

What’s inside?
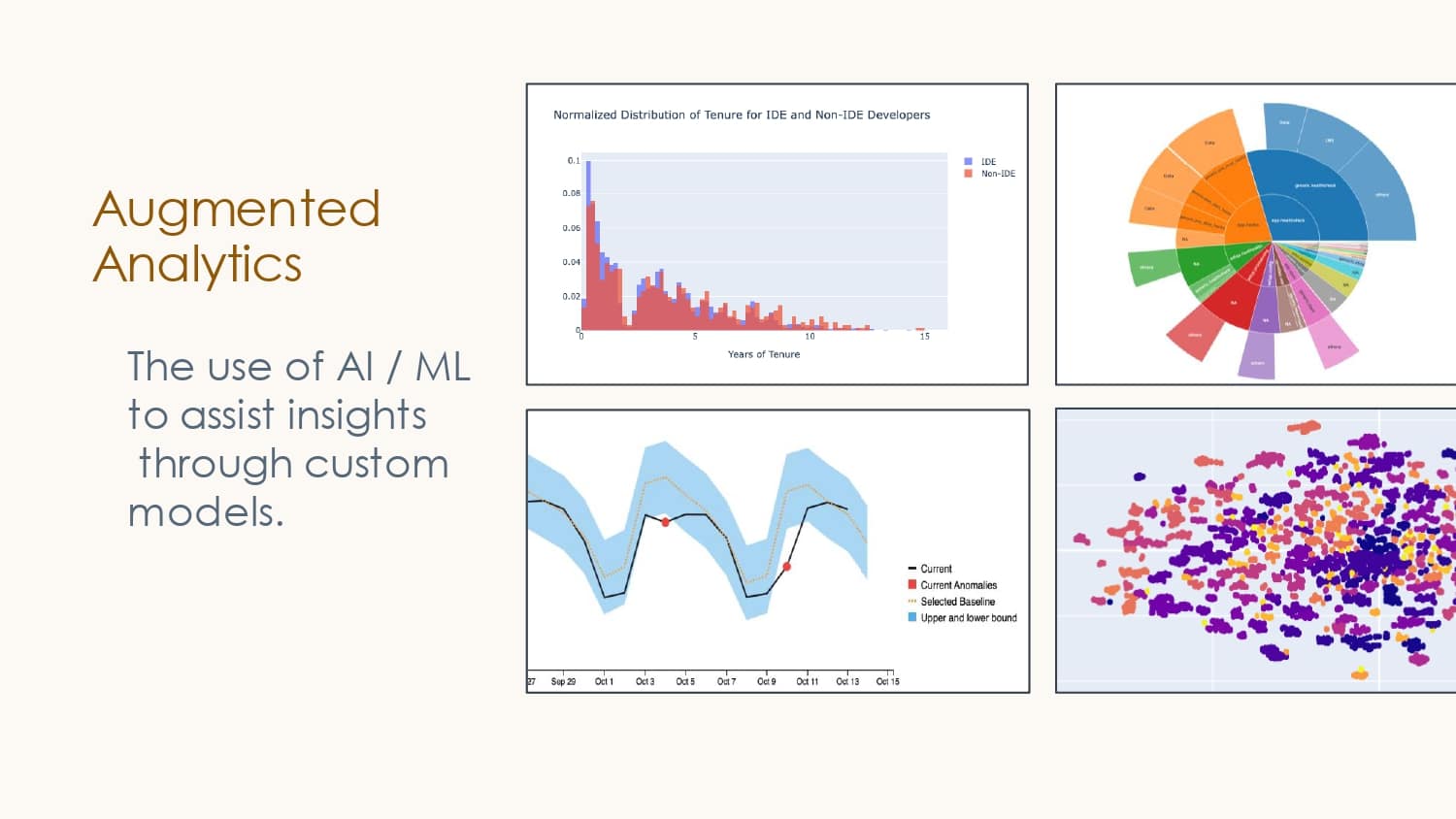
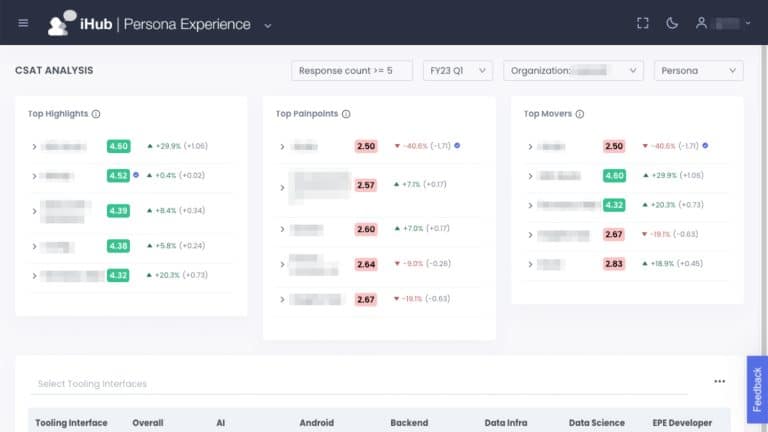
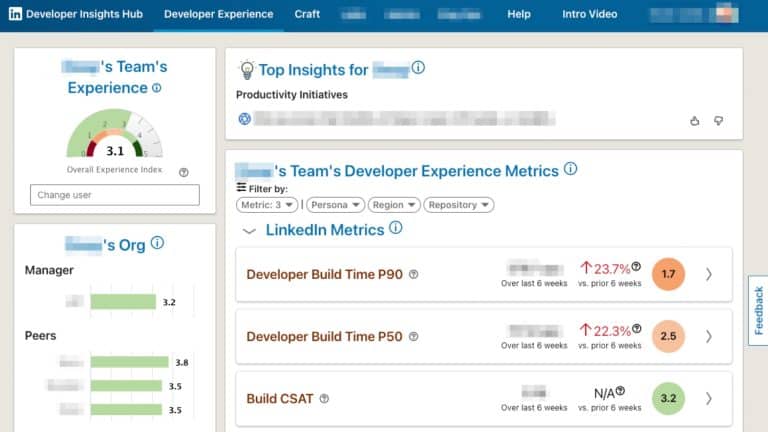
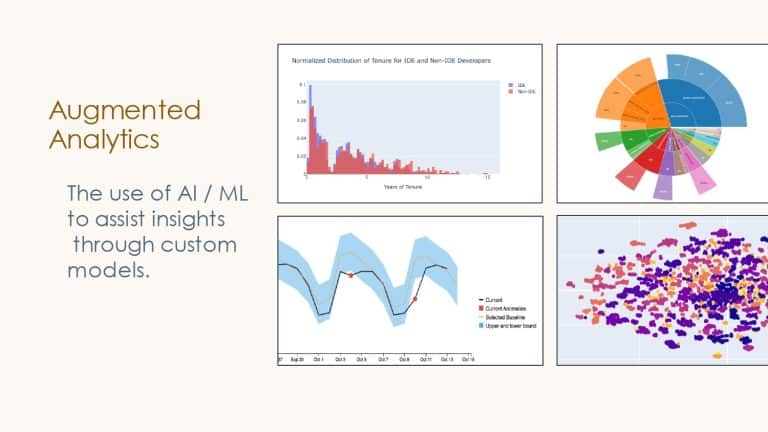
At LinkedIn, many diverse teams exist–backend, frontend, mobile, etc, each with patterns and nuances that no single team can understand. Leveraging four kinds of analytics–descriptive, diagnostic, predictive, and prescriptive–the Developer Insights team is now building next-generation developer experience dashboards that leverage modern data science and AI models.
At LinkedIn, many diverse teams exist–backend, frontend, mobile, etc, each with patterns and nuances that no single team can understand. Leveraging four kinds of analytics–descriptive, diagnostic, predictive, and prescriptive–the Developer Insights team is now building next-generation developer experience dashboards that leverage modern data science and AI models.
Summit Producer’s Highlight
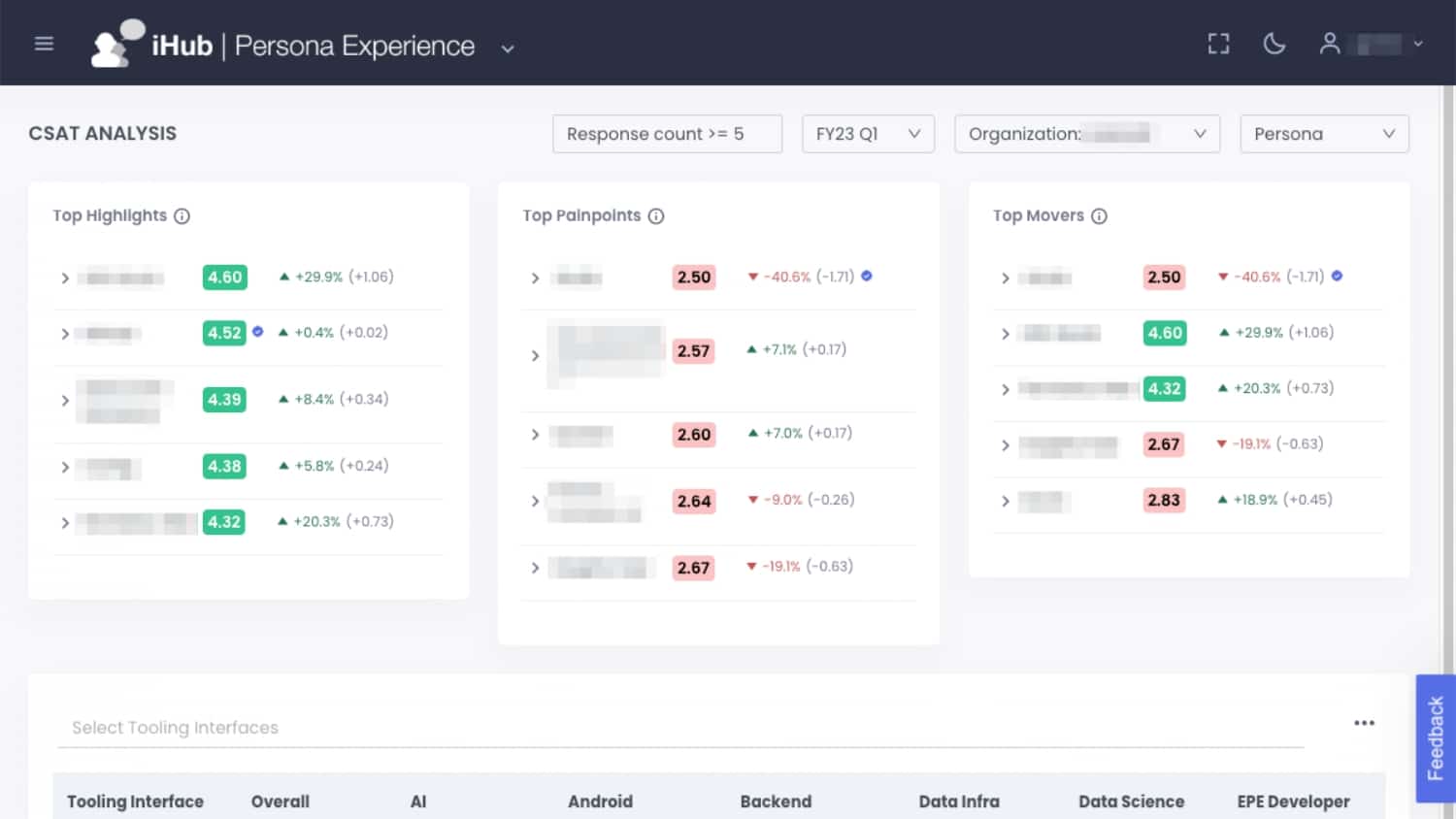
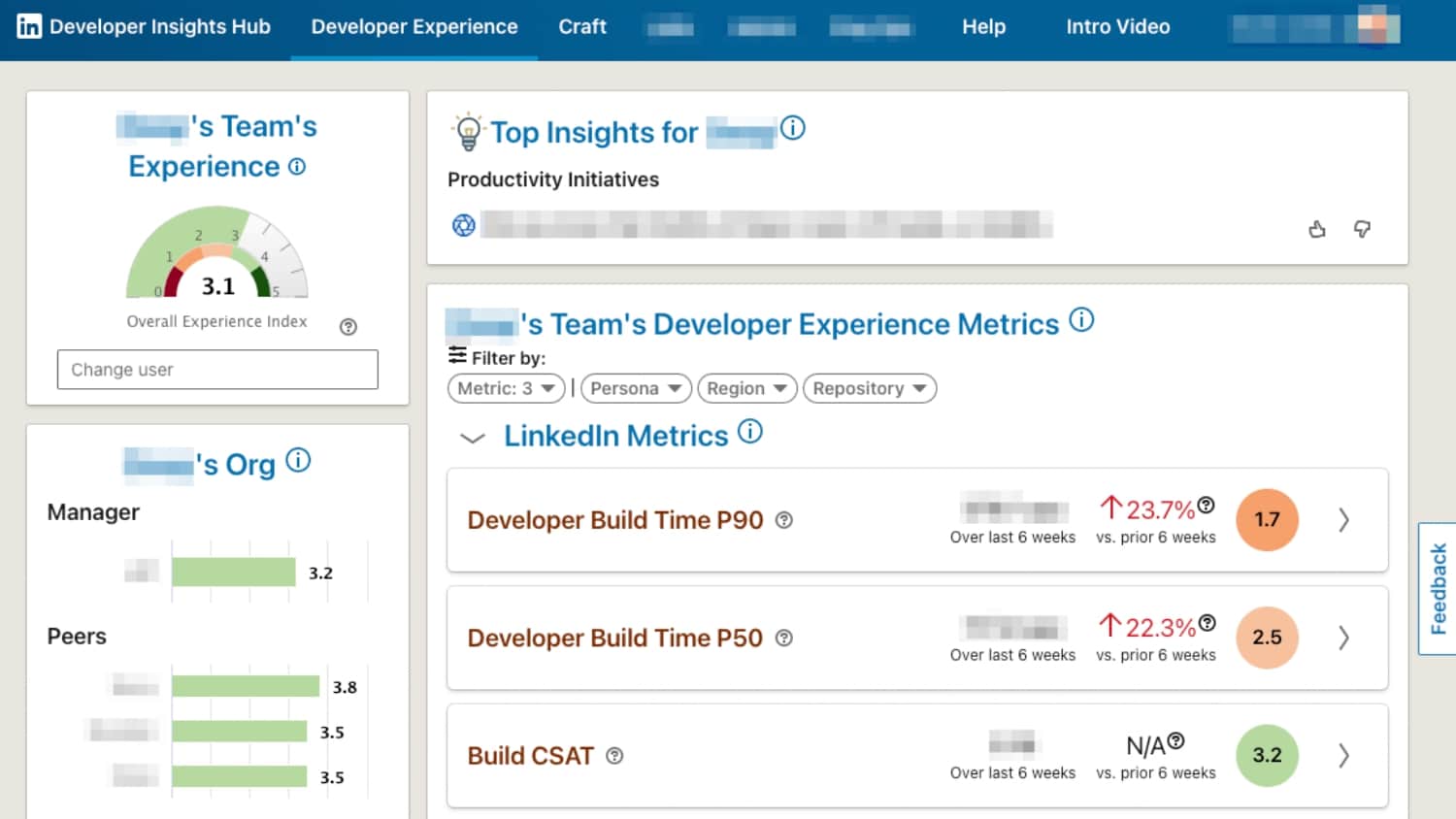
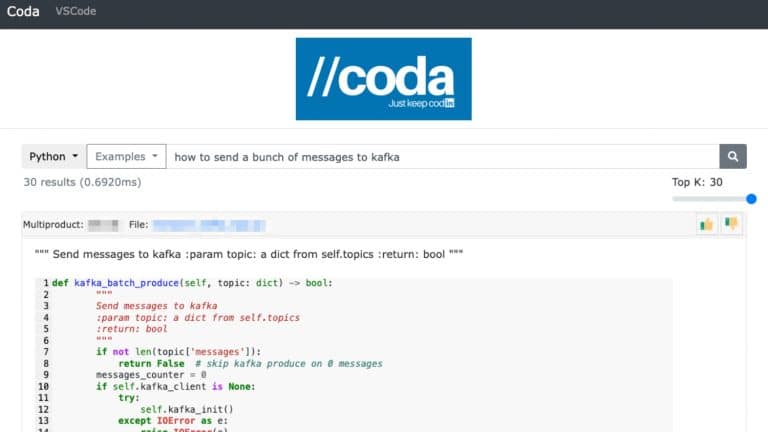
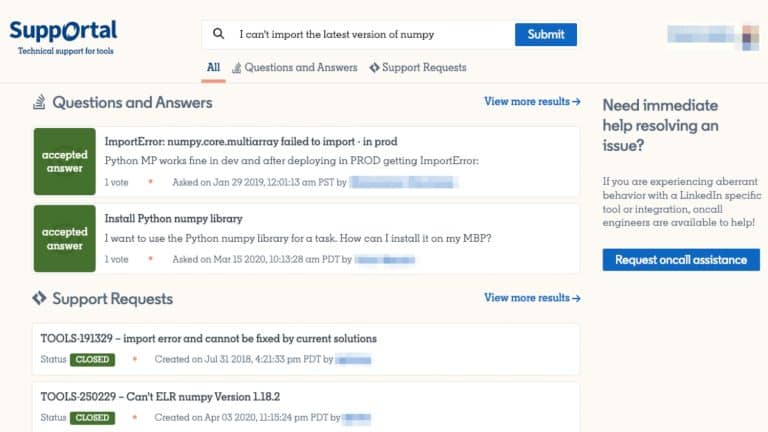
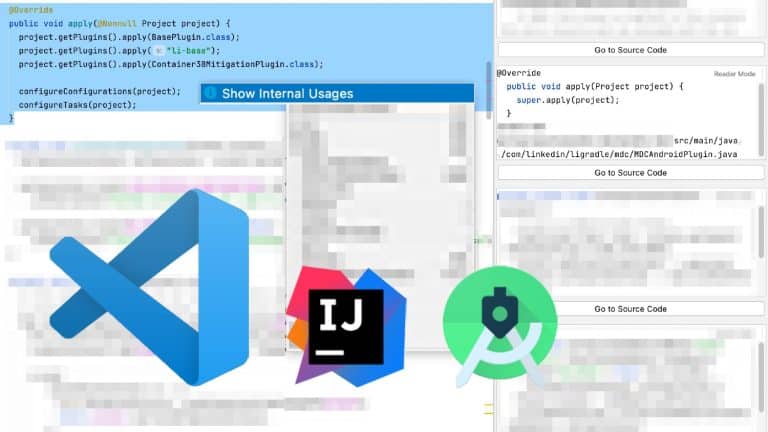
The Linkedin Developer Insights team shares how they capture observability/telemetry metrics from builds, CI jobs, merges, artifacts, and source repositories, across all developers/platforms/projects to build developer experience dashboards with actionable insights for application teams.
The Linkedin Developer Insights team shares how they capture observability/telemetry metrics from builds, CI jobs, merges, artifacts, and source repositories, across all developers/platforms/projects to build developer experience dashboards with actionable insights for application teams.
About Grant
Grant Jenks is a technical leader with 15 years of experience in turning research and product ideas into high-performance software. For the last three years, he has worked at LinkedIn in the Developer Productivity and Happiness organization within the Developer Insights team. Developer Insights works like a “Fitbit for engineering teams” to identify and improve pain points in developer workflows. Prior to LinkedIn, Grant founded an adtech analytics company and applied his expertise in distributed systems and machine learning to predict search engine rankings. He pivoted from his initial role as a compiler engineer on the Midori OS research and incubation project at Microsoft to his current work in analytics.
Grant Jenks is a technical leader with 15 years of experience in turning research and product ideas into high-performance software. For the last three years, he has worked at LinkedIn in the Developer Productivity and Happiness organization within the Developer Insights team. Developer Insights works like a “Fitbit for engineering teams” to identify and improve pain points in developer workflows. Prior to LinkedIn, Grant founded an adtech analytics company and applied his expertise in distributed systems and machine learning to predict search engine rankings. He pivoted from his initial role as a compiler engineer on the Midori OS research and incubation project at Microsoft to his current work in analytics.
About Shailesh
Shailesh Jannu is a hands-on technology leader with more than 20 years of experience in engineering, architecture, product management and product development. He has a passion for developing solutions using AI, Machine learning, IoT and Big Data. He is an expert in building and releasing world-class enterprise software applications, as well as platform, middleware and infrastructure components for leading global enterprise brands.
Shailesh Jannu is a hands-on technology leader with more than 20 years of experience in engineering, architecture, product management and product development. He has a passion for developing solutions using AI, Machine learning, IoT and Big Data. He is an expert in building and releasing world-class enterprise software applications, as well as platform, middleware and infrastructure components for leading global enterprise brands.
More information related to this topic
Gradle Enterprise
Solutions for Developer Productivity Engineering

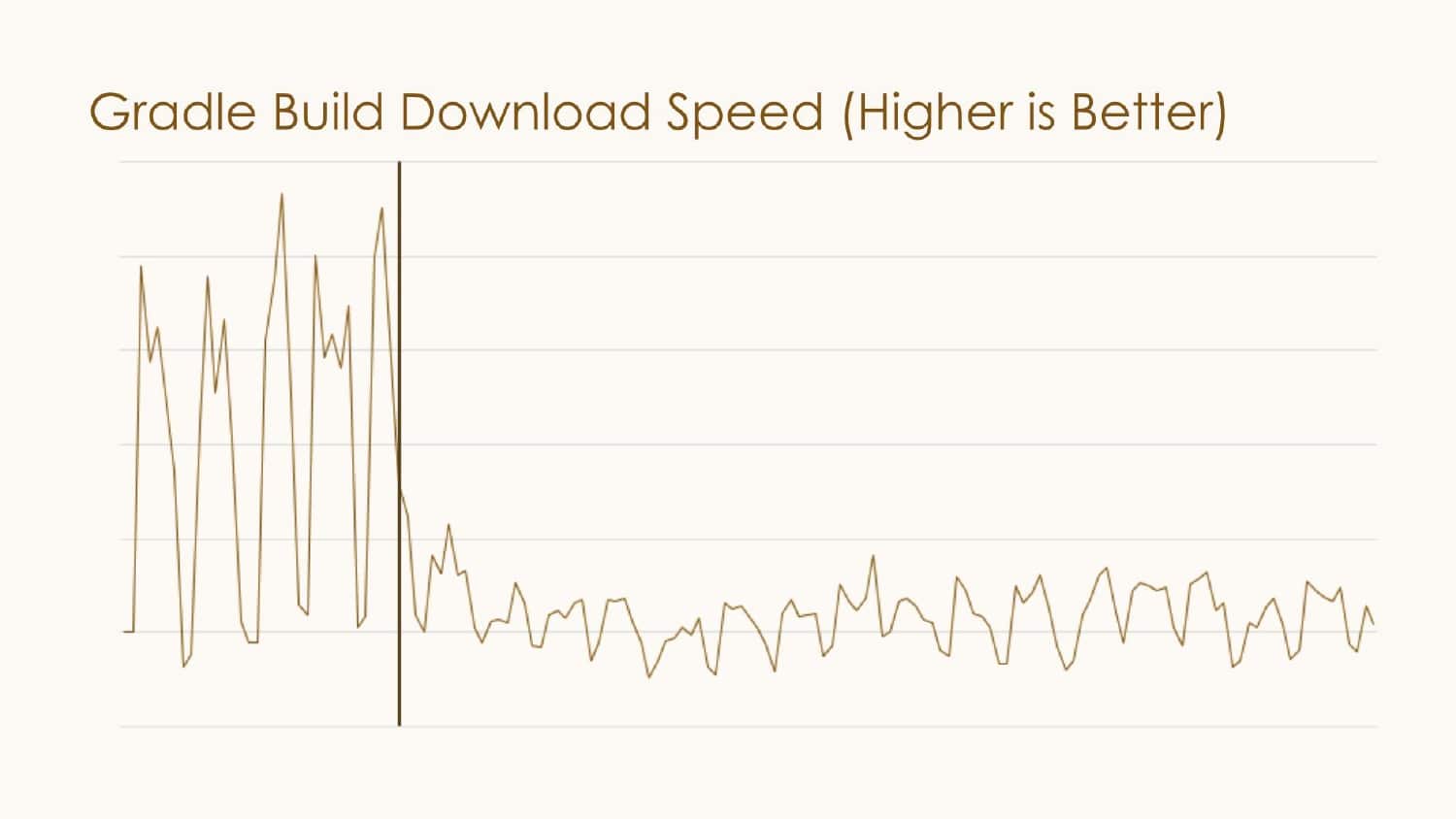
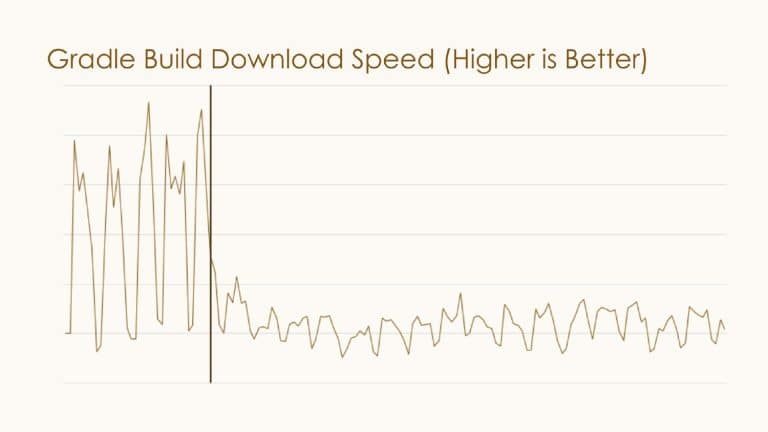
At LinkedIn, the team uses Gradle Enterprise along with other tools to capture developer data and transform it into actionable goals that optimize developer productivity engineering efforts. You can also use the Gradle Enterprise API to collect structured data from a Build Scan™ and aggregate it across all builds and tests, whether from developer machines or CI. This data includes dependency management, system resources, and infrastructure, among other things.
Slides






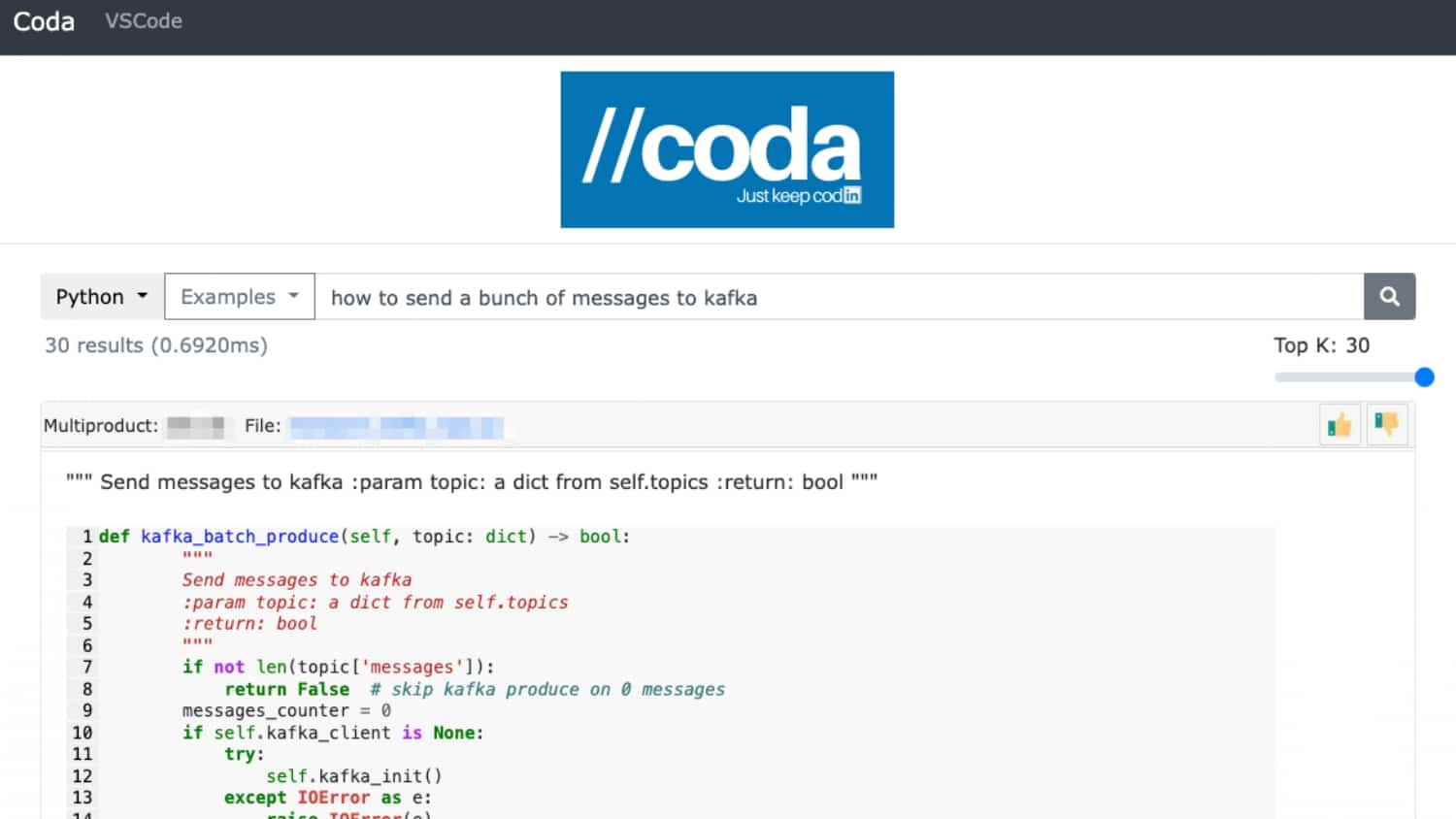
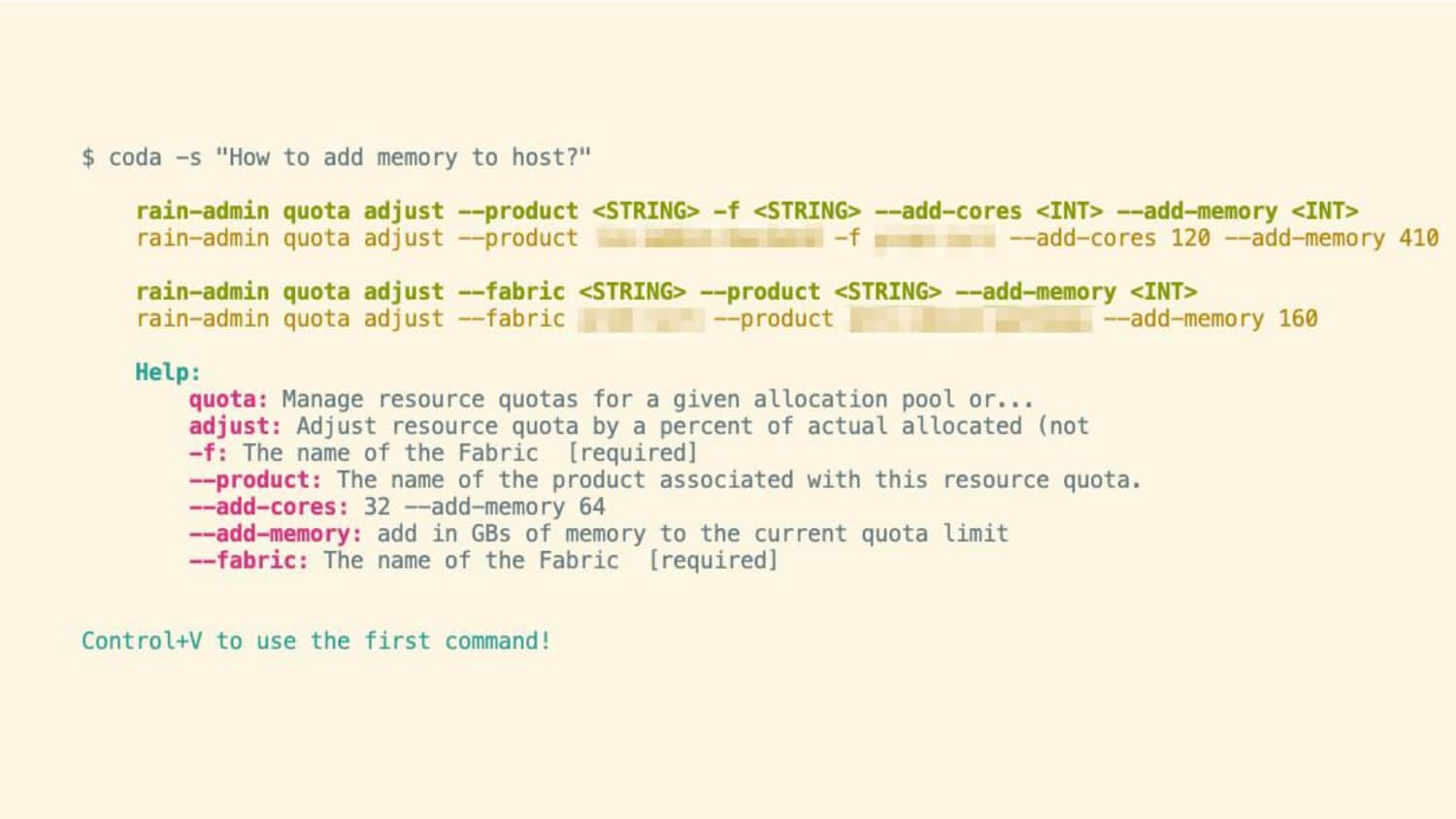
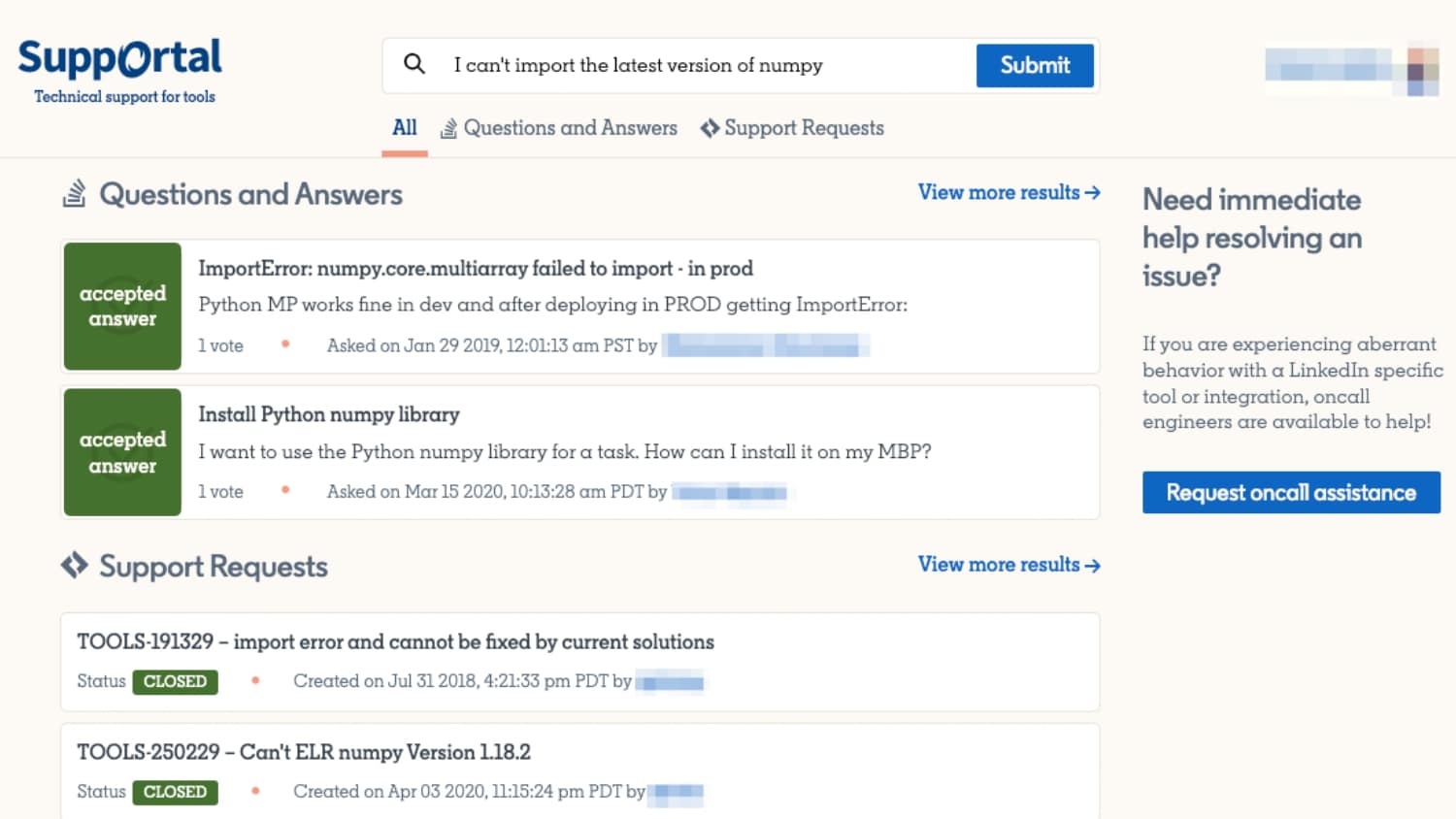

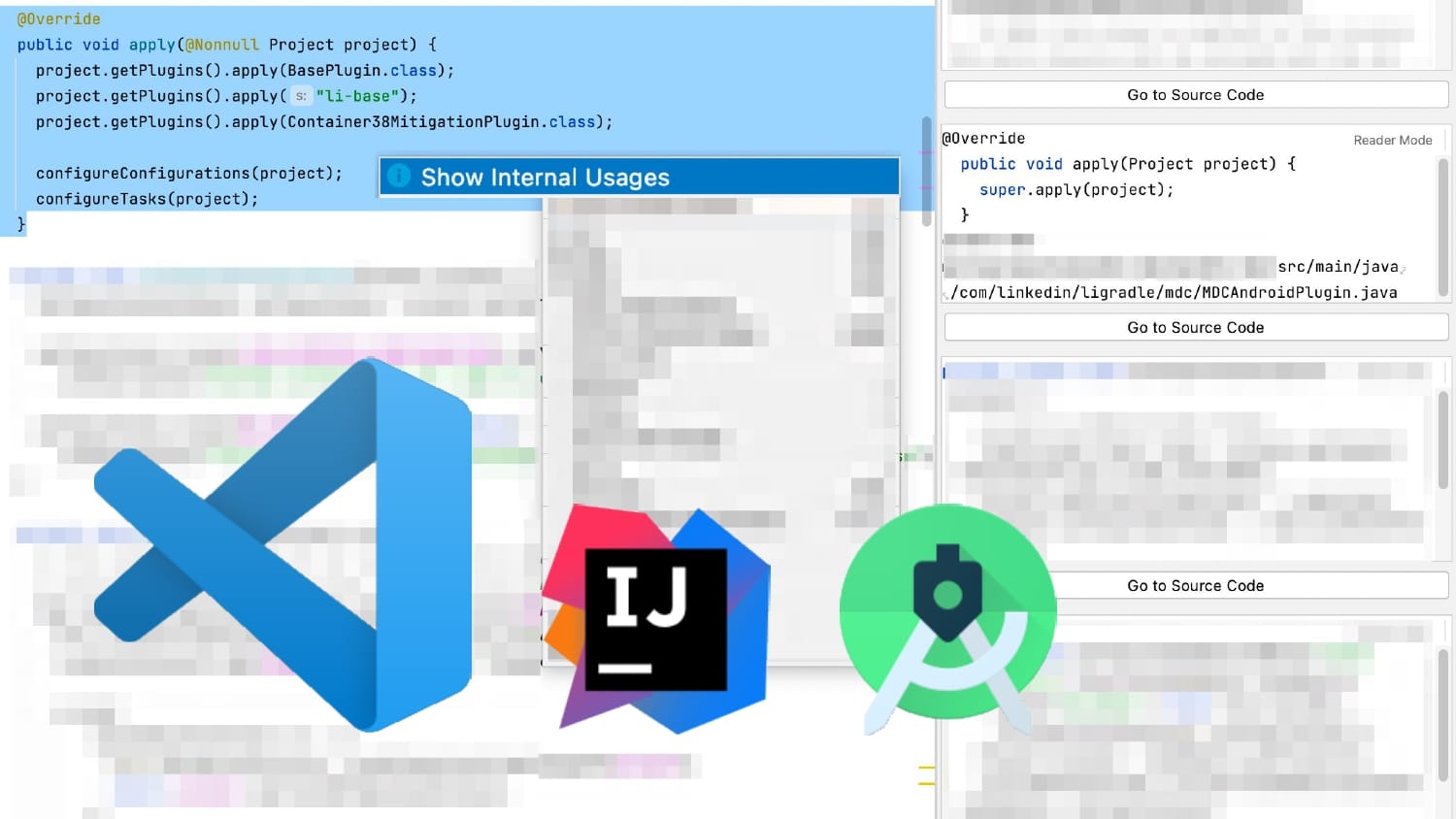










Interested in Developer Productivity Engineering?

Learn How to Leverage the Gradle Enterprise API
5-minute read

DPE Lowdown with LinkedIn’s Grant Jenks
1-hour watch

Gradle Enterprise for Developers
1-hour training