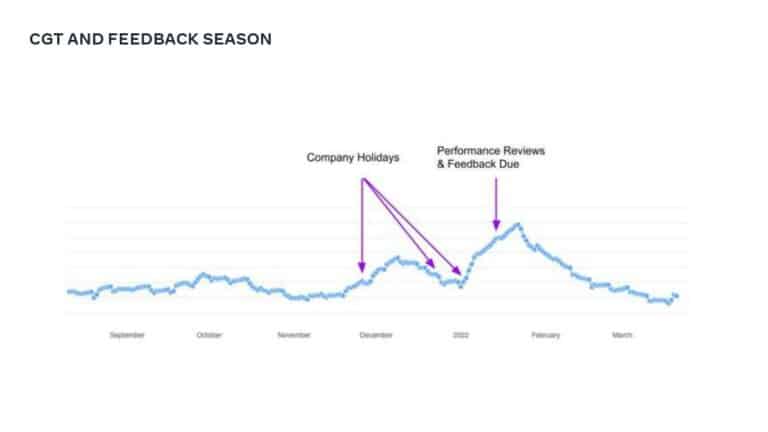
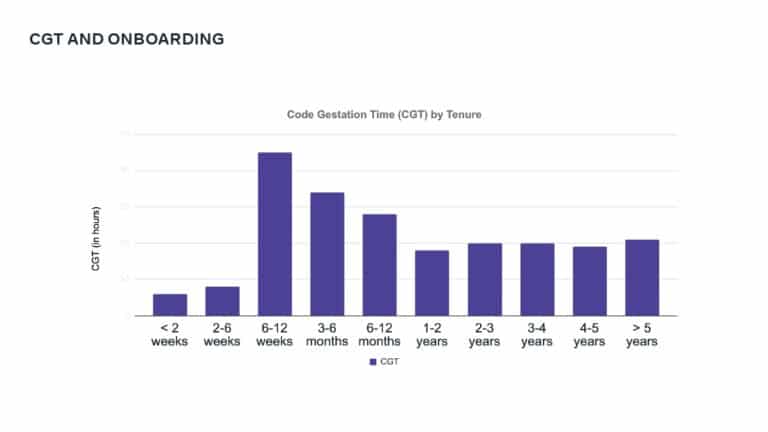
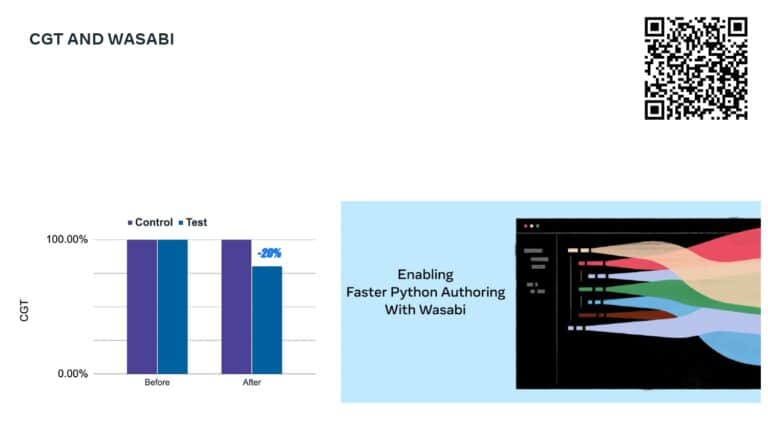
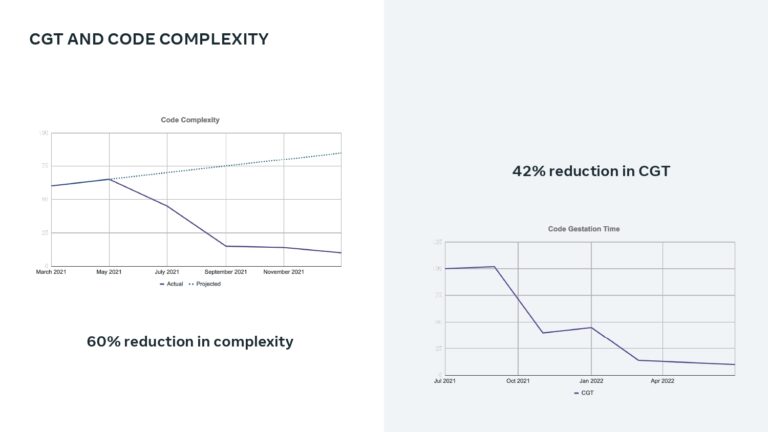
This talk explains how adopting DPE practices enabled Meta to increase developer velocity using a Code Gestation Time (CGT) metric to track, observe and optimize a growing code base across teams. You will also hear real-life stories about the challenges and pitfalls of overly focusing on small metrics while broader developer productivity challenges across teams remain unaddressed.
Karim Nakad is a Software Engineer at Meta where he works to empower developers to be able to move effortlessly through their codebases. At Meta, his group focuses on improving developer productivity and experience by focusing on code quality and tooling.

Gradle Enterprise customers utilize Gradle Enterprise Build Scan ™ to rapidly get deep insights into metrics like build and test performance, flaky tests, external dependencies, failures and regressions. From there, features like Build Cache reduce build and test times by avoiding re-running code that hasn’t changed since the last successful build, and Test Distribution further improves test times (often 90% of the entire build process) by parallelizing tests across all available infrastructure. You can learn more about these features by running a free Build Scan™ for Maven and Gradle Build Tool, watching videos, and registering for our free instructor-led Build Cache deep-dive training.