In this presentation, Square describes why they embraced Isolated Development to scale their Android and iOS codebase horizontally while keeping engineers productive. By running single features in a development sandbox environment and applying DPE practices like build scans and build caching, Square opened up many opportunities for improving developer productivity as their application grew. Watch how they turned these concepts into reality, how teams adopted these isolated development apps, and how they reduced build and IDE sync times by 10X.
Note: while Ralf is currently at Amazon, this talk was prepared when we worked at Square.
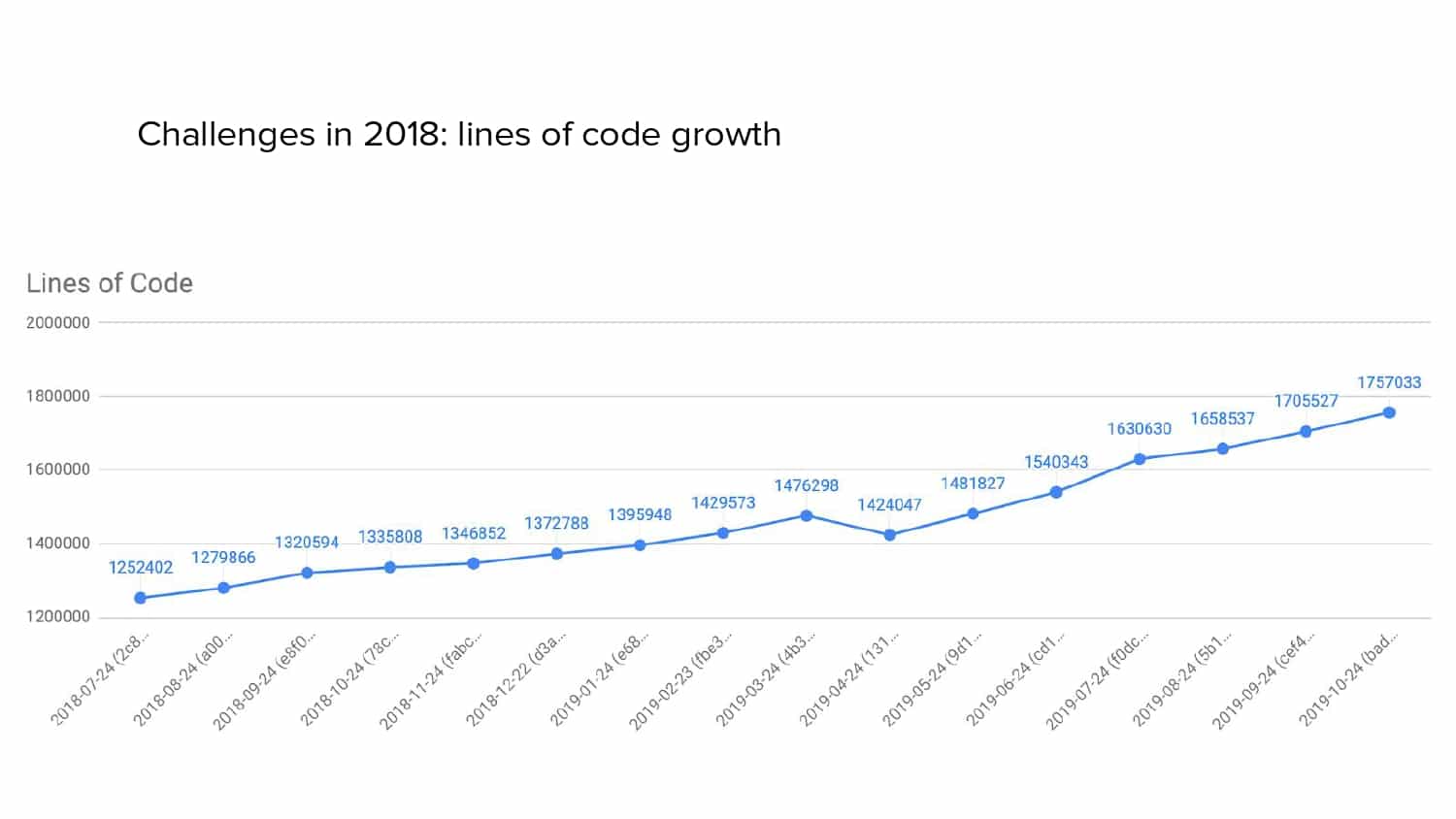
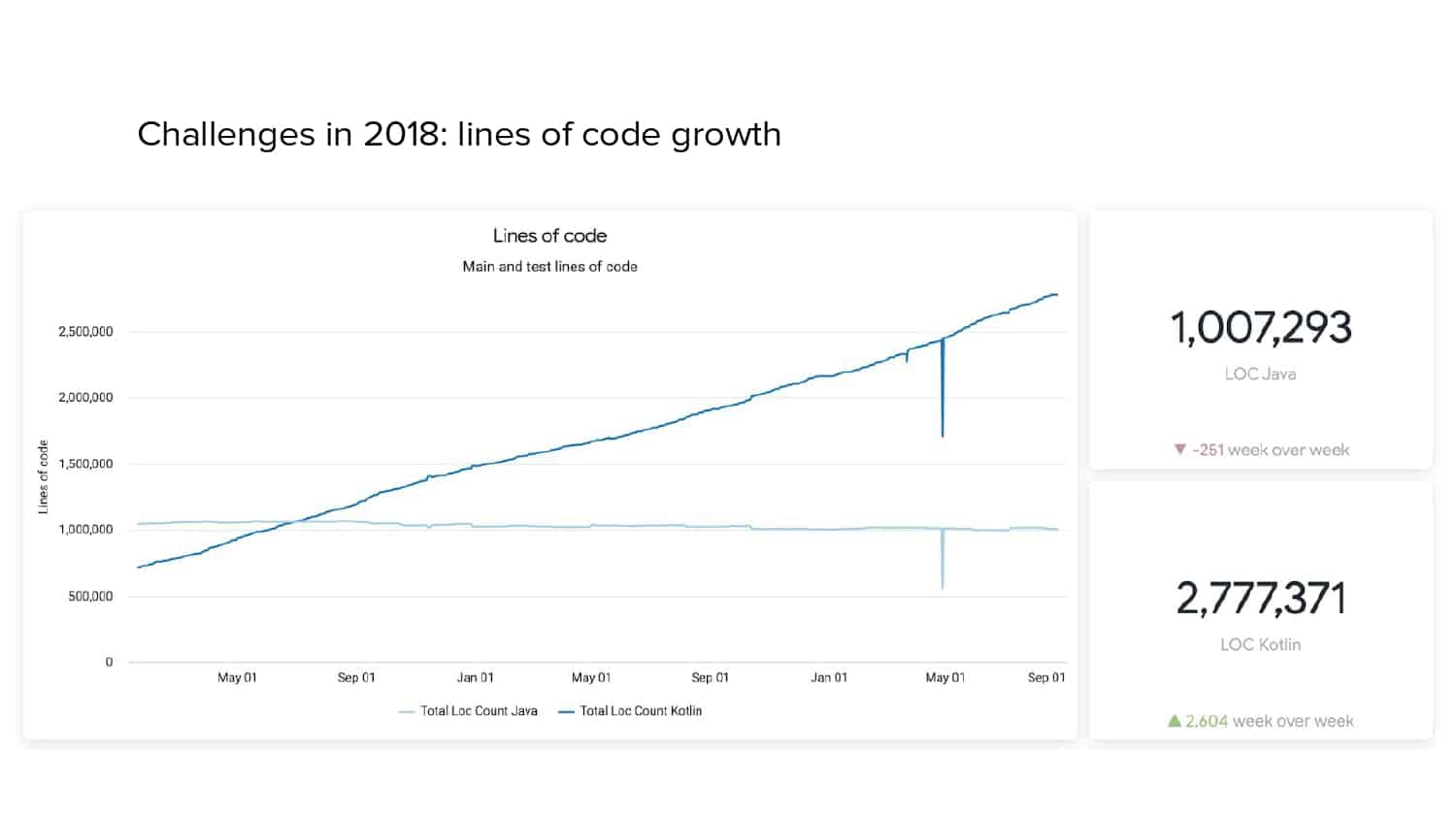
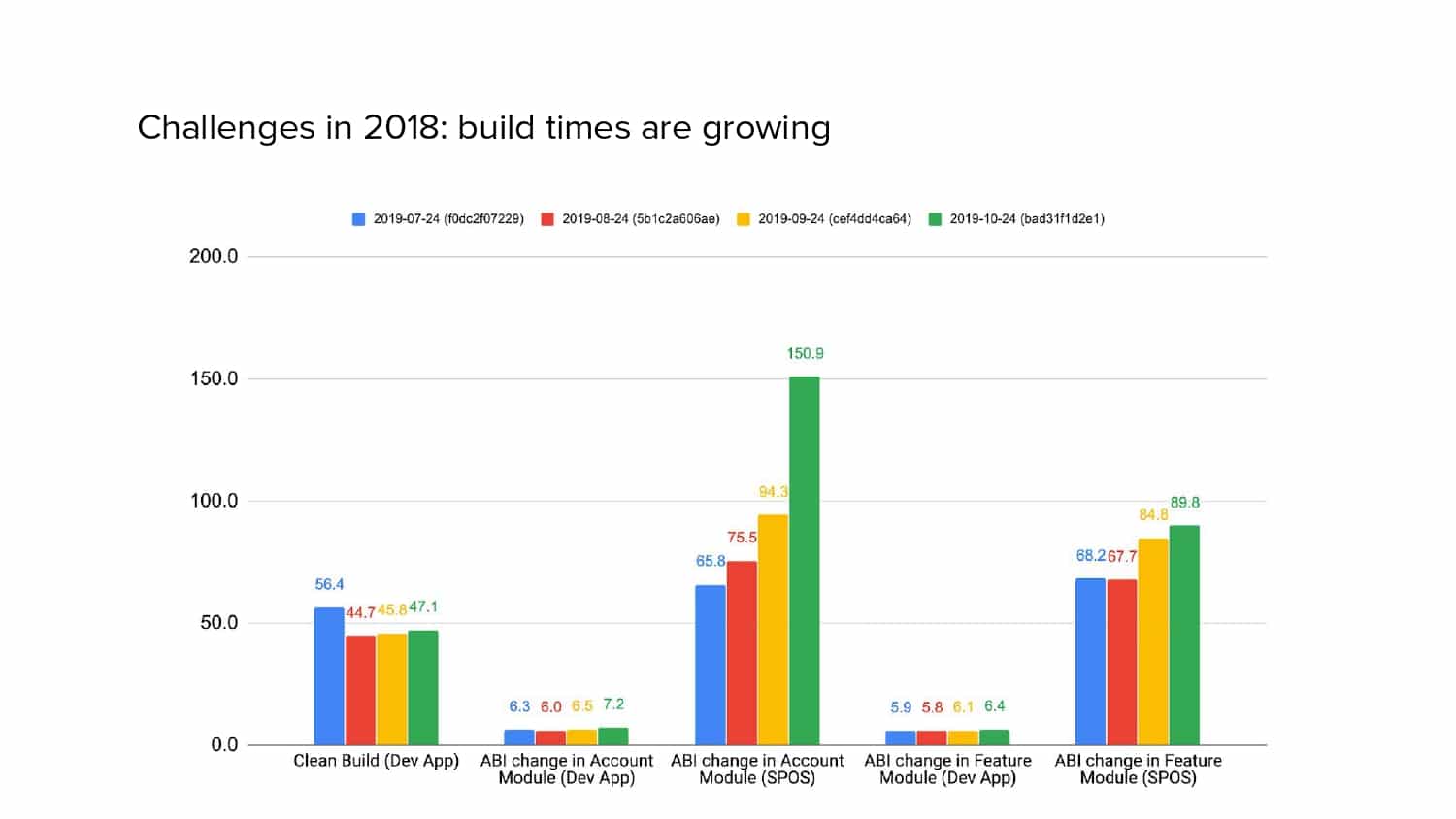
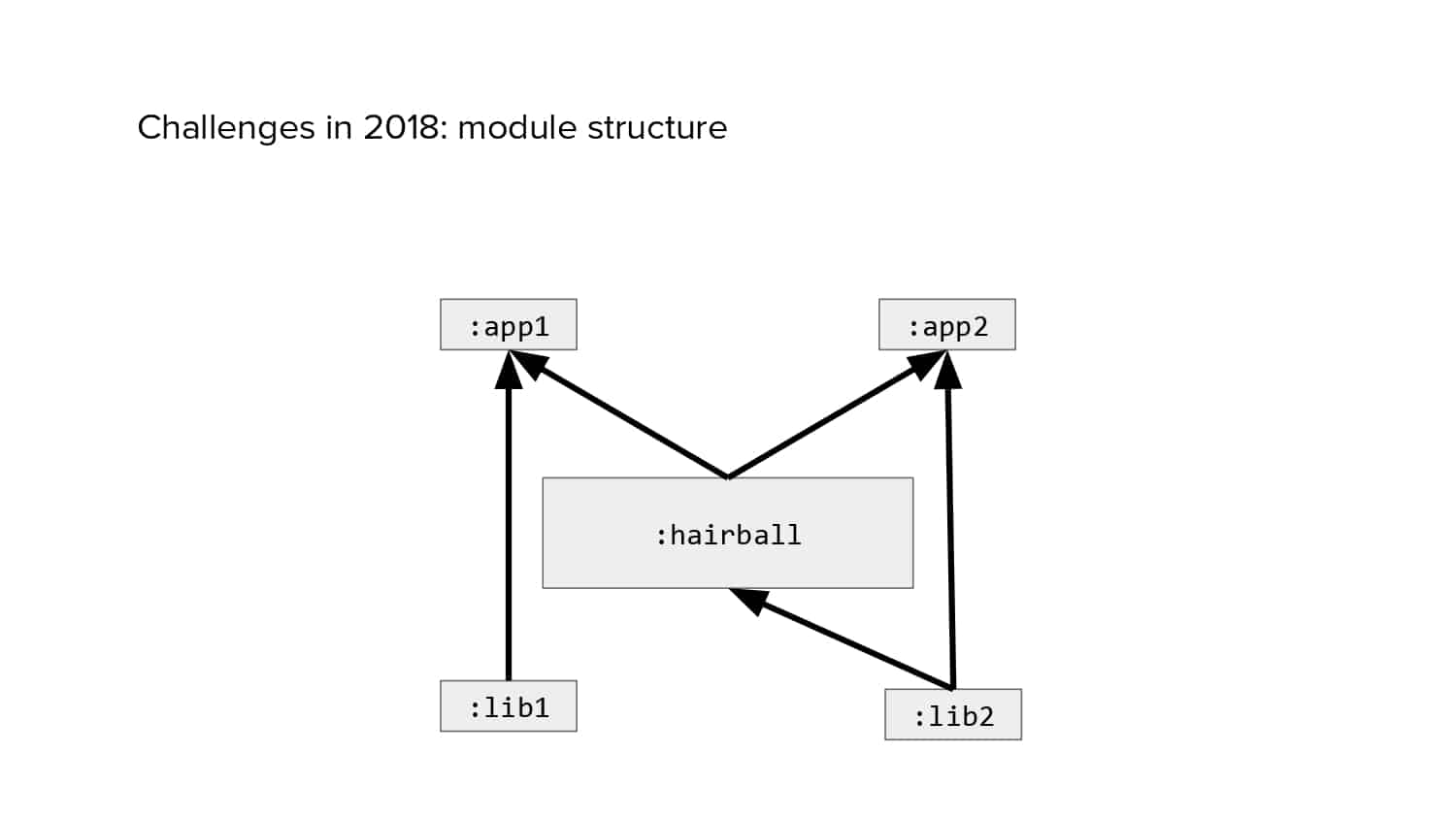
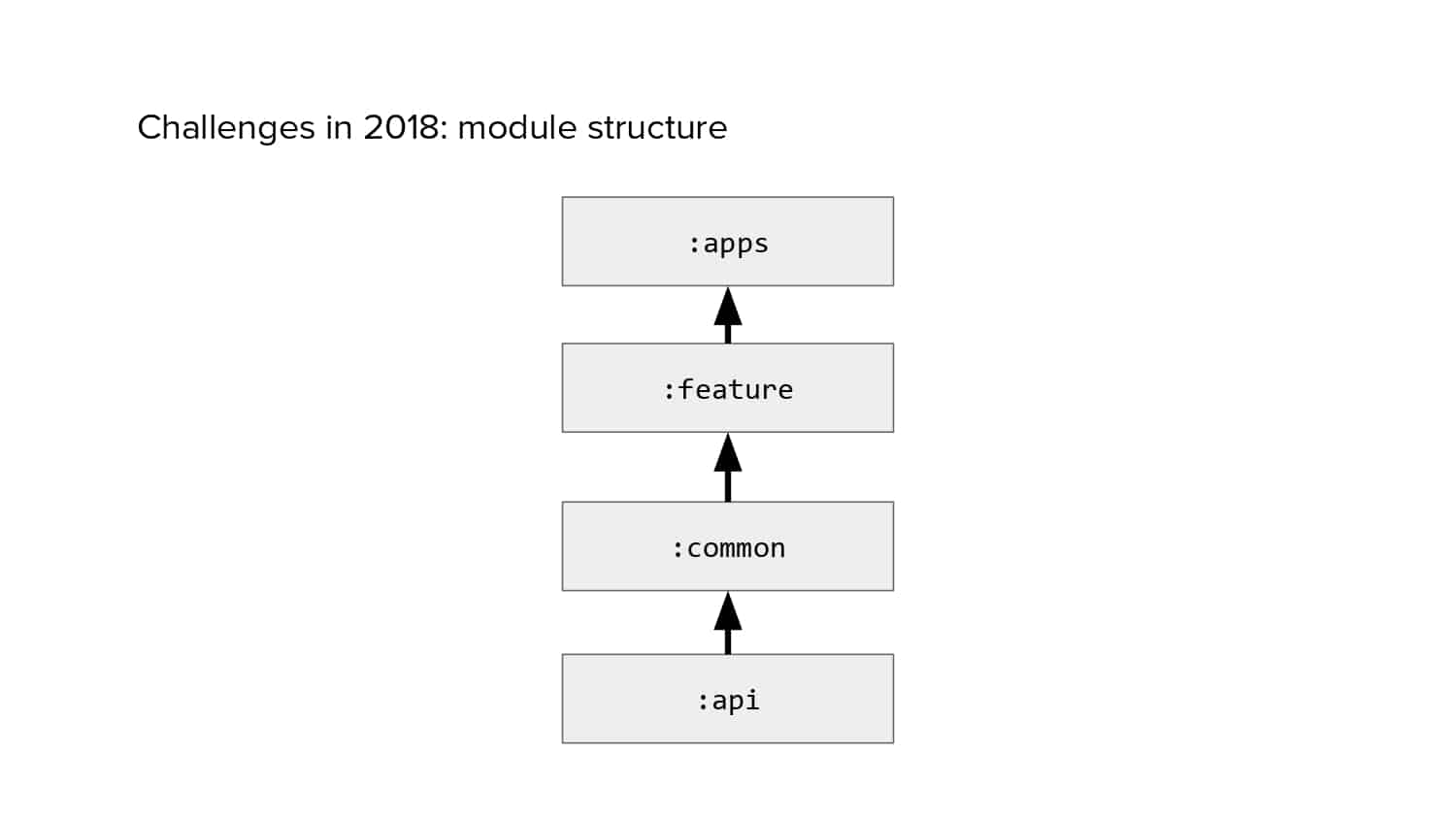
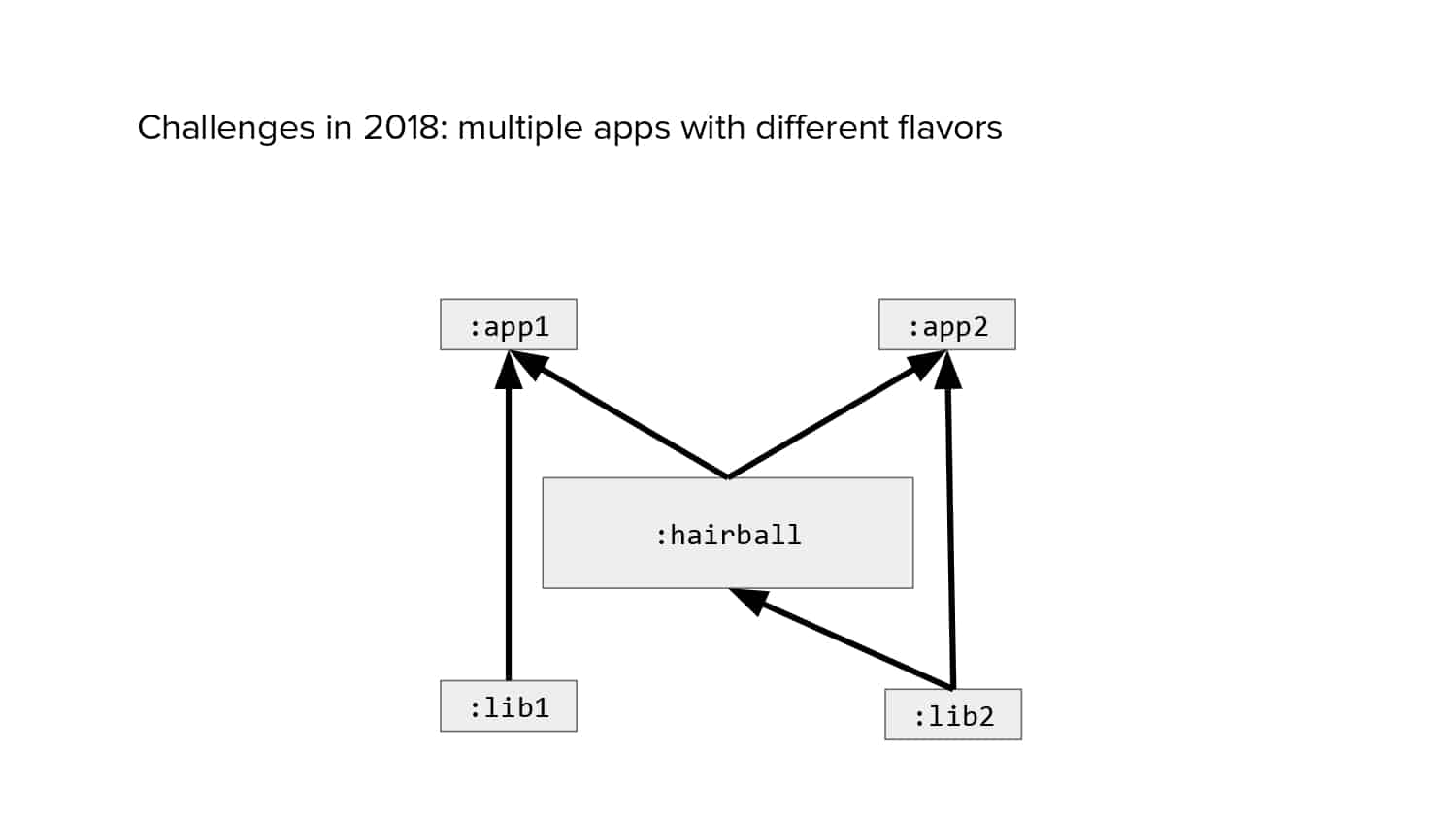
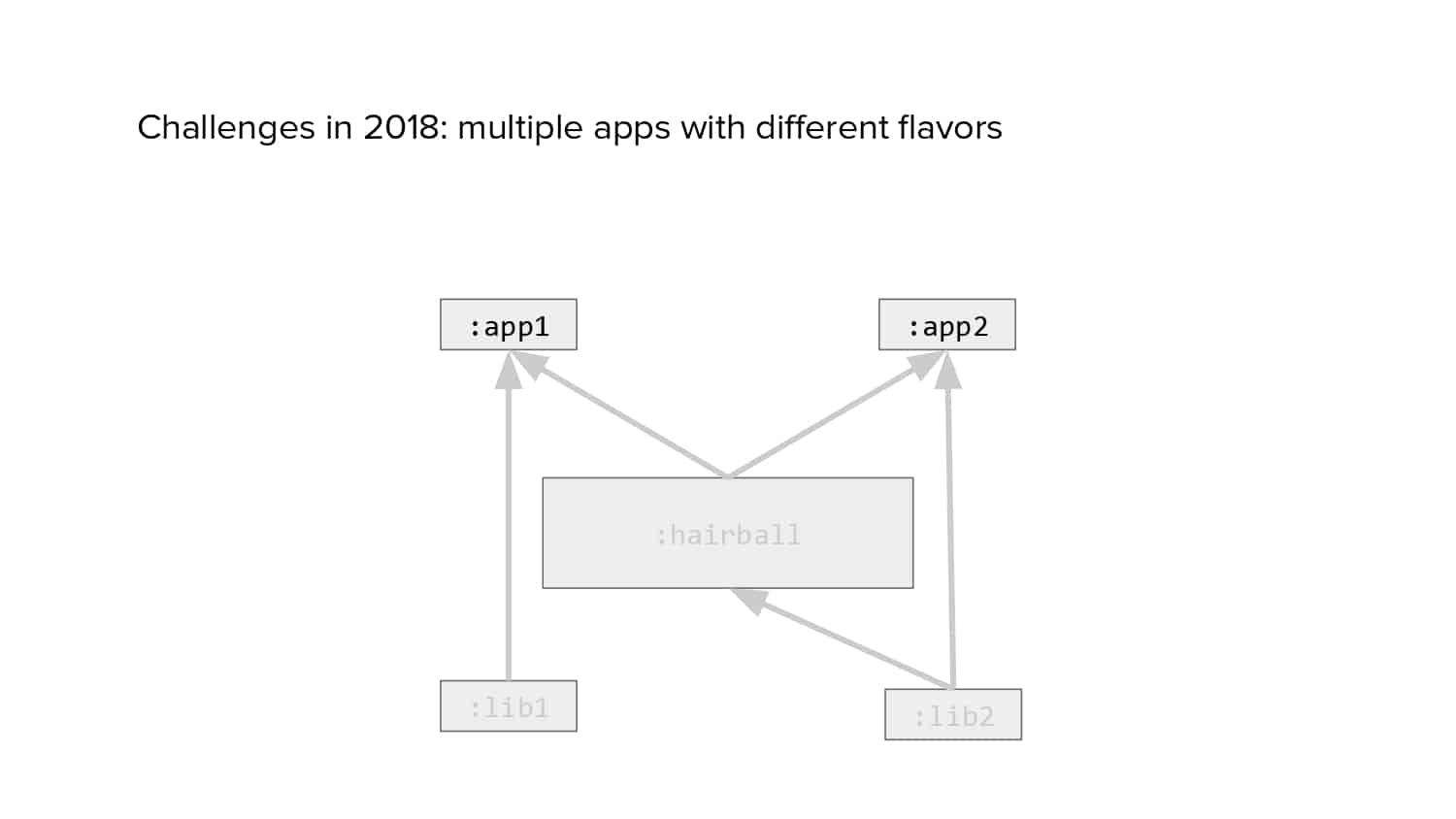
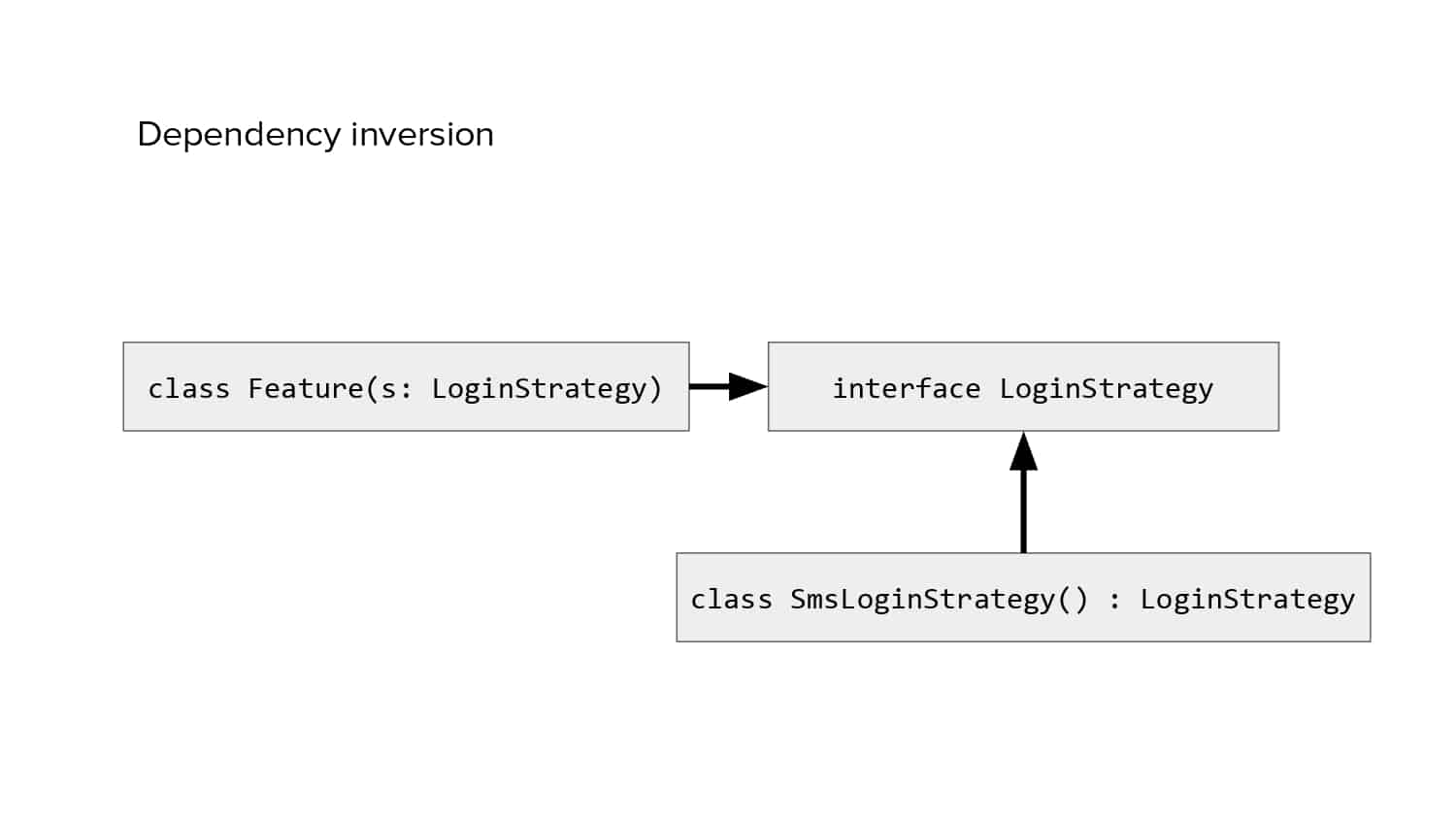
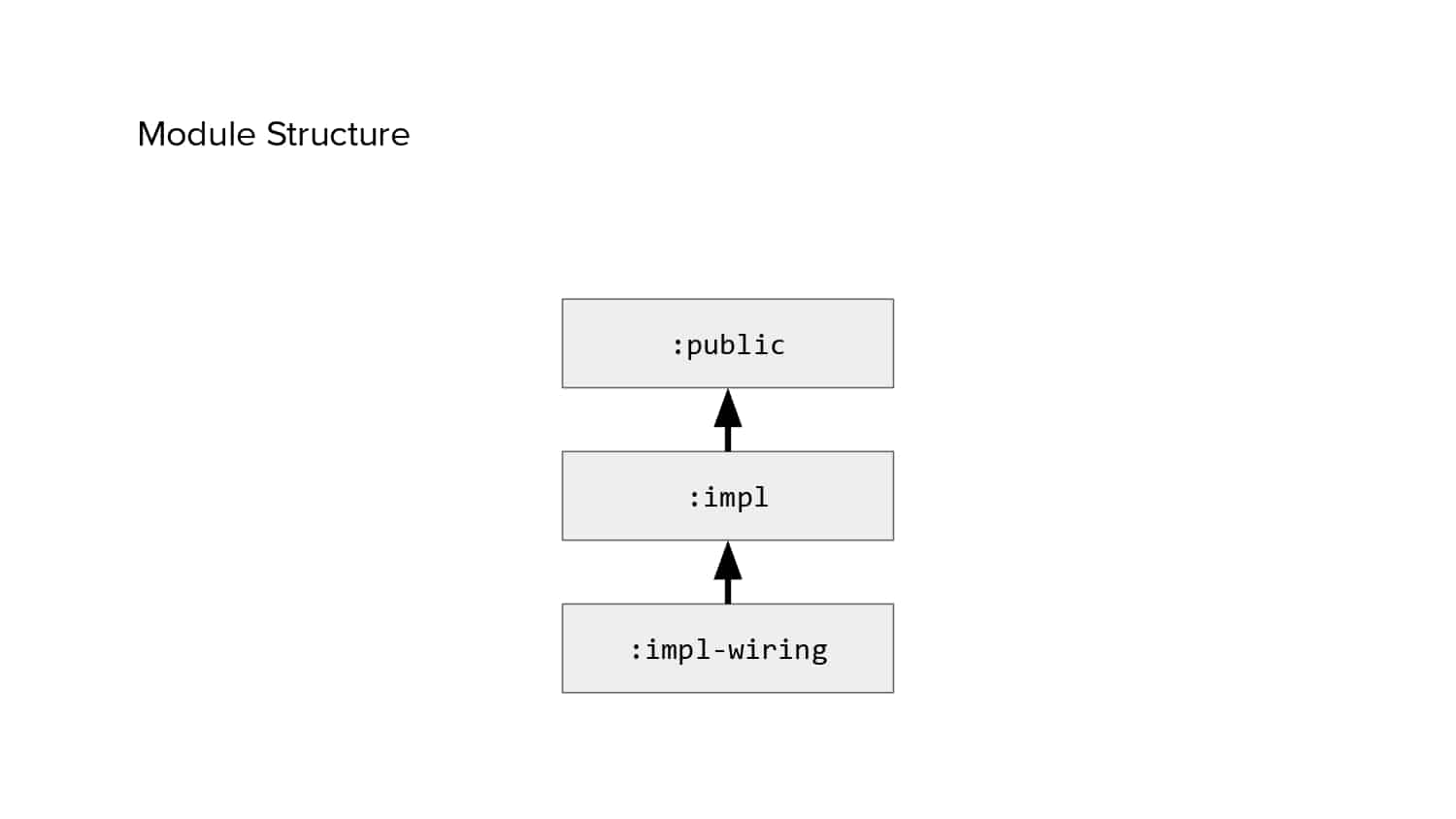
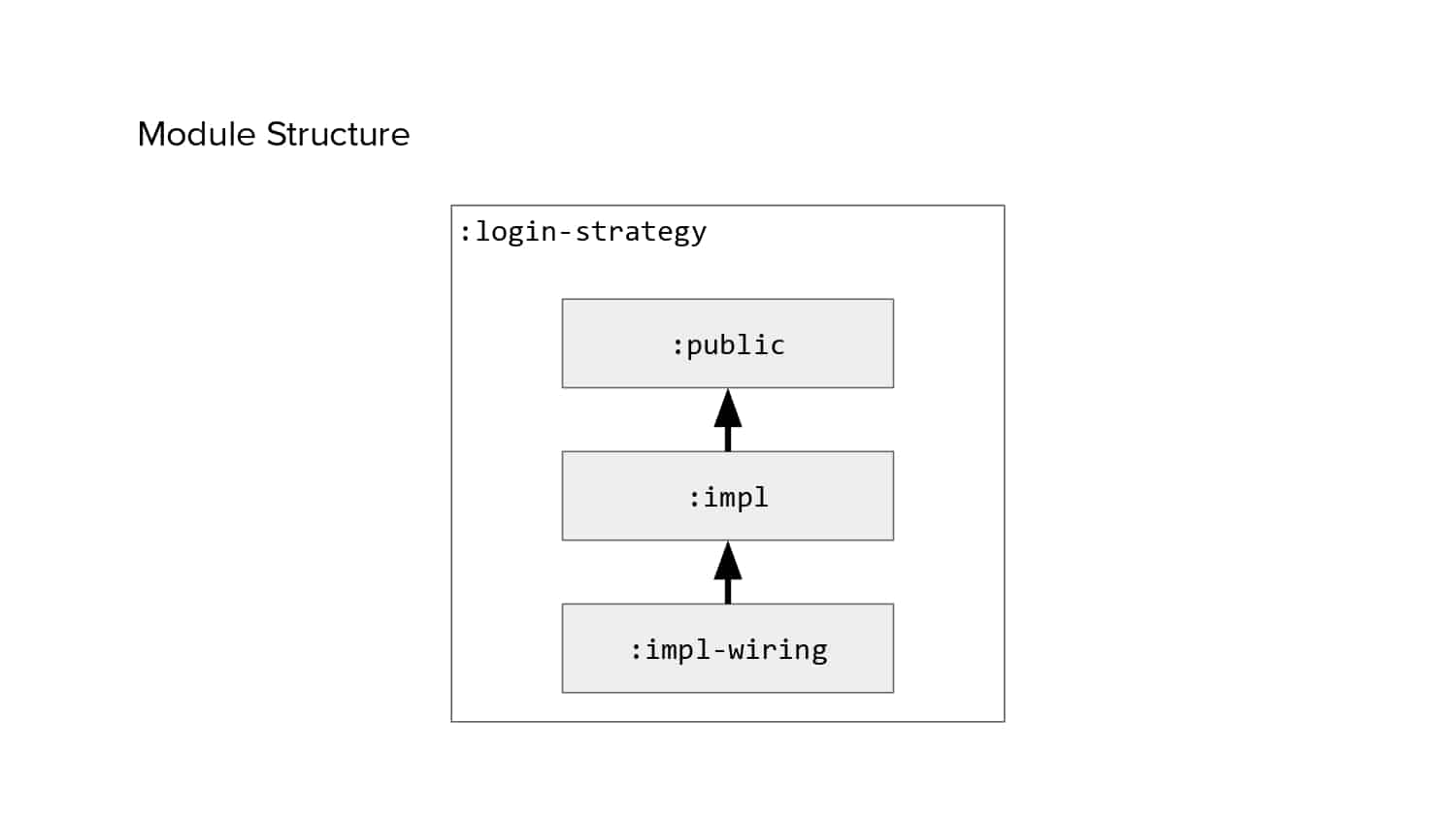
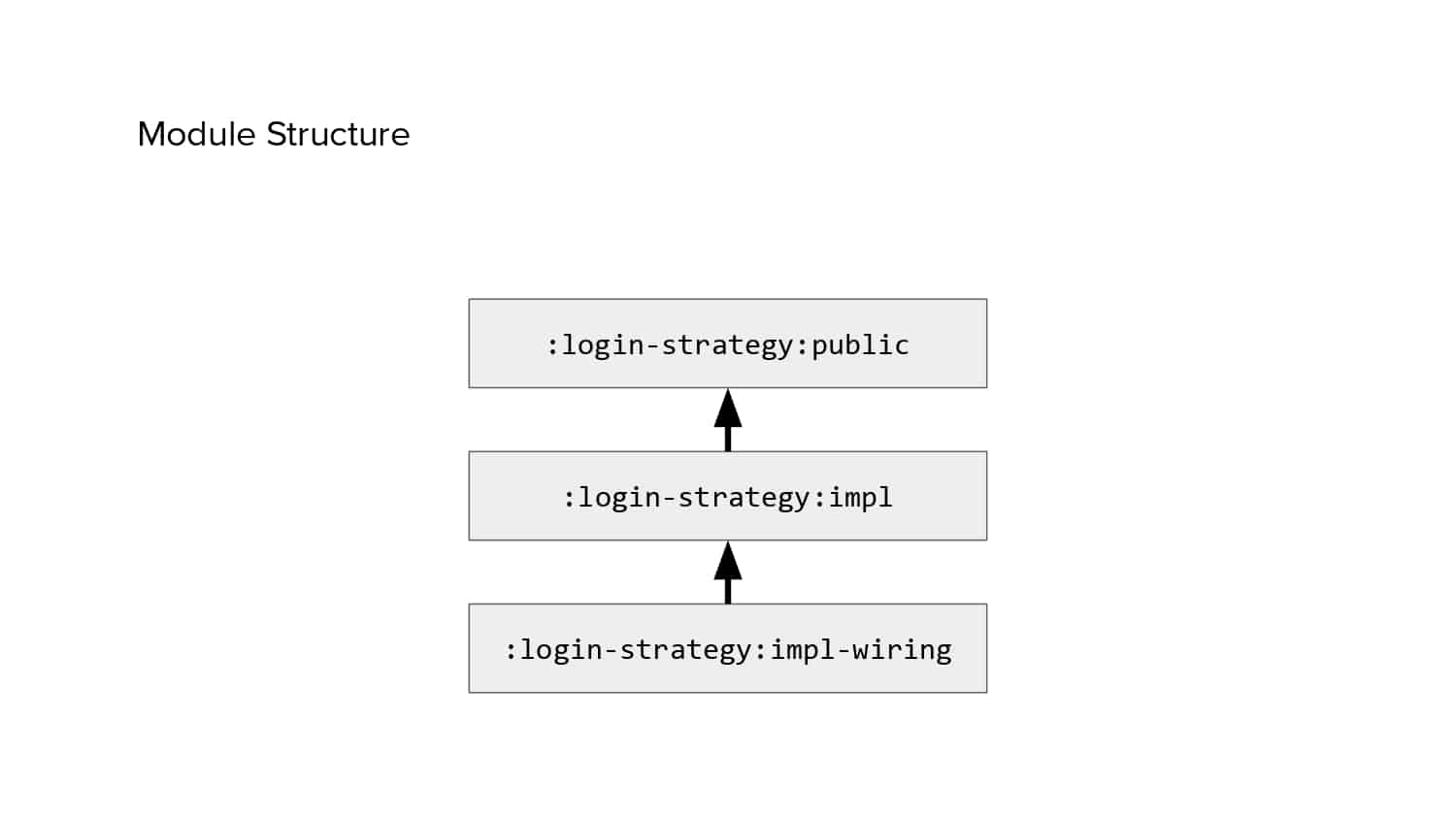
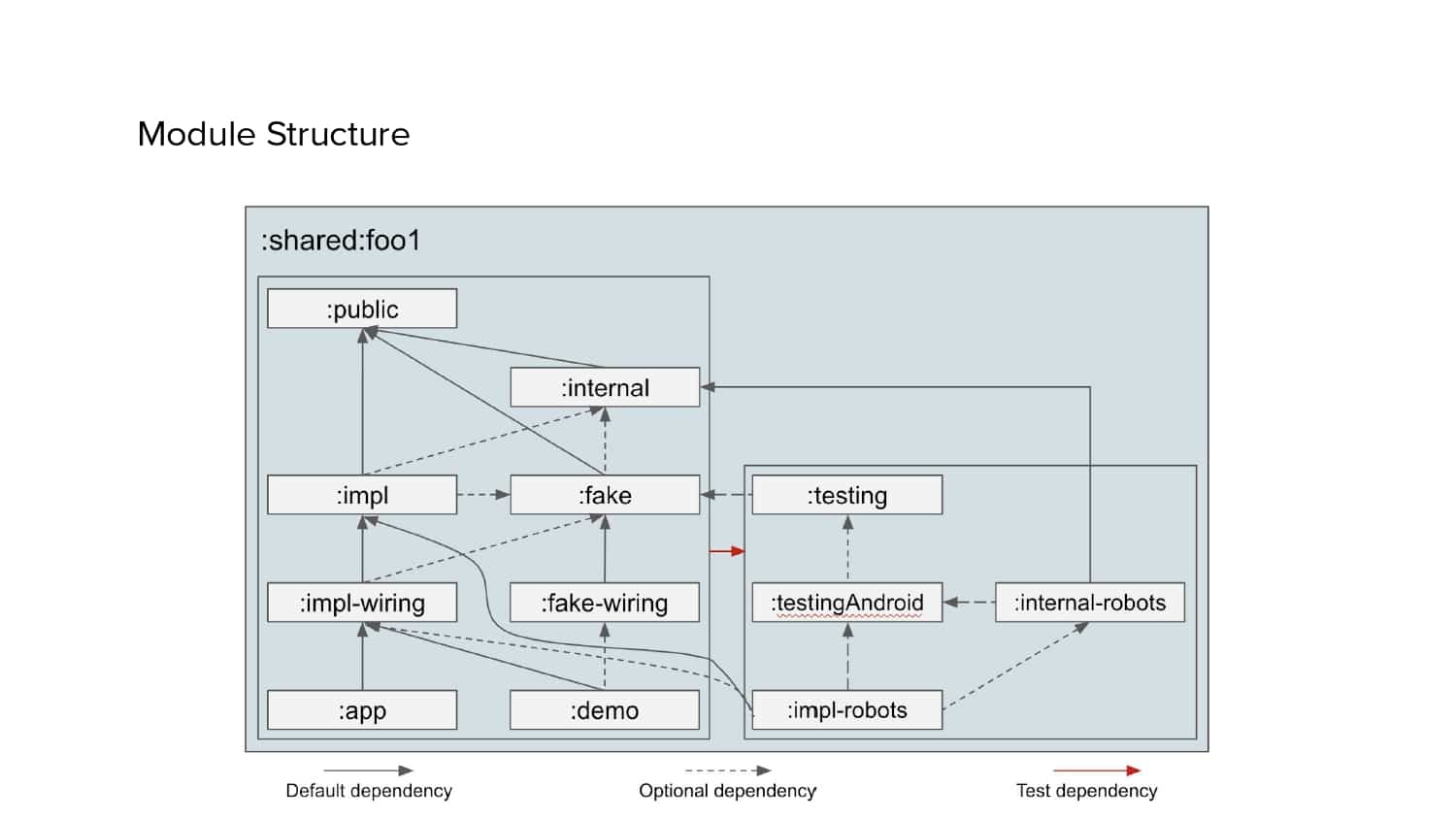
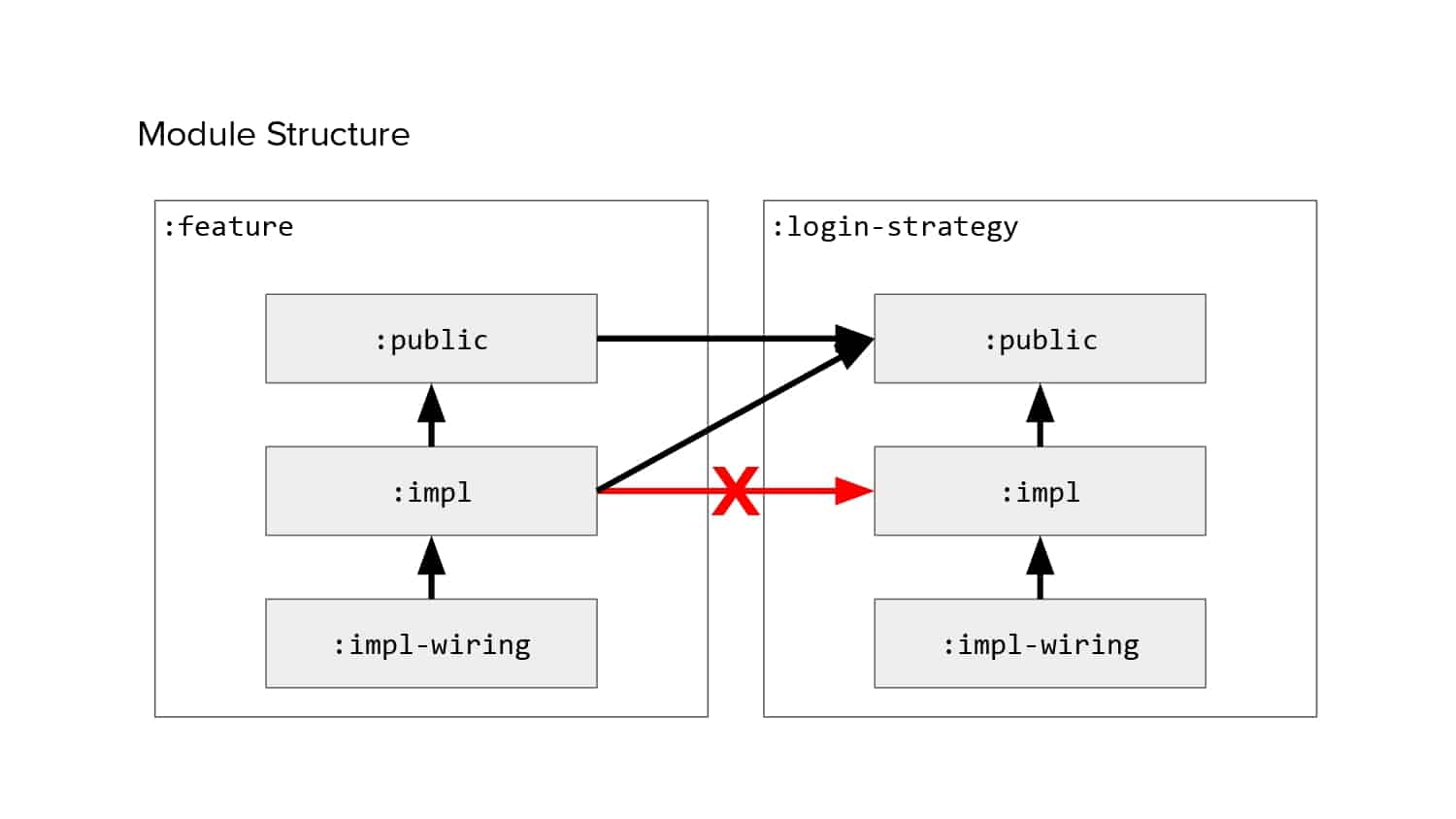
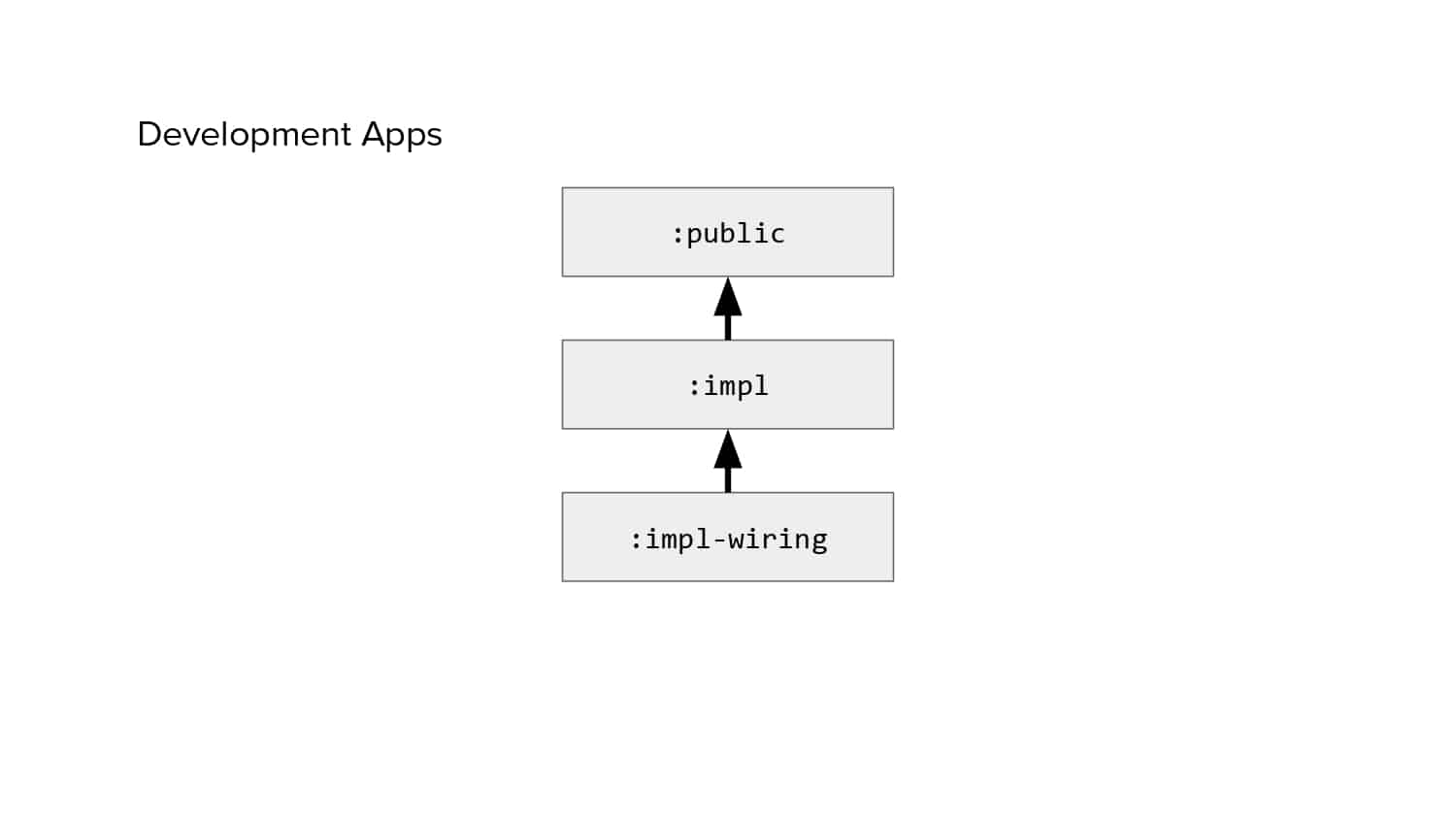
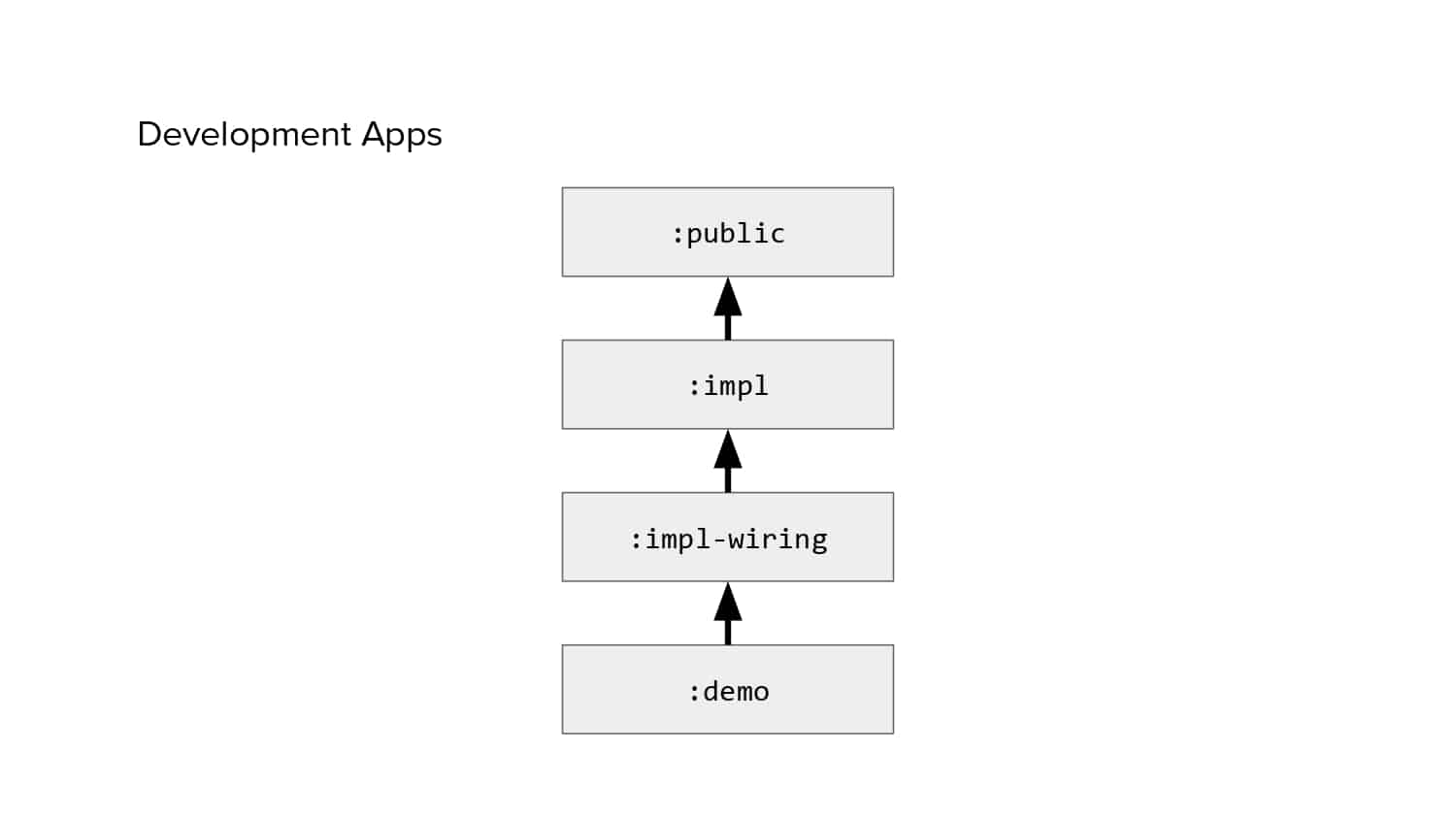
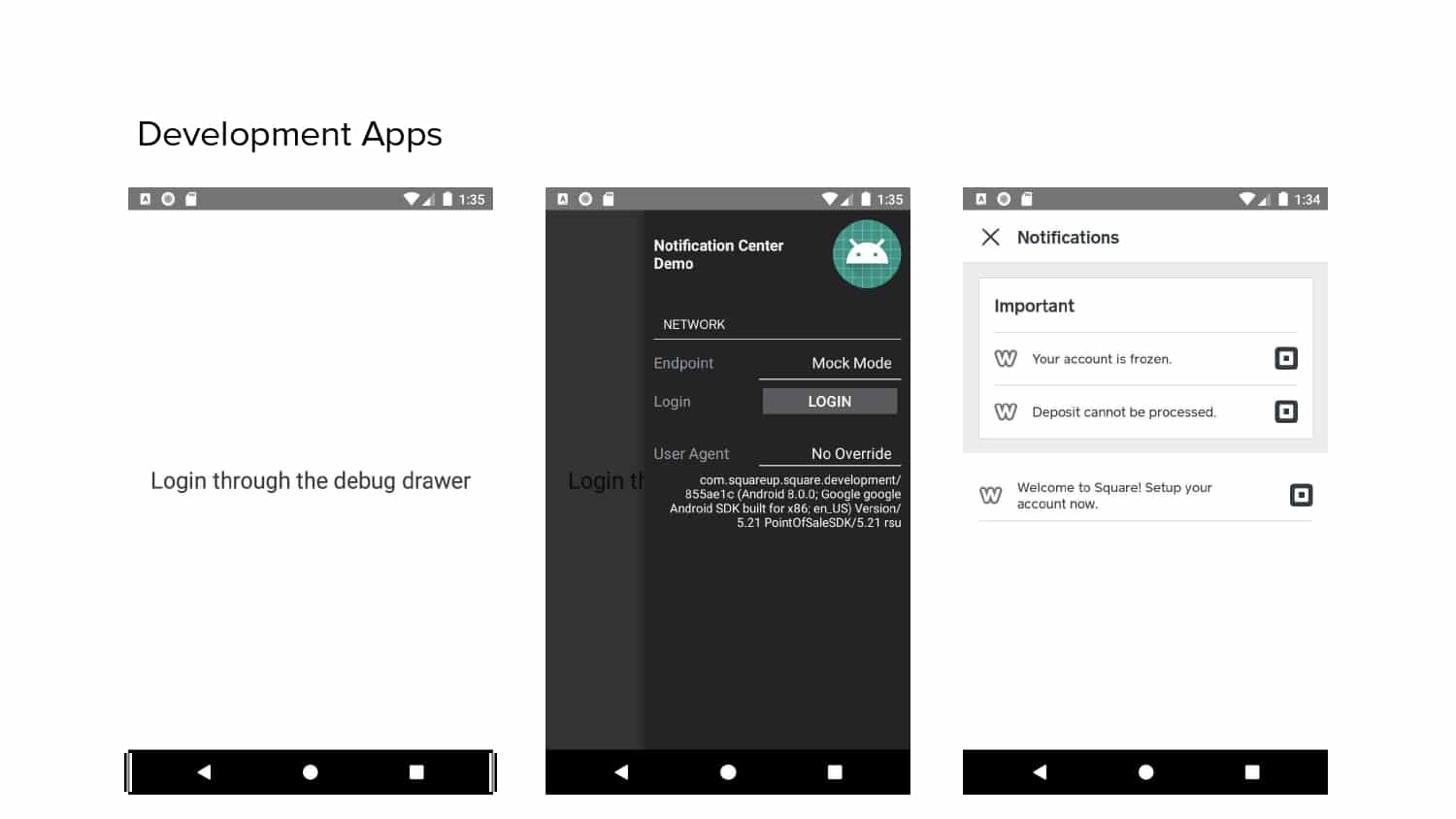
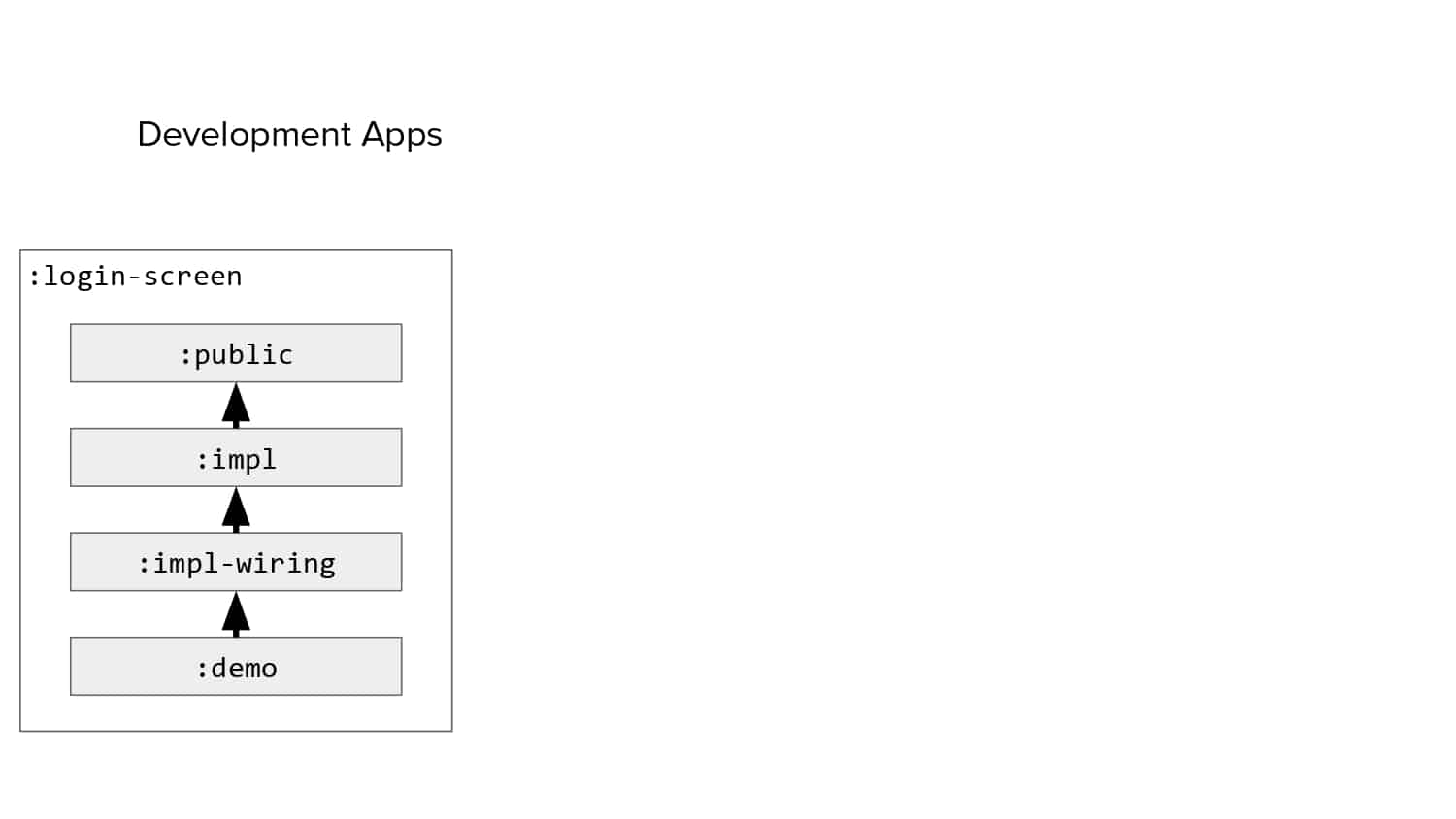
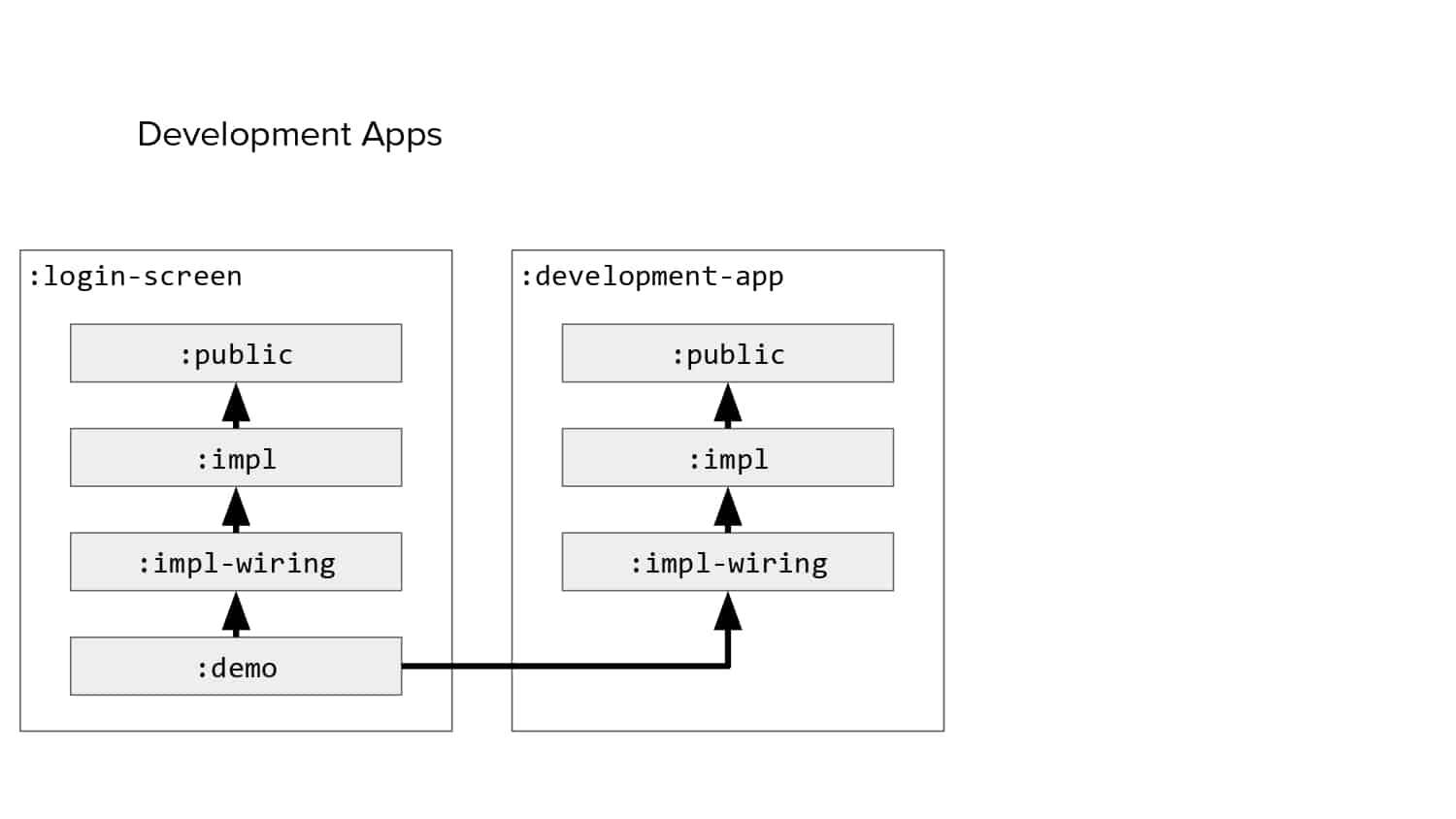
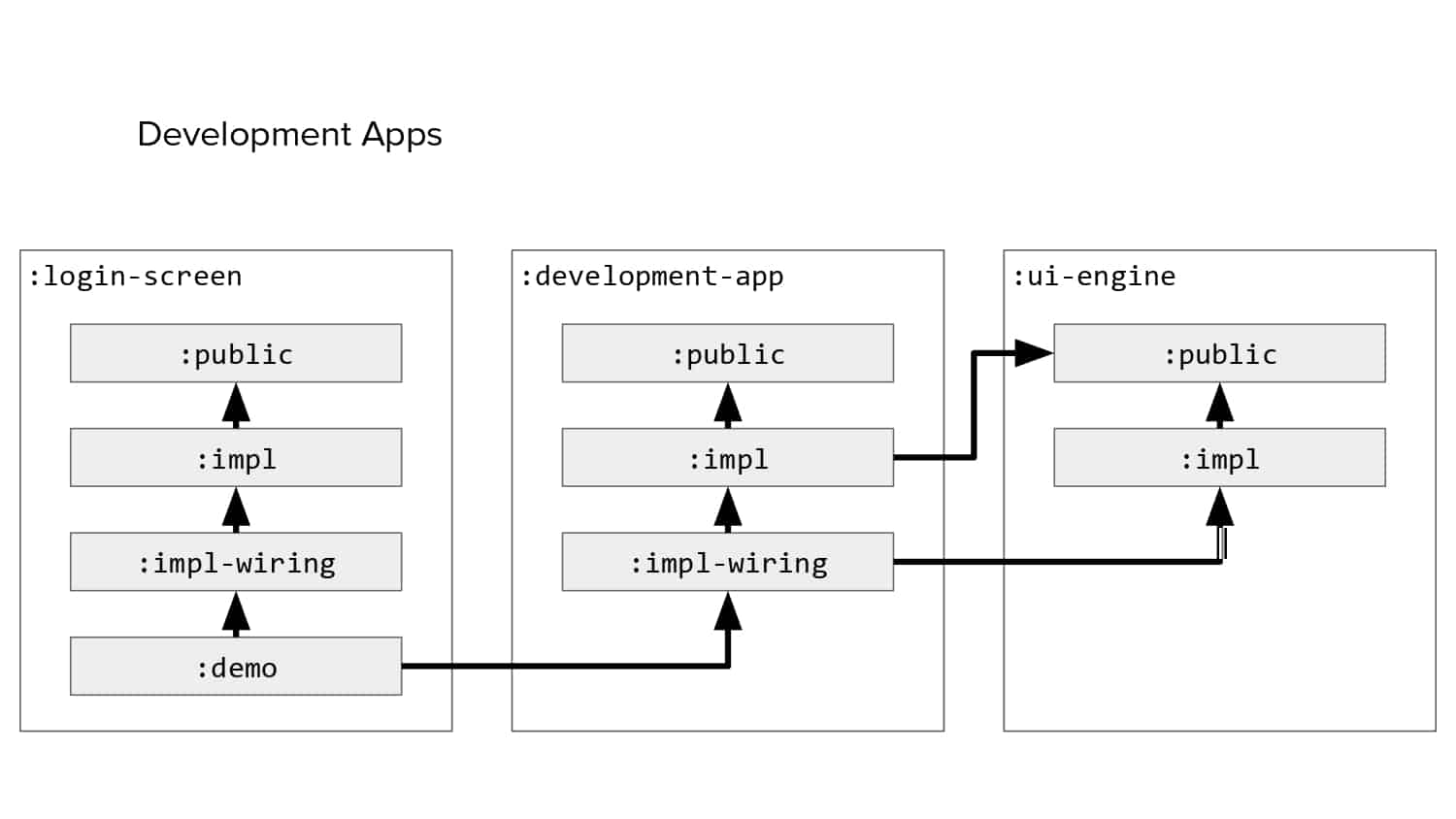
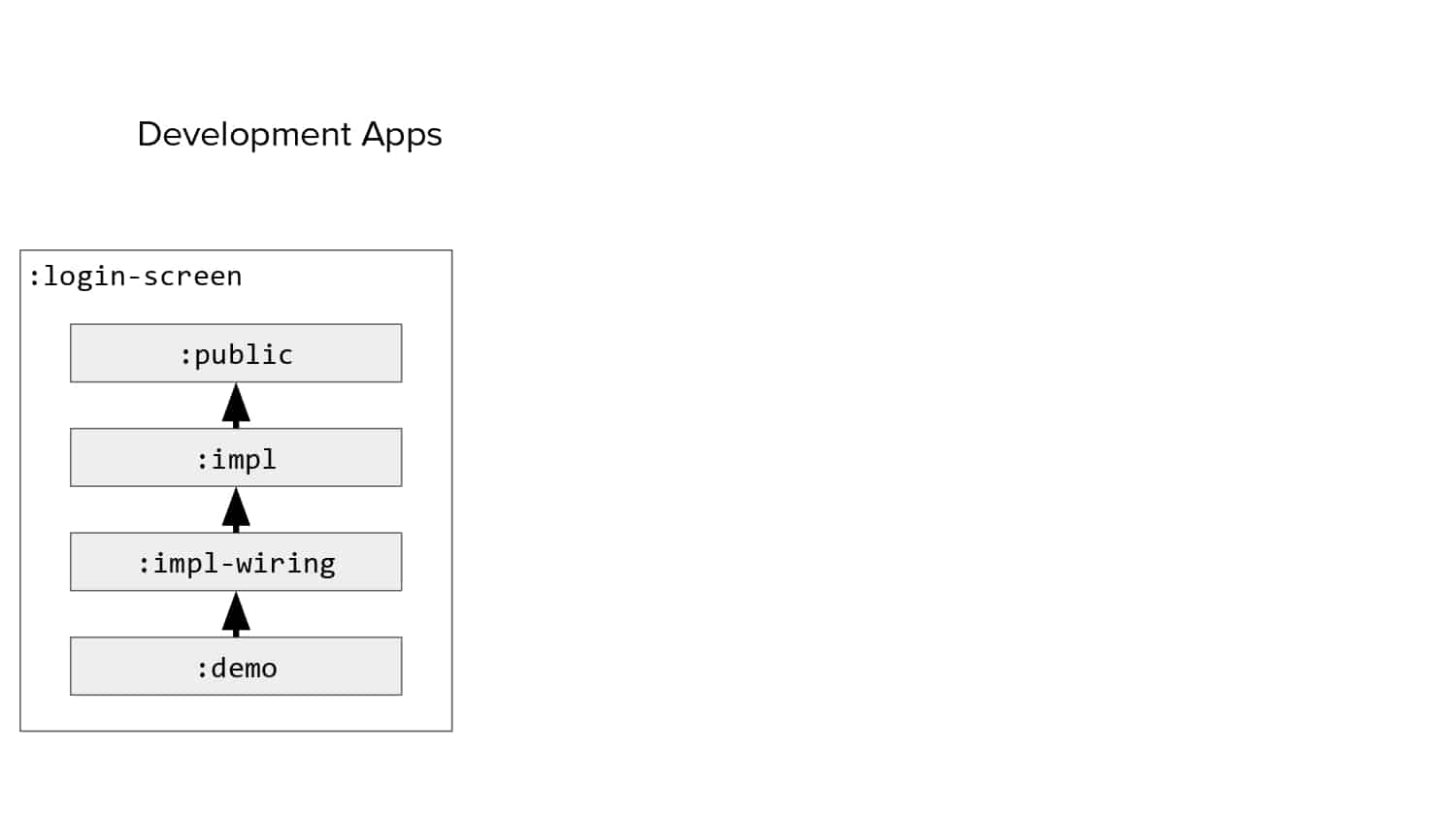
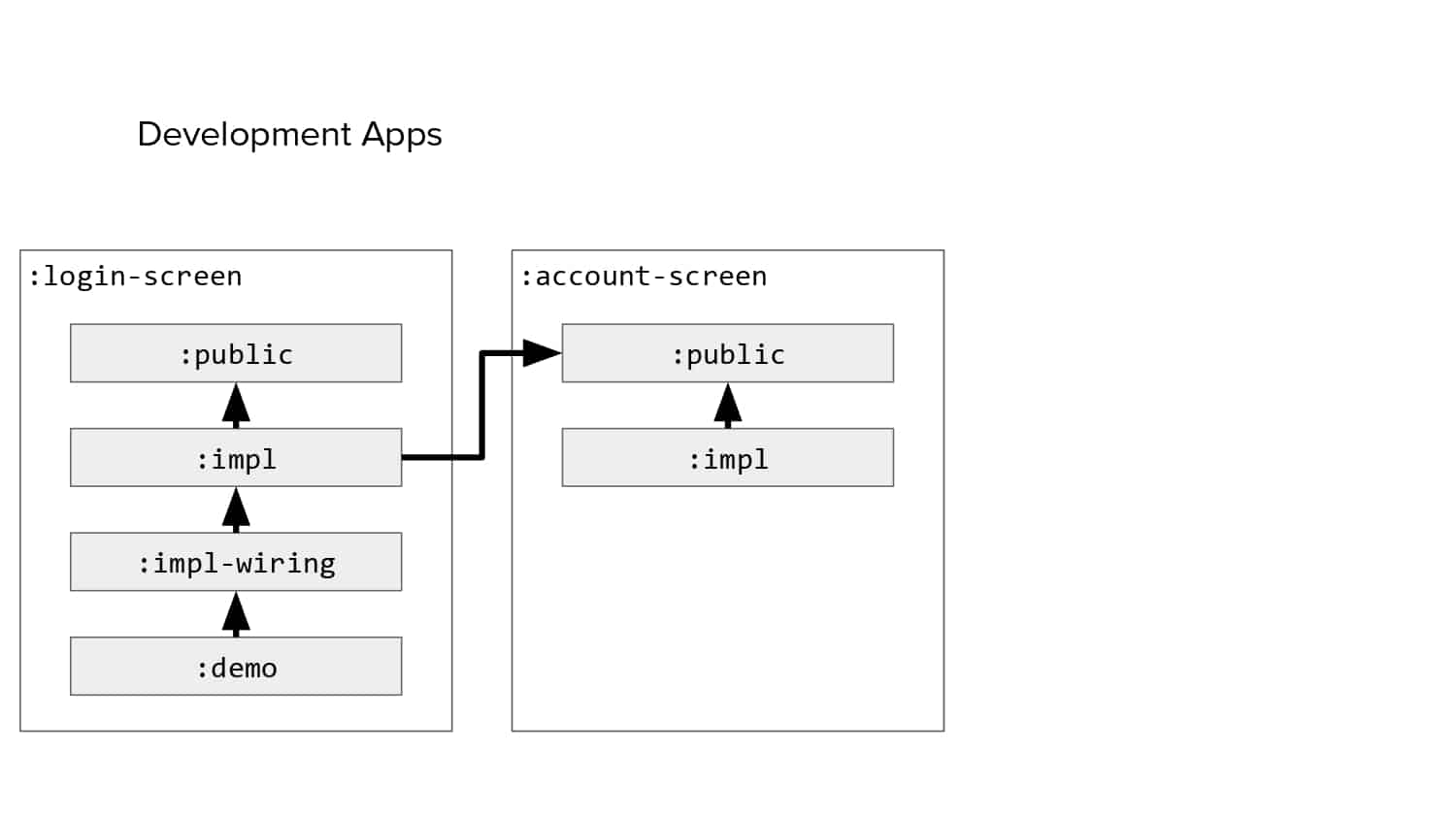
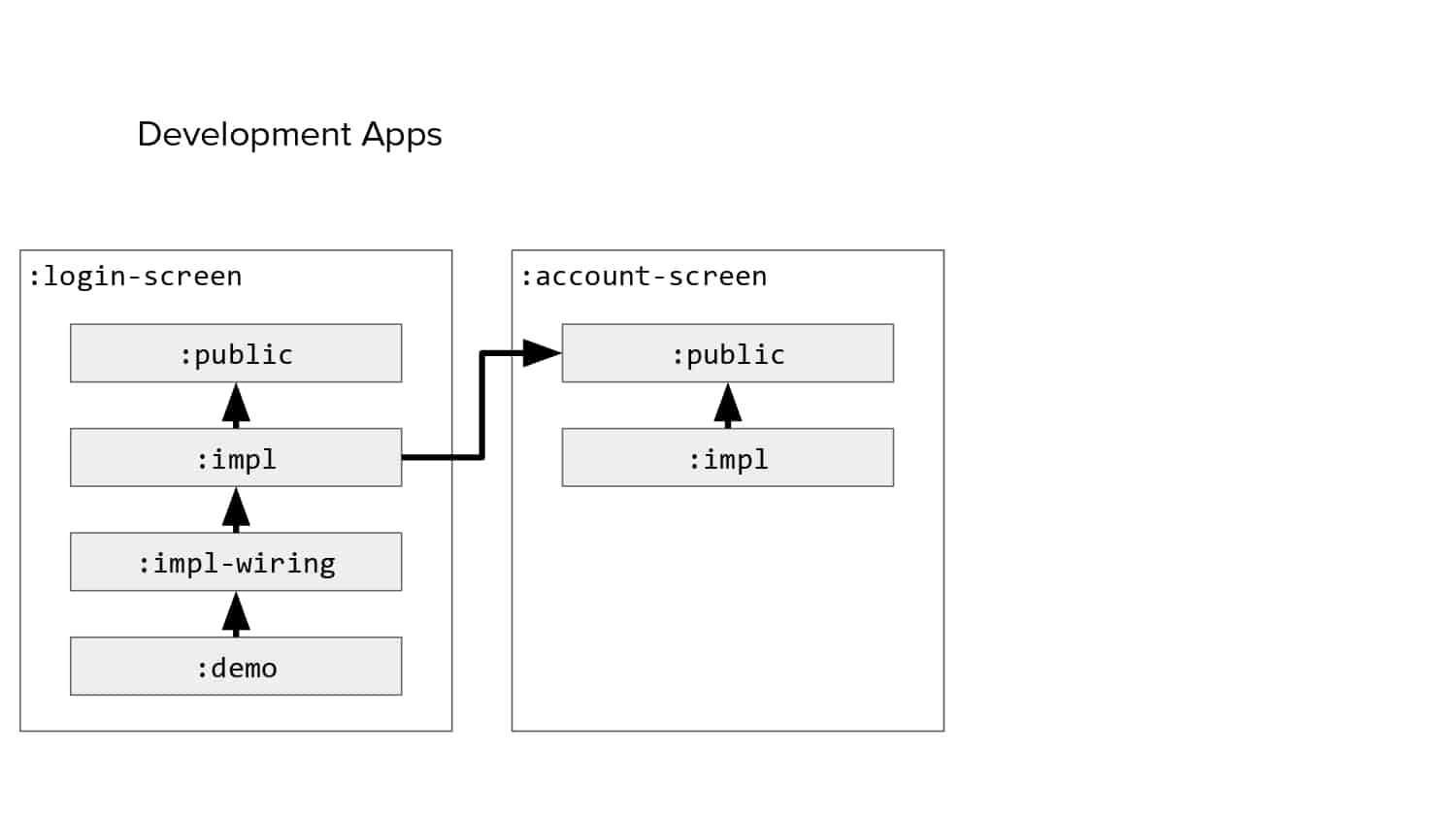
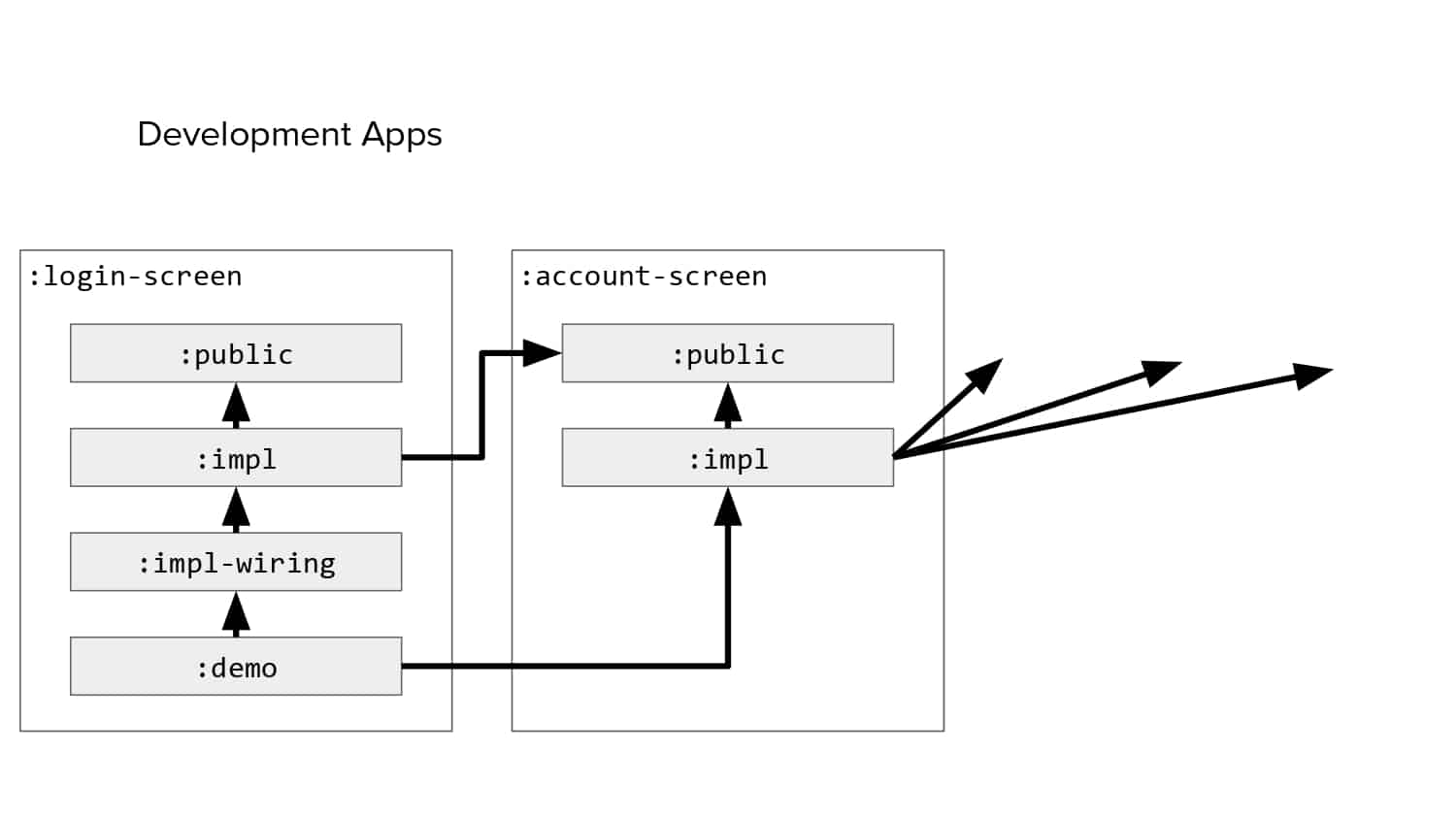
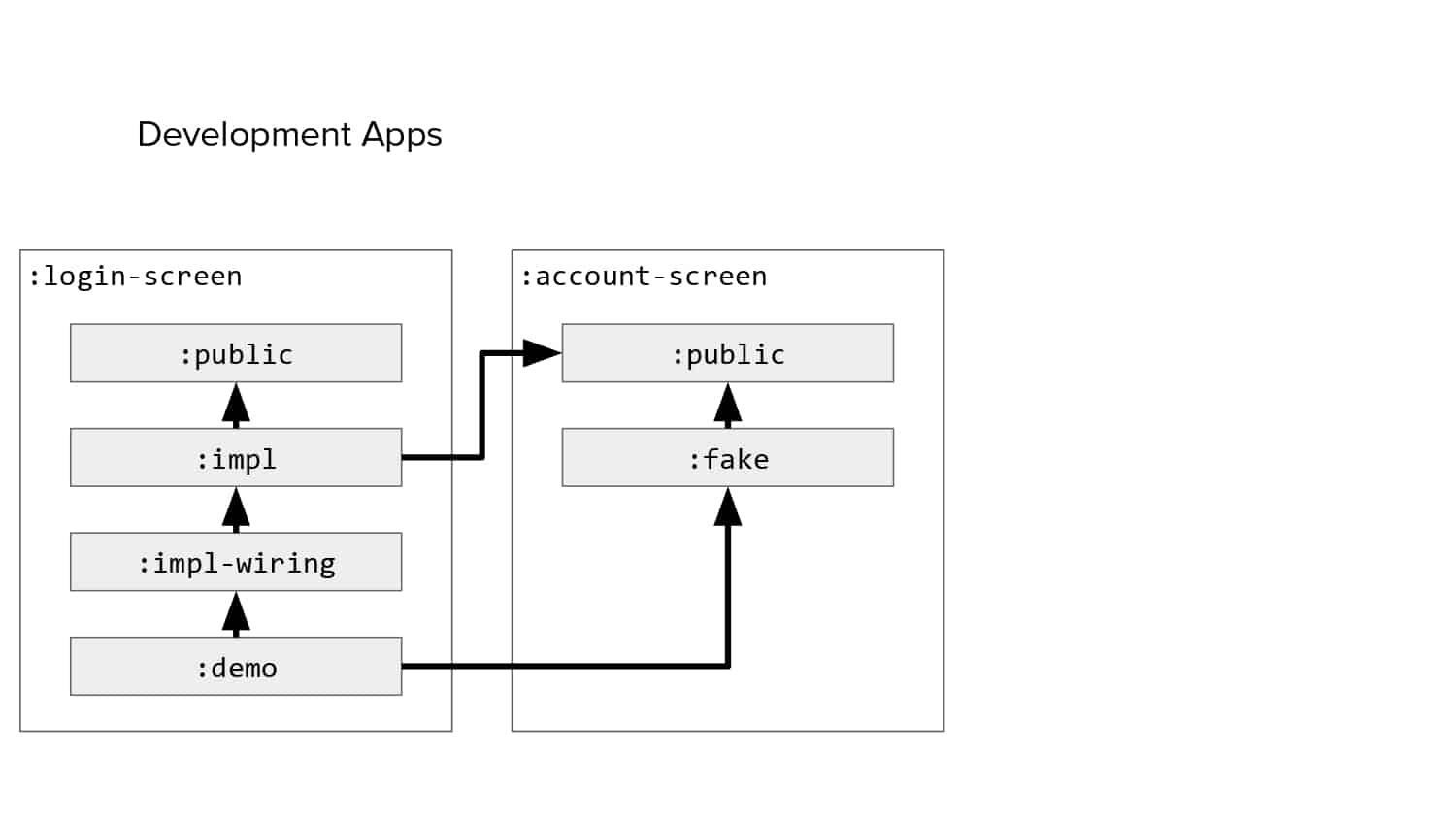
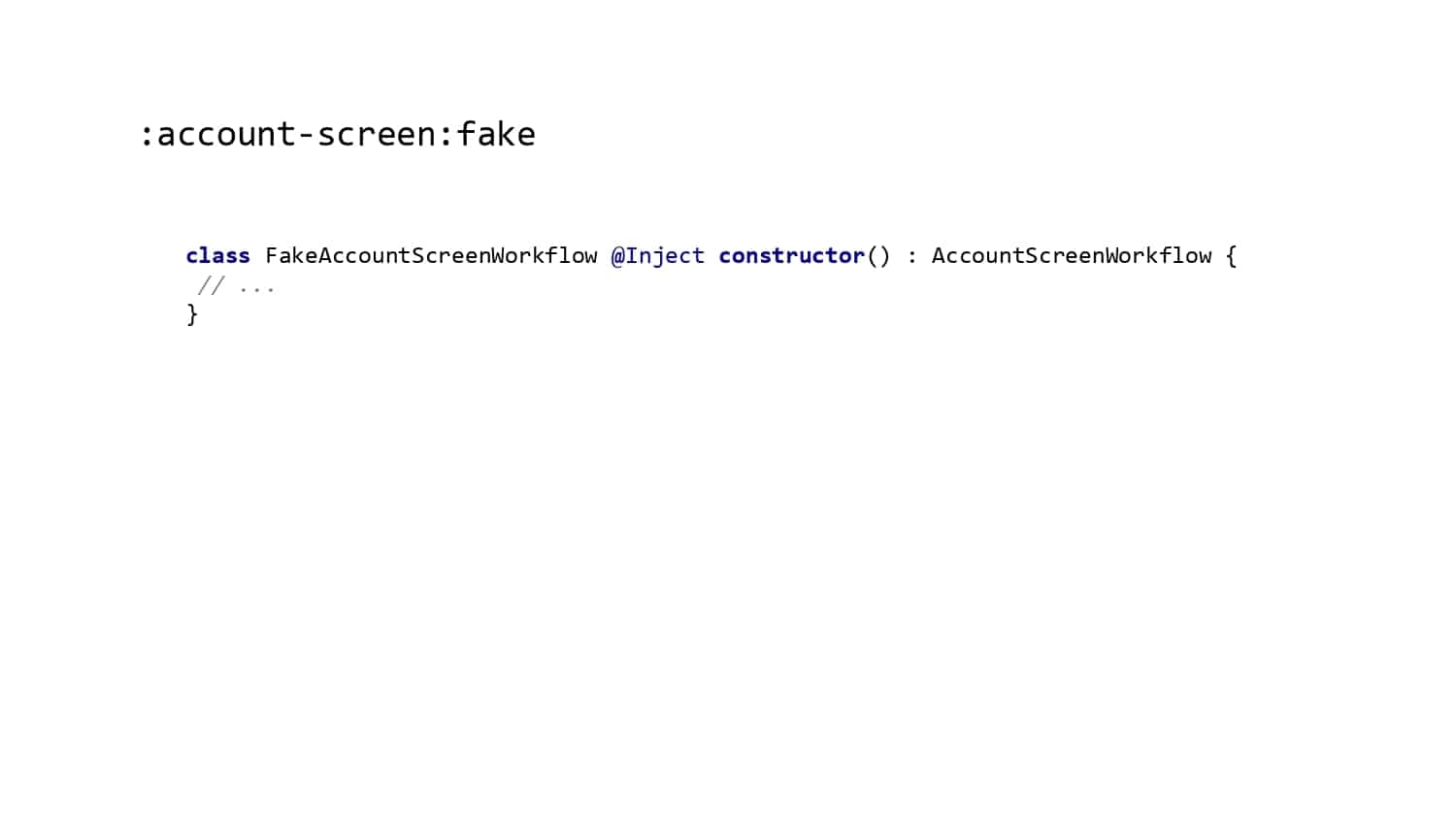
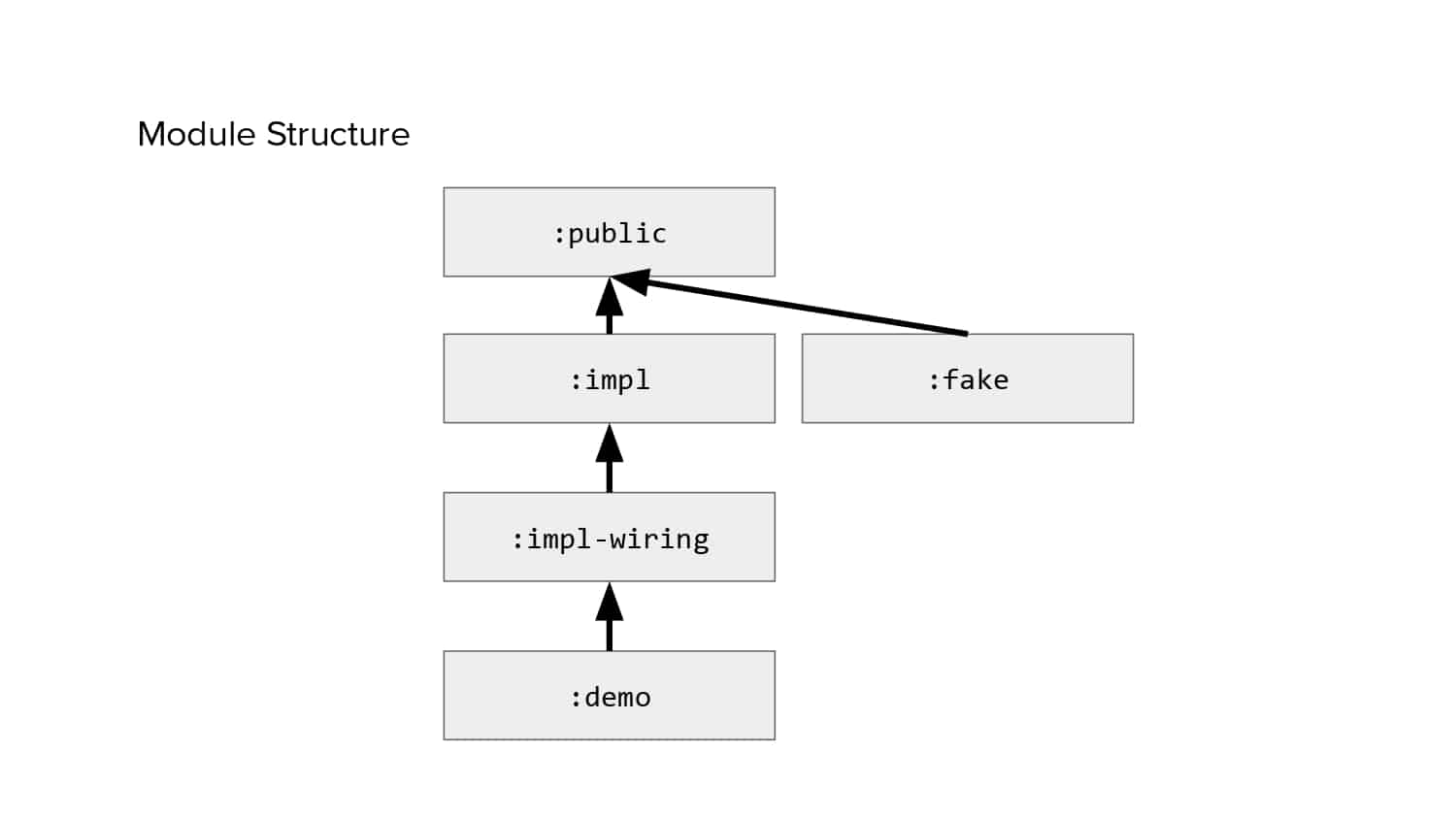
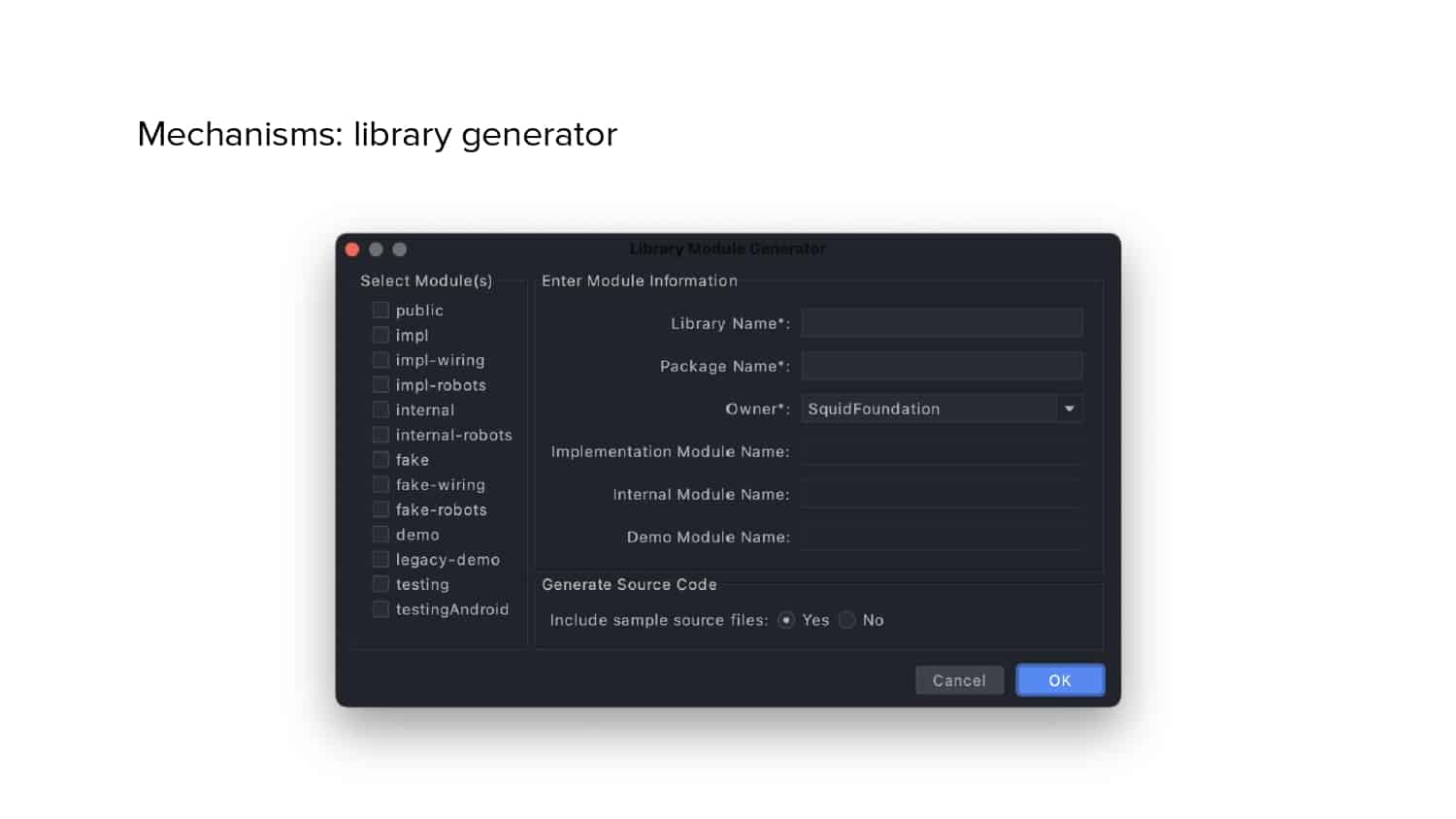
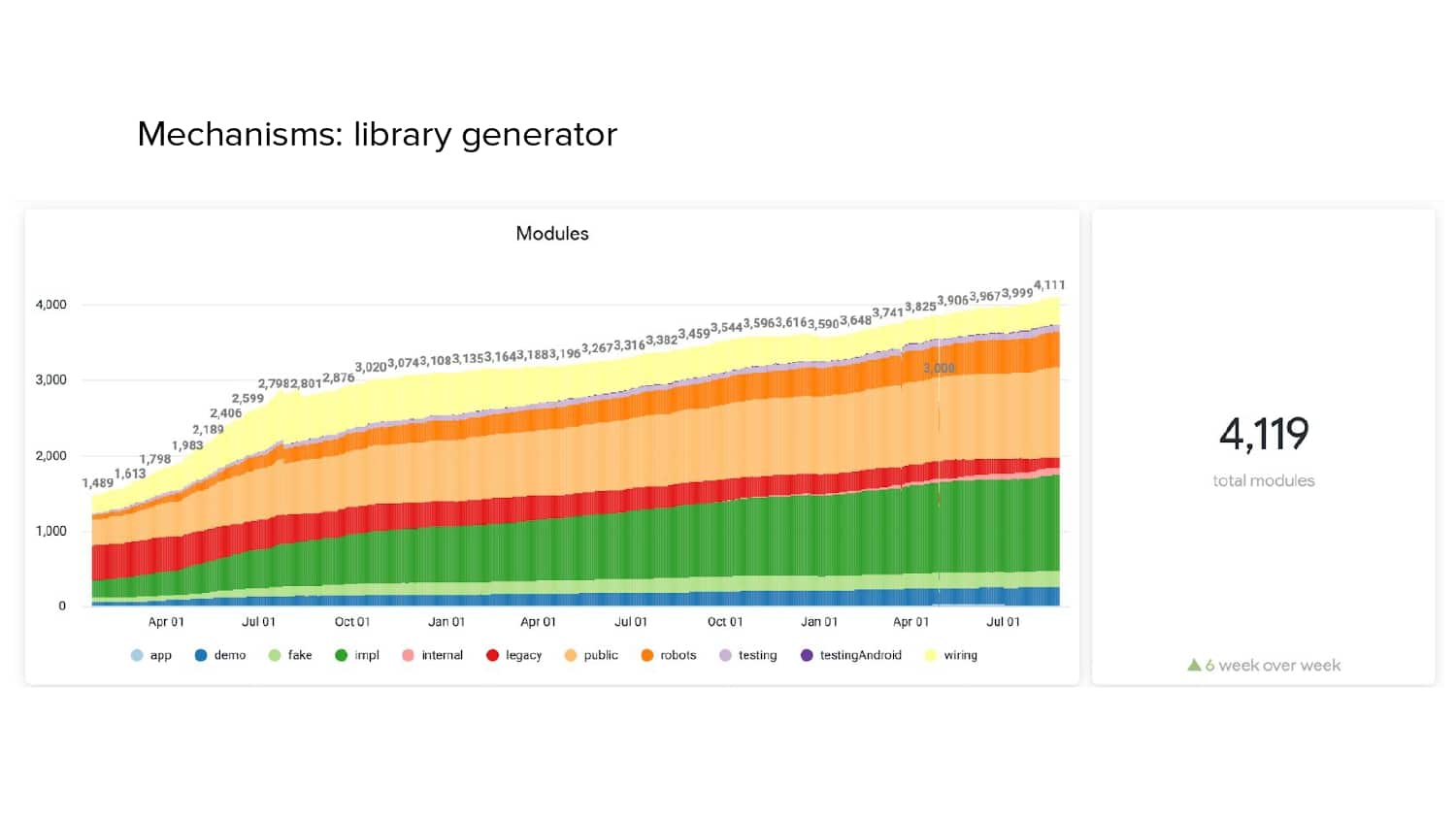
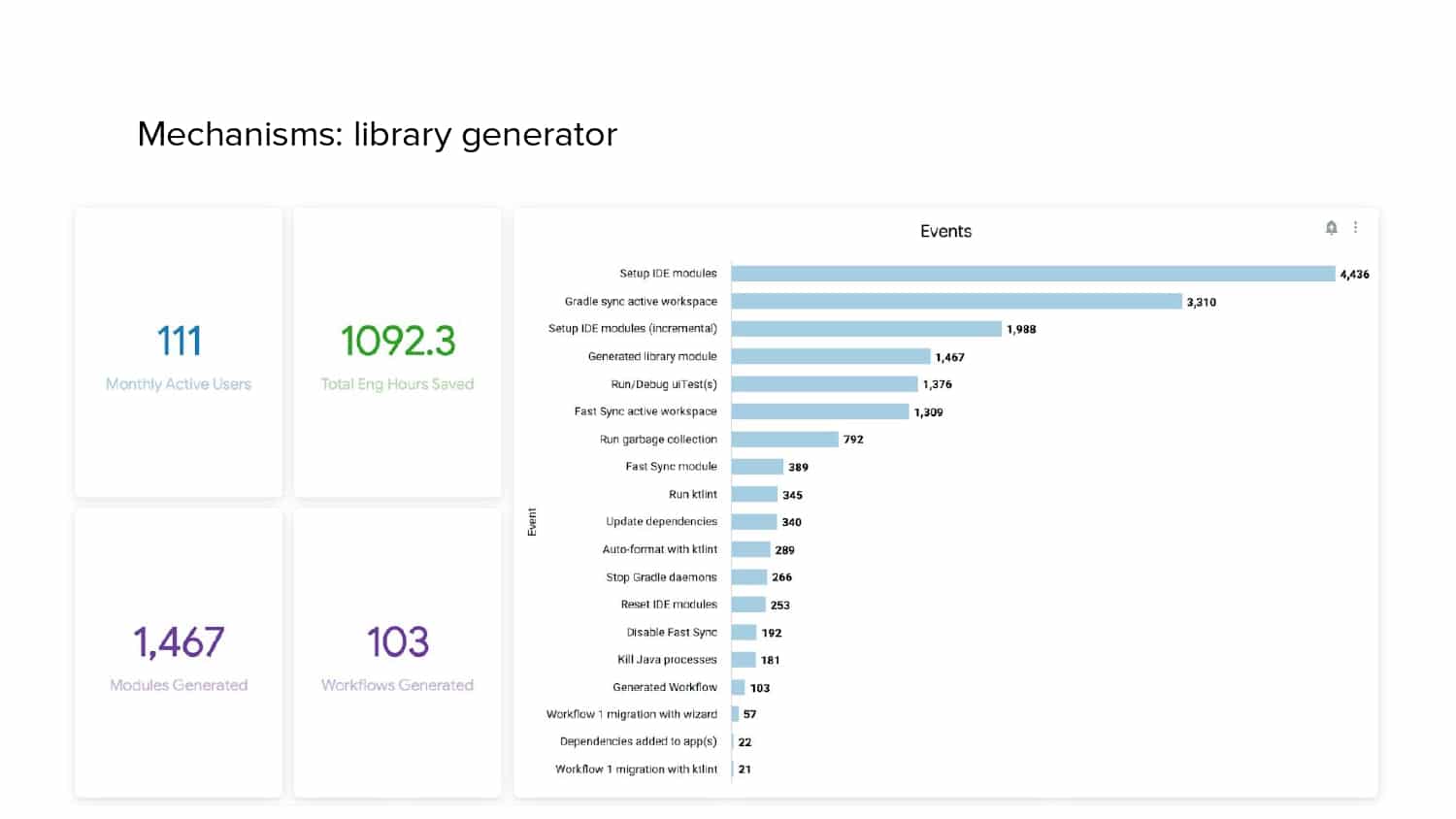
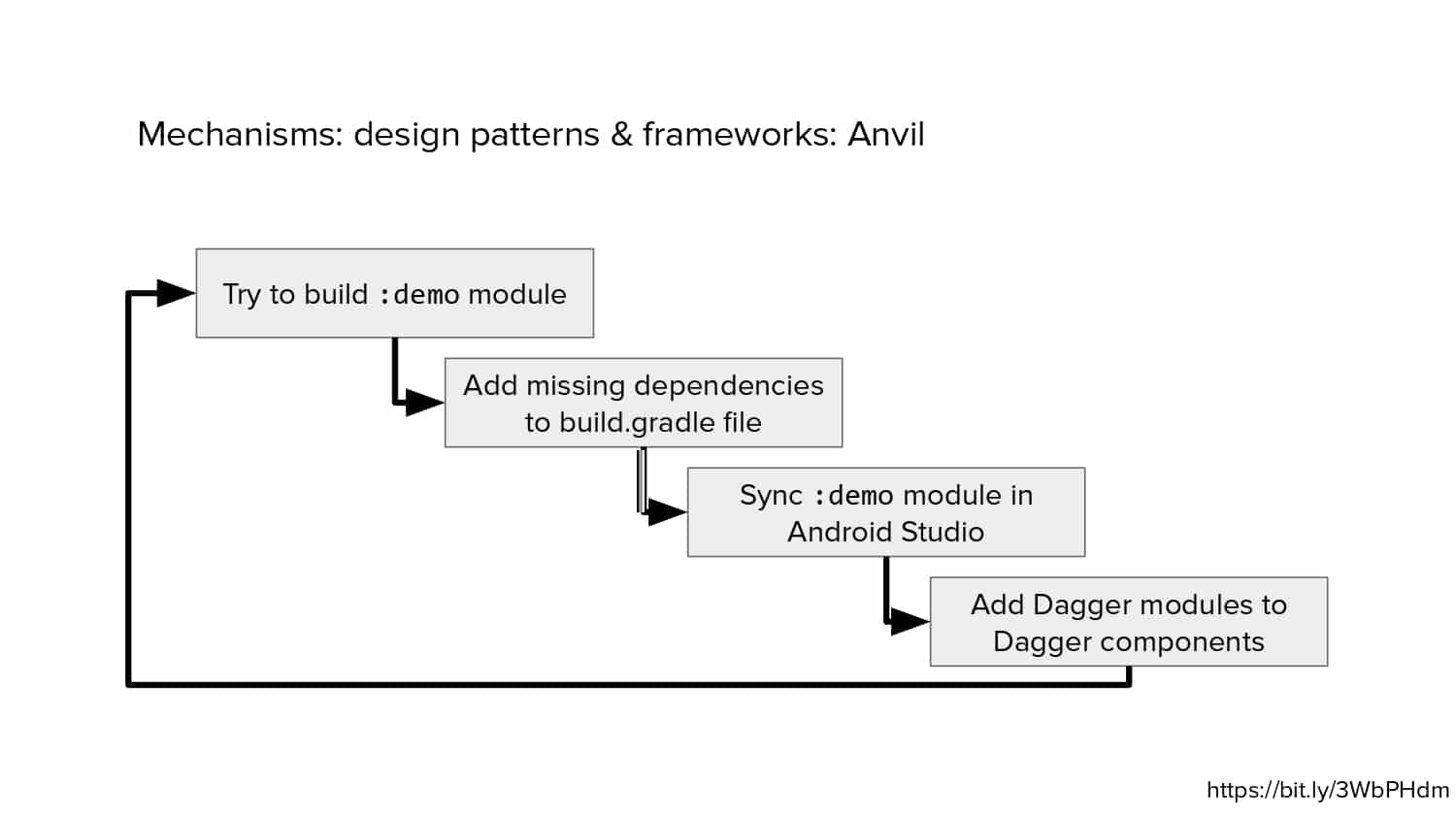
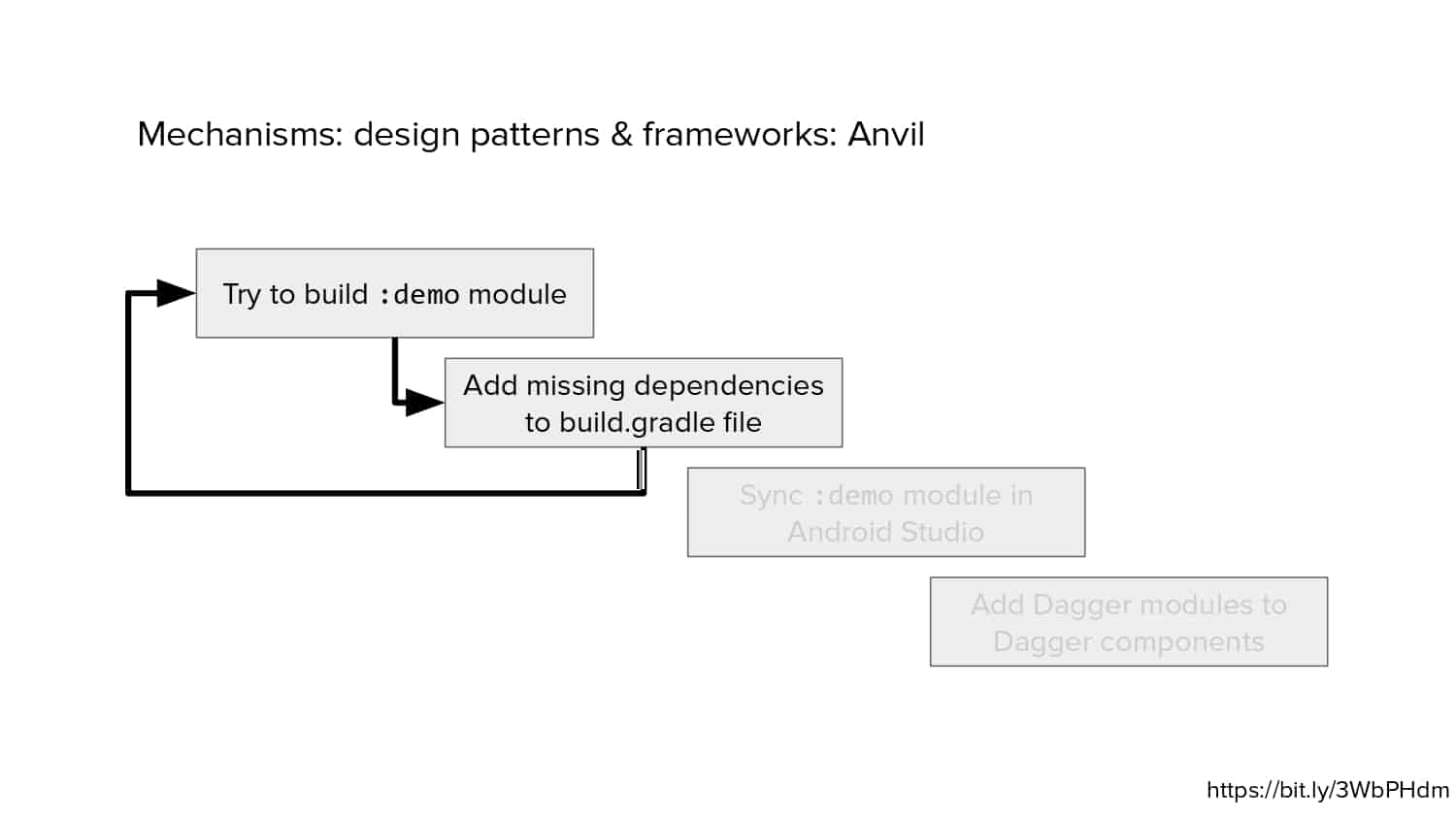
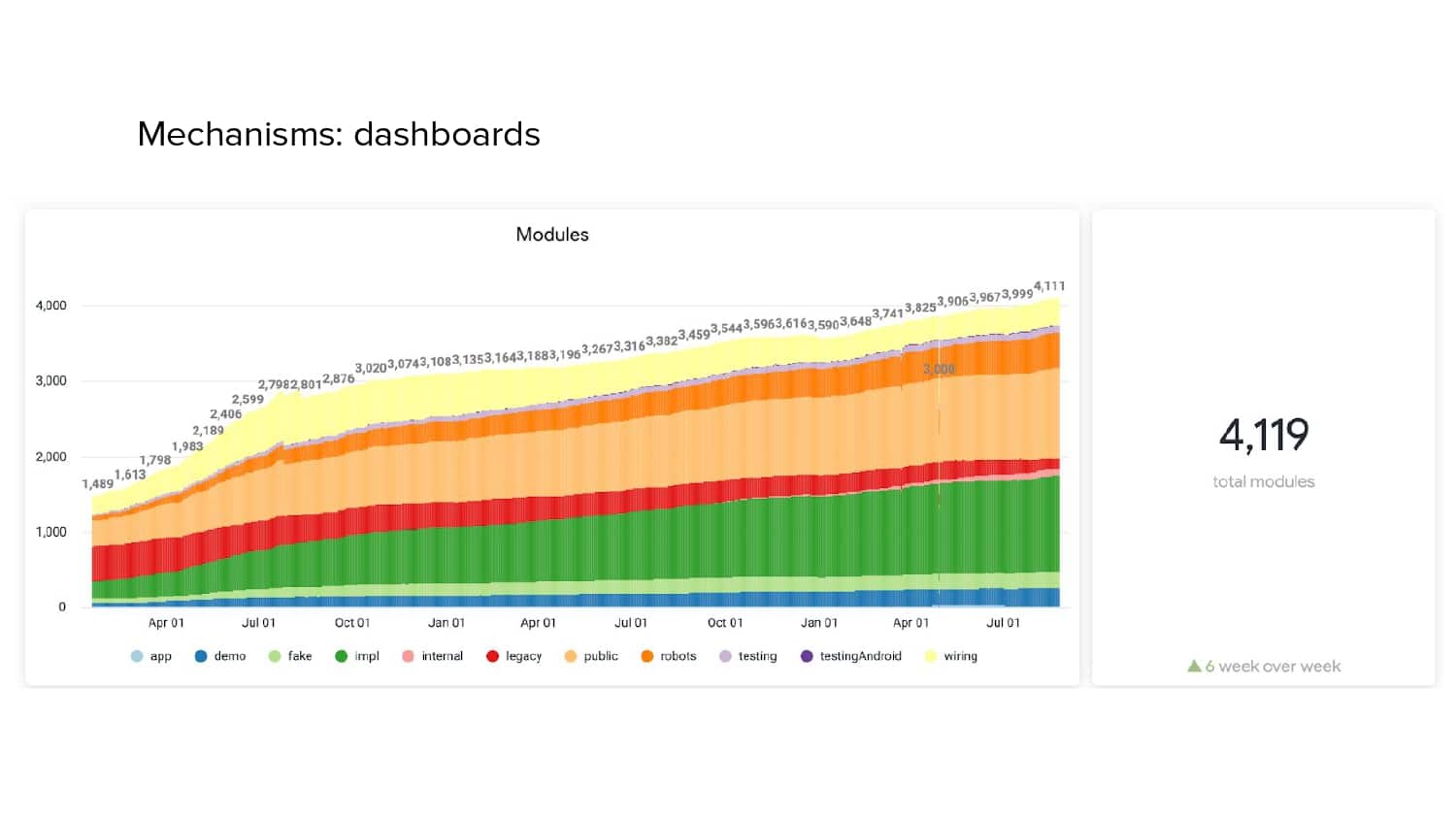
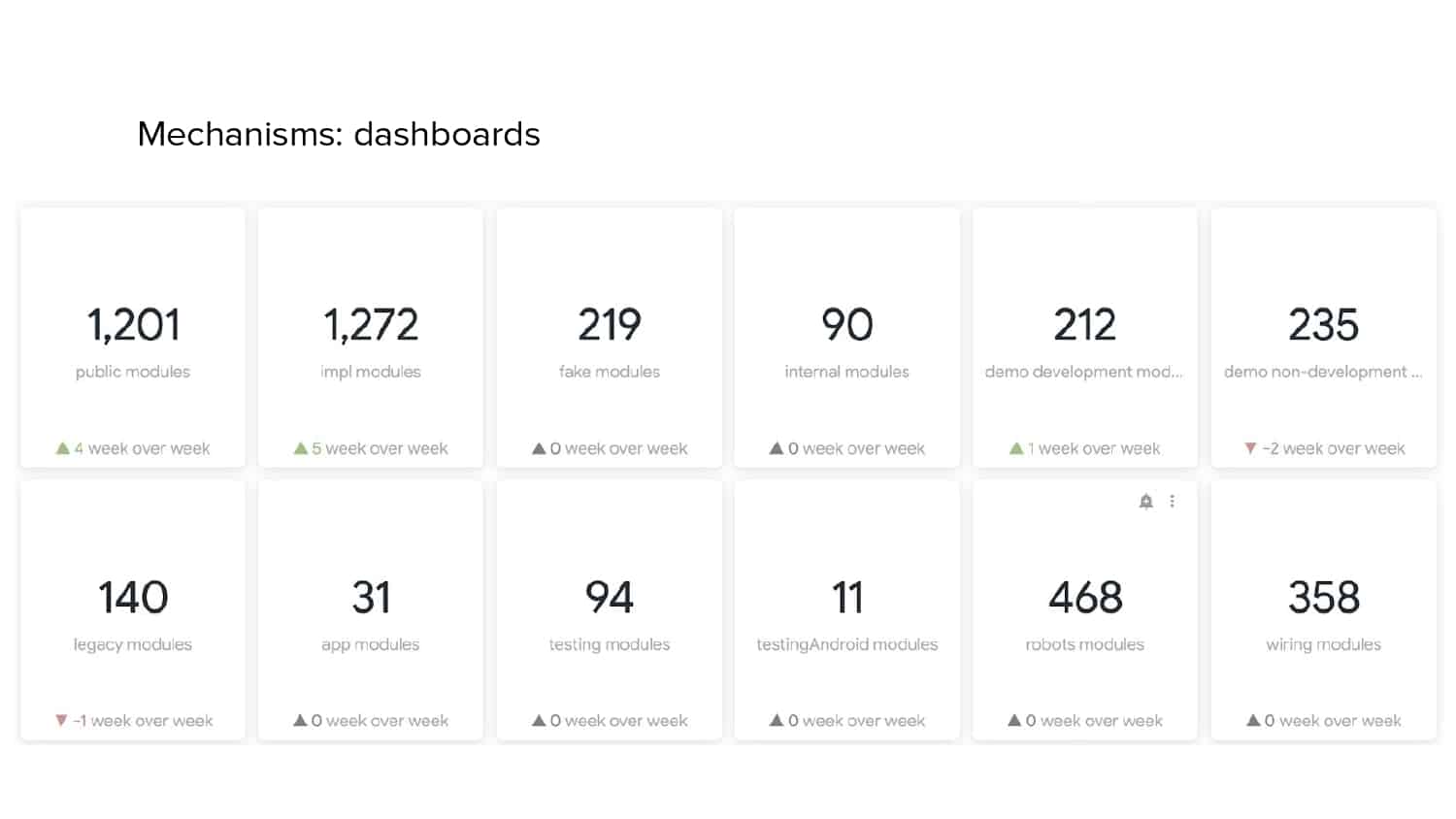
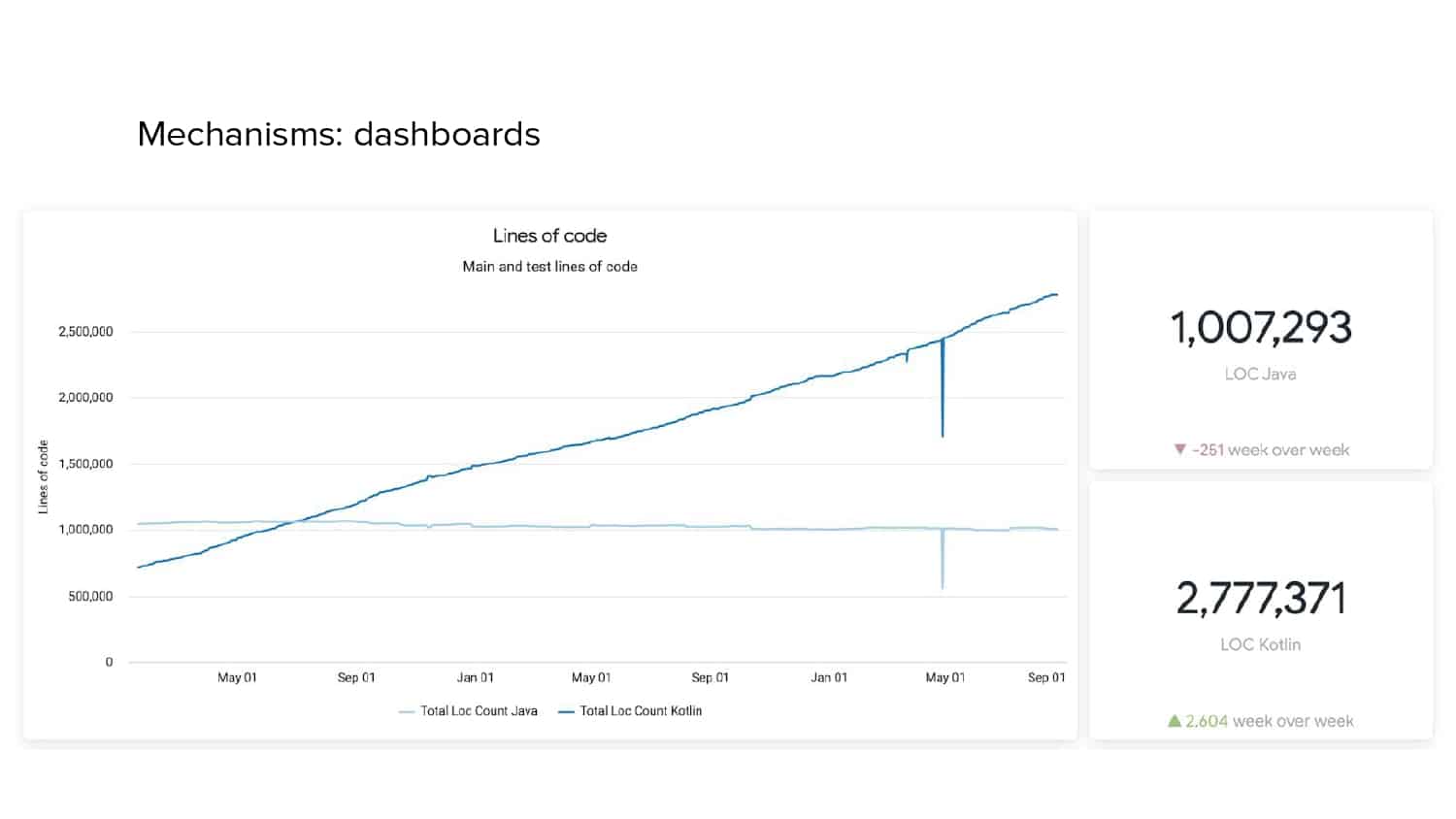
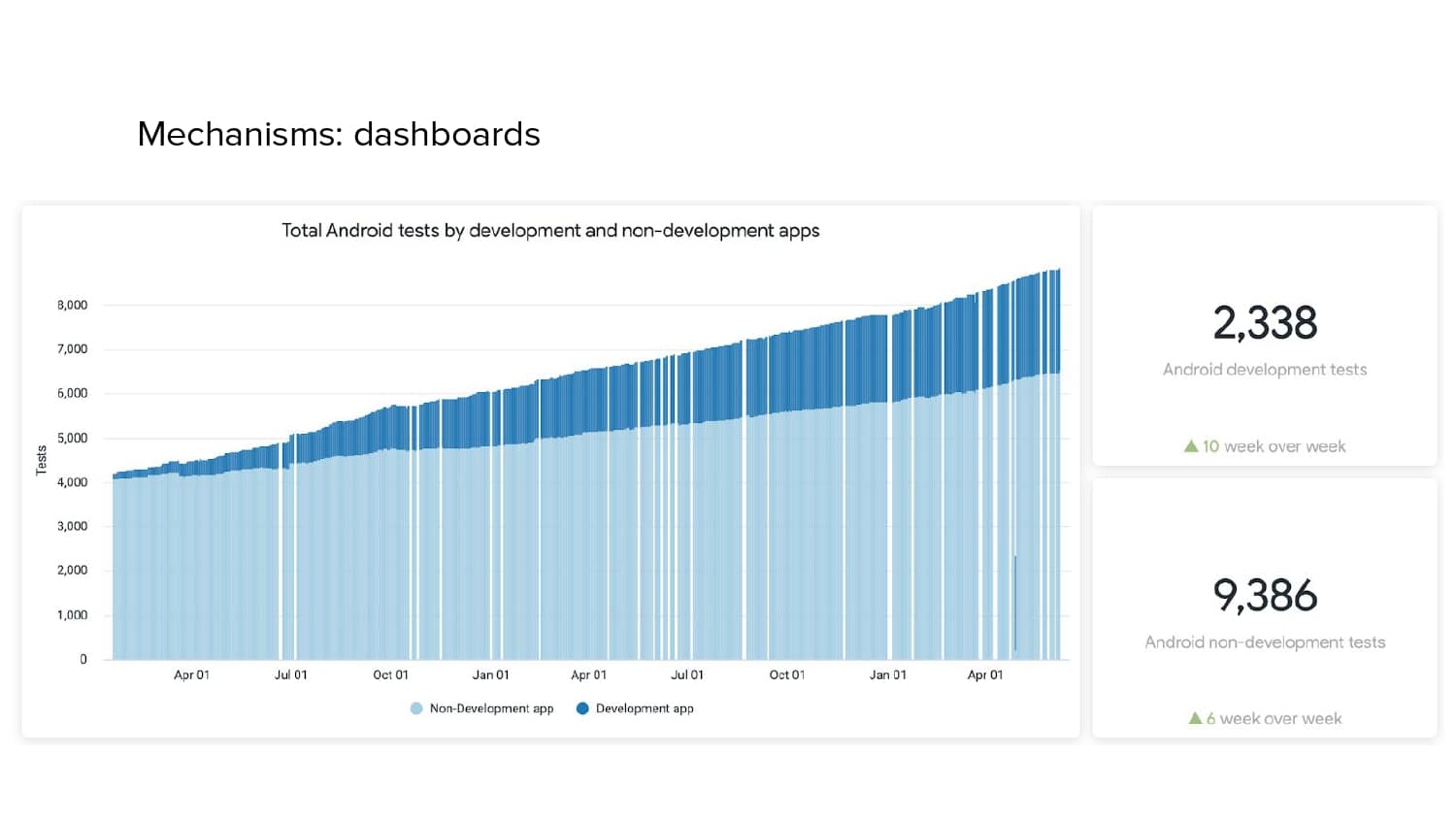
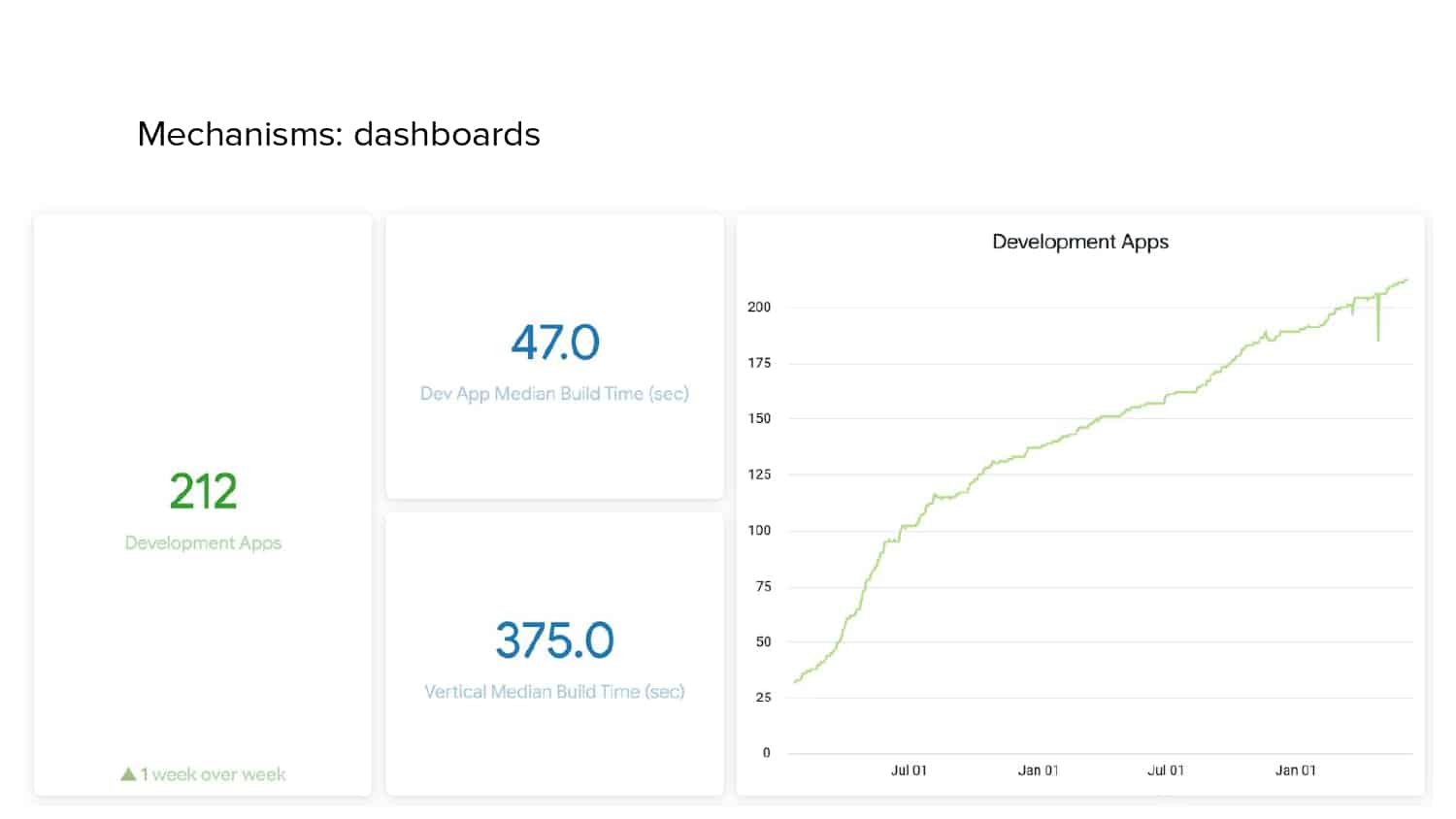
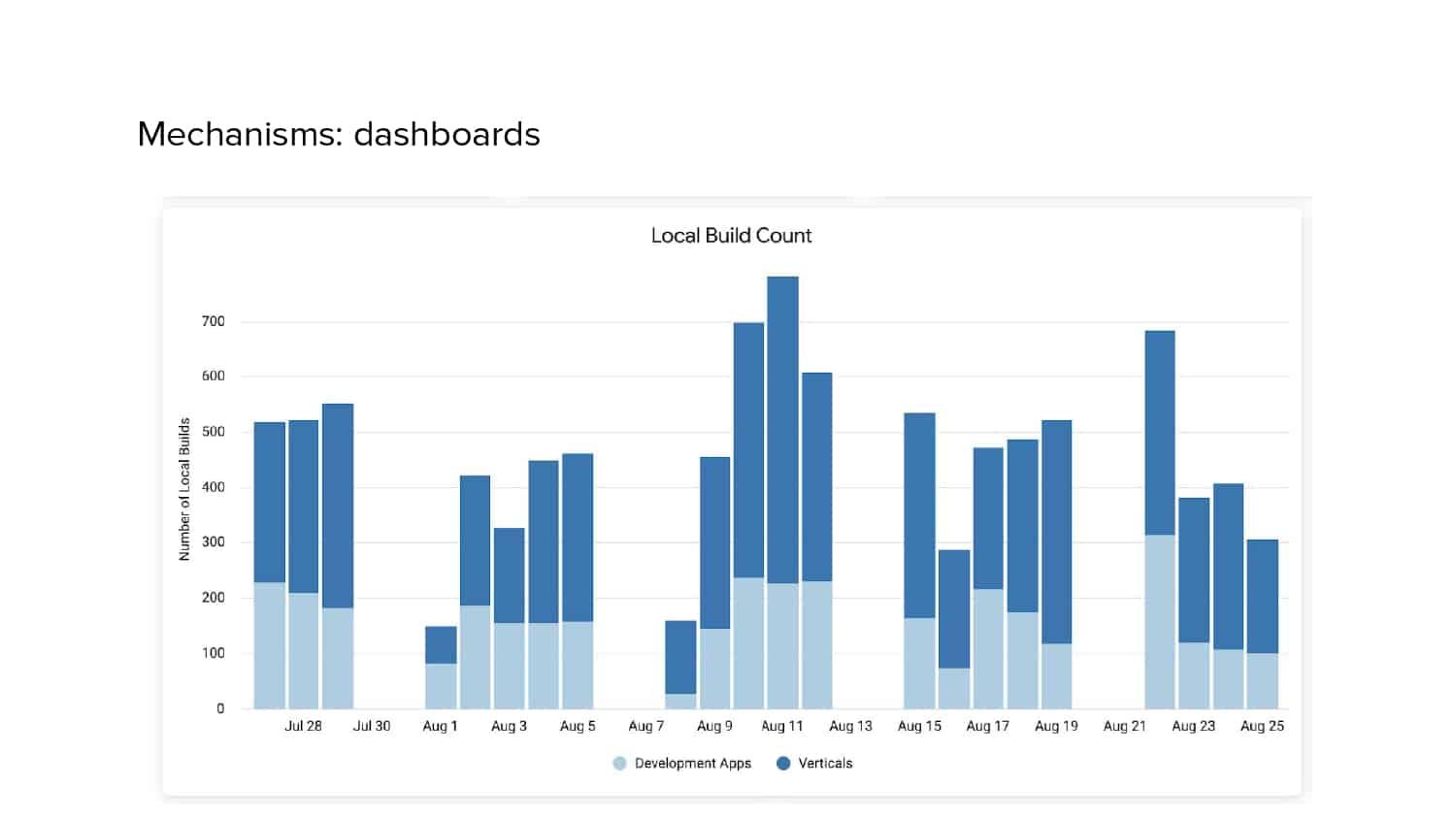
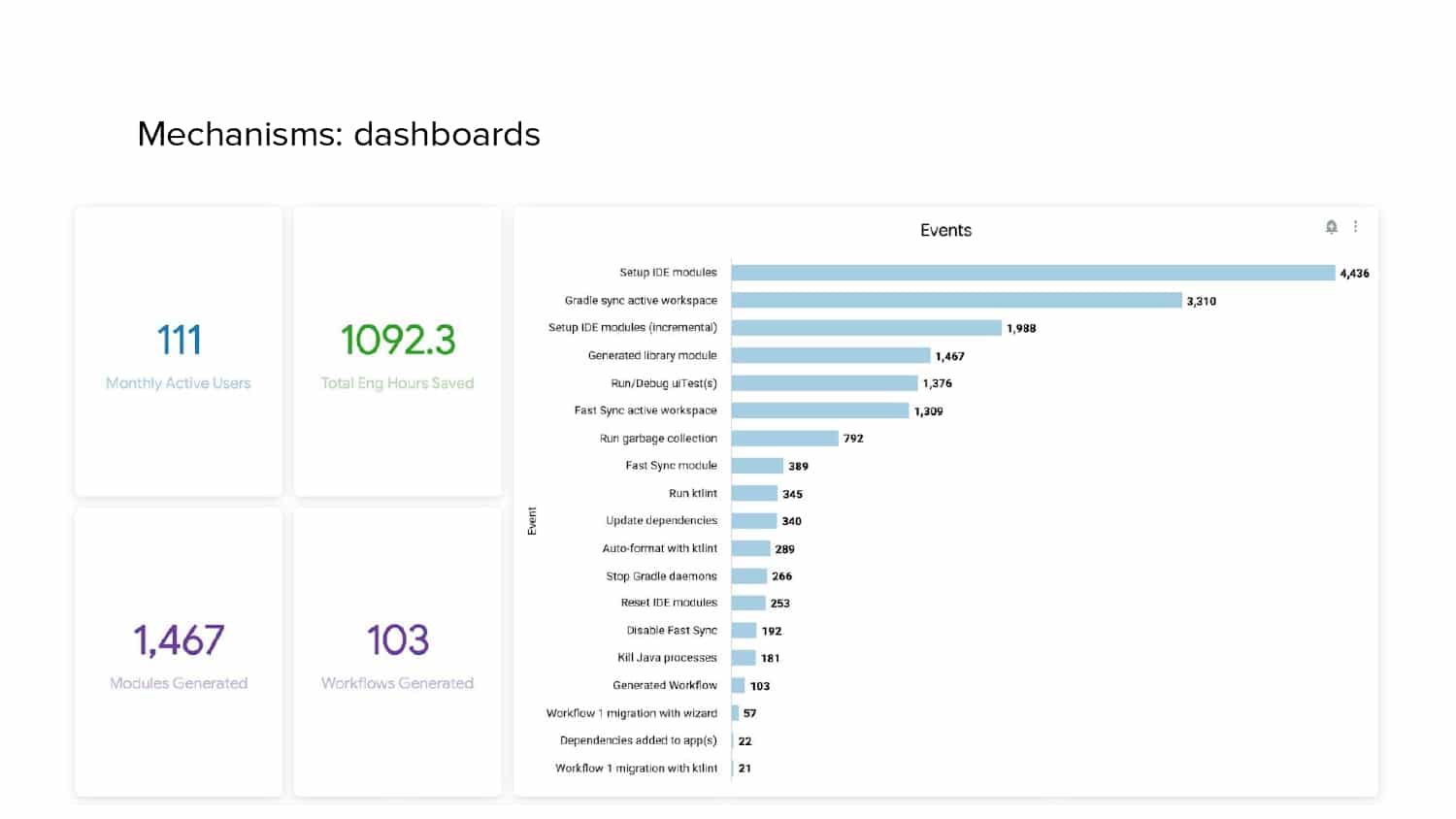
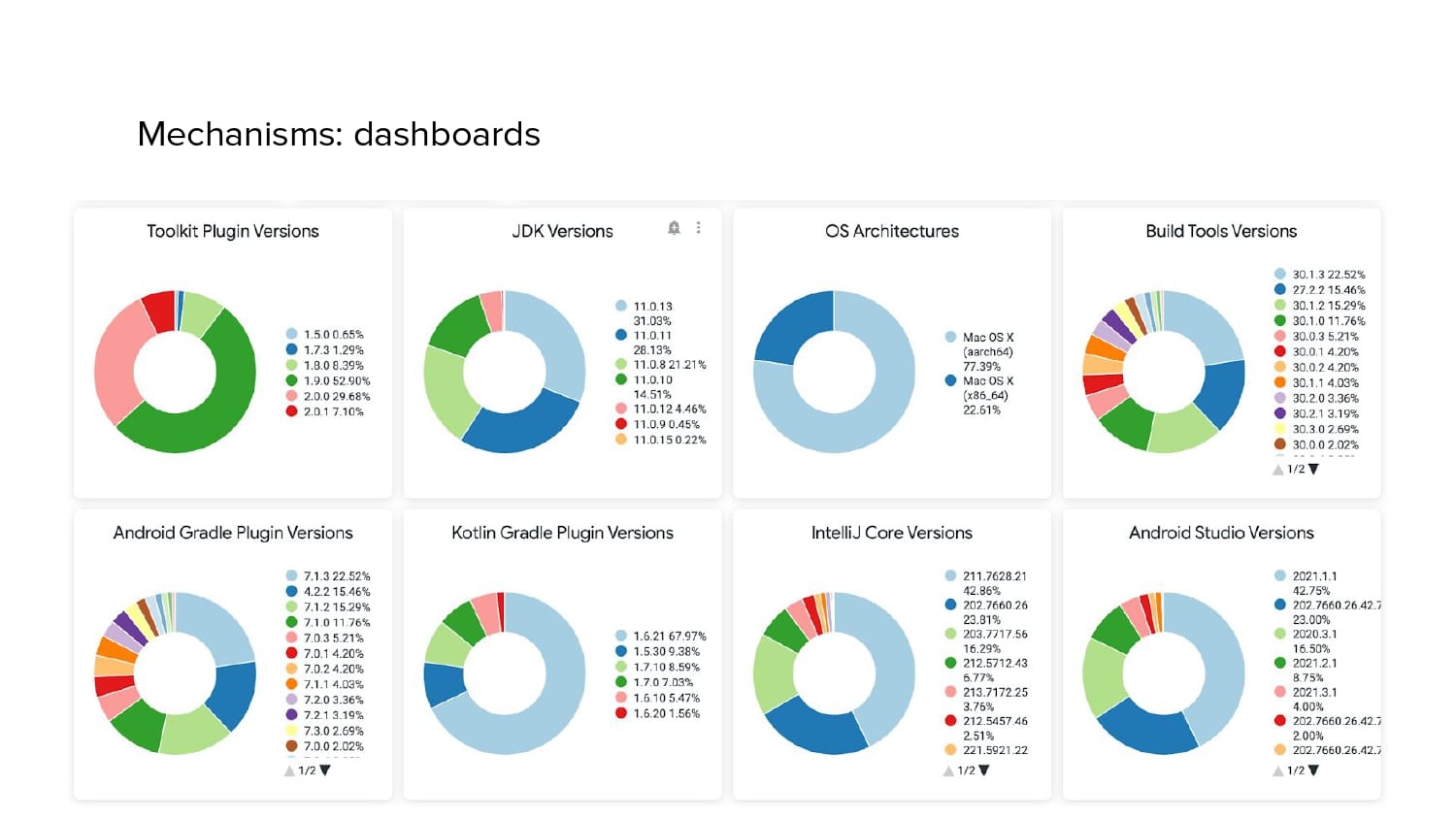
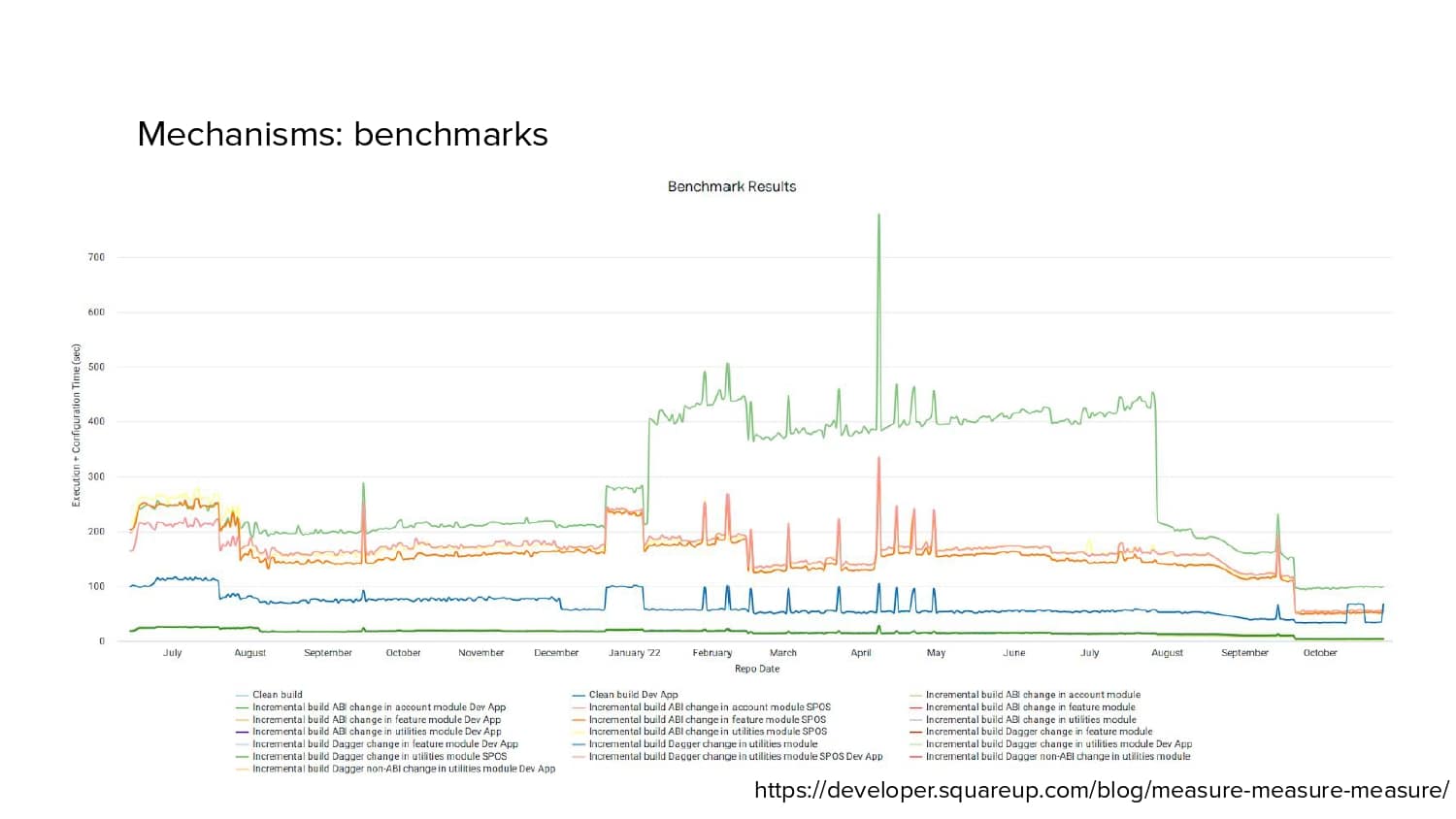
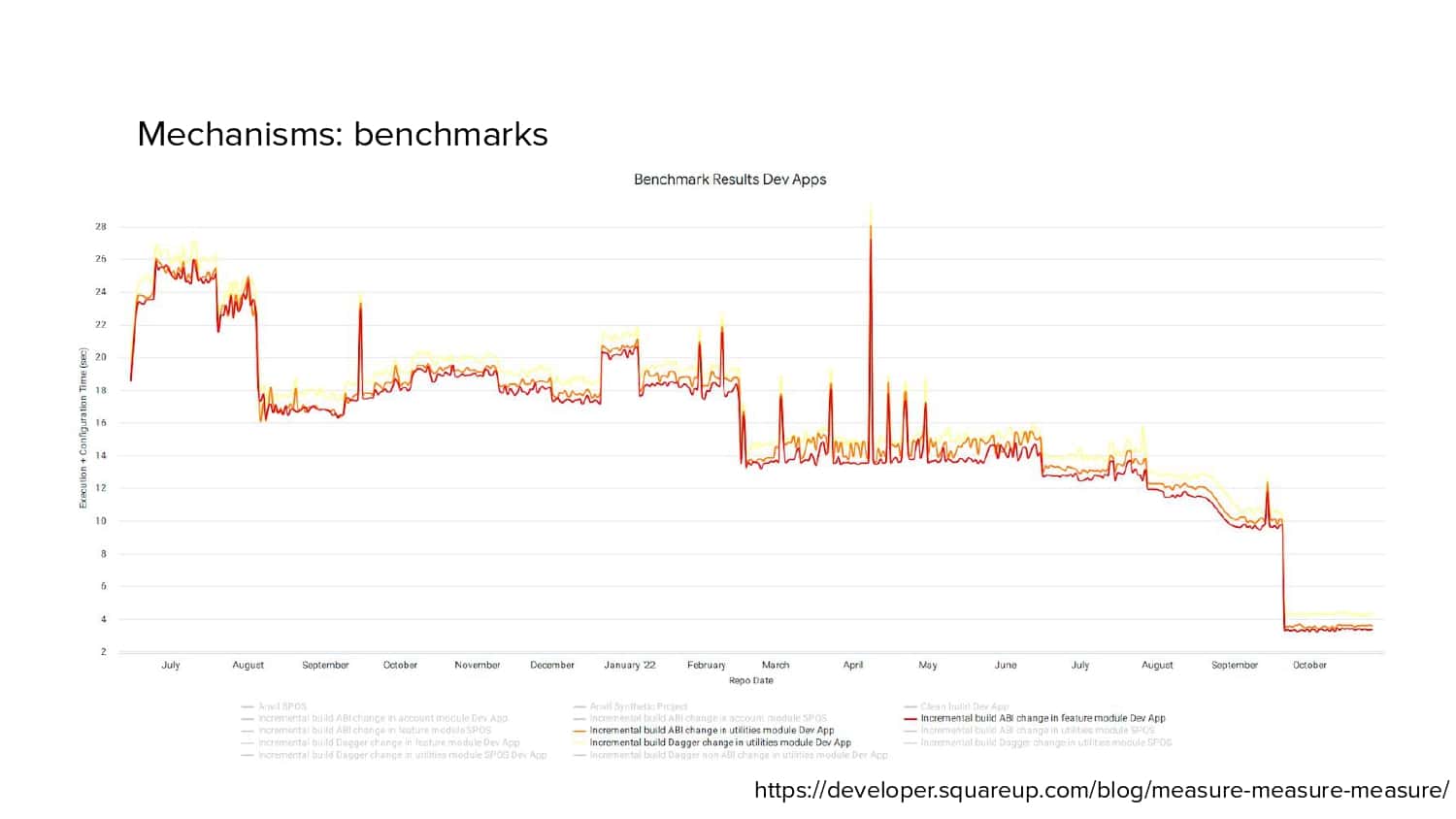
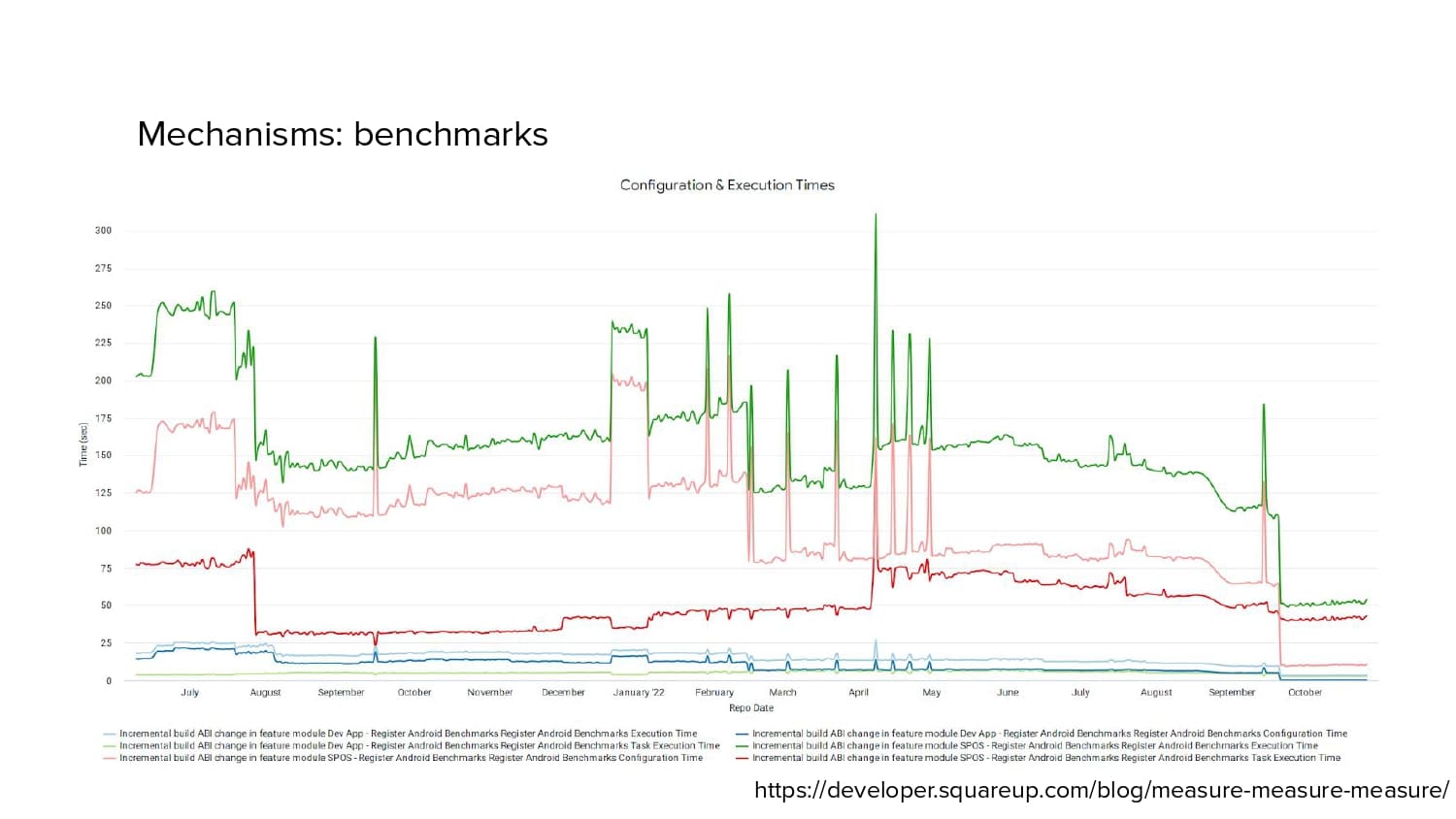
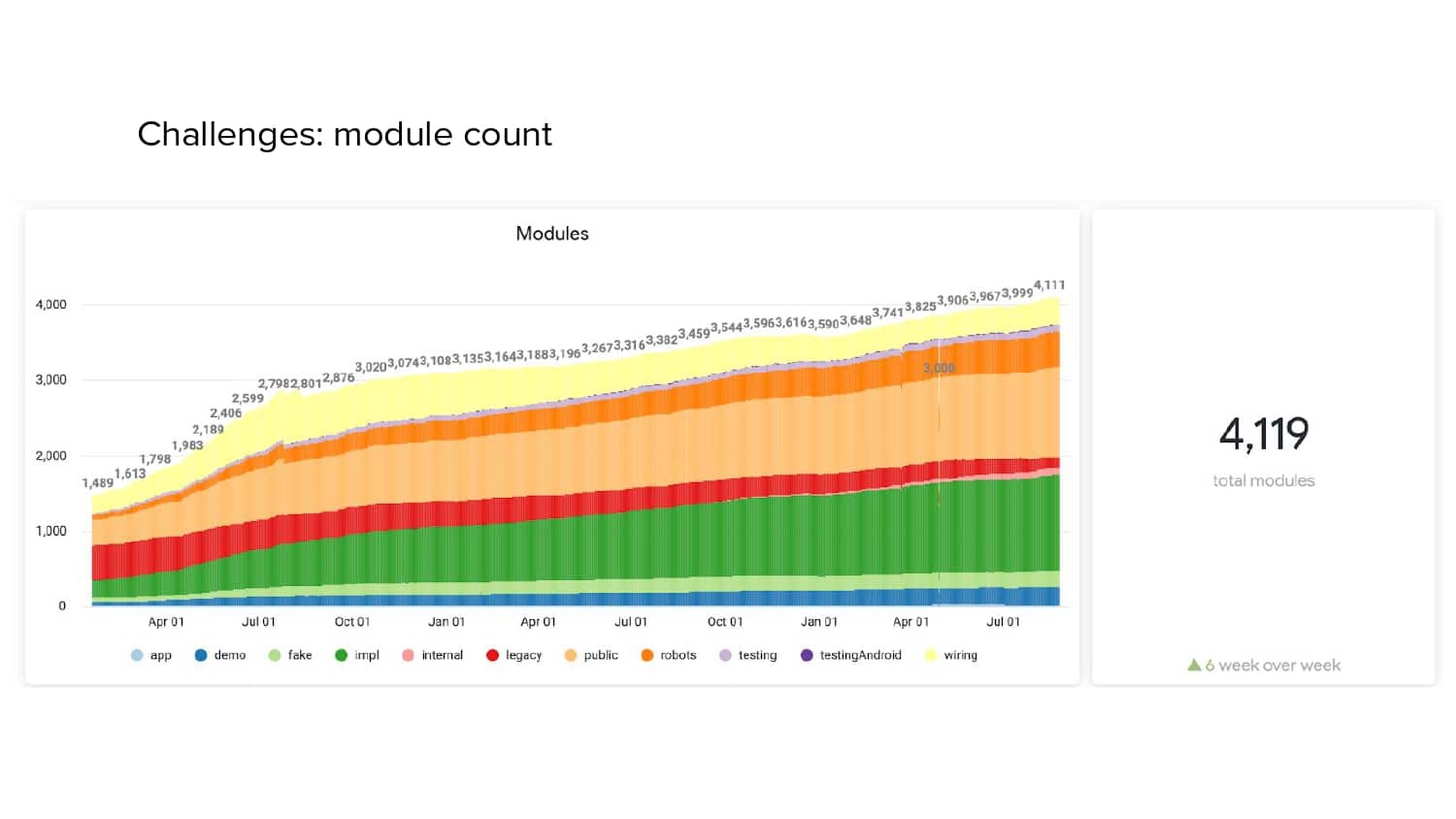
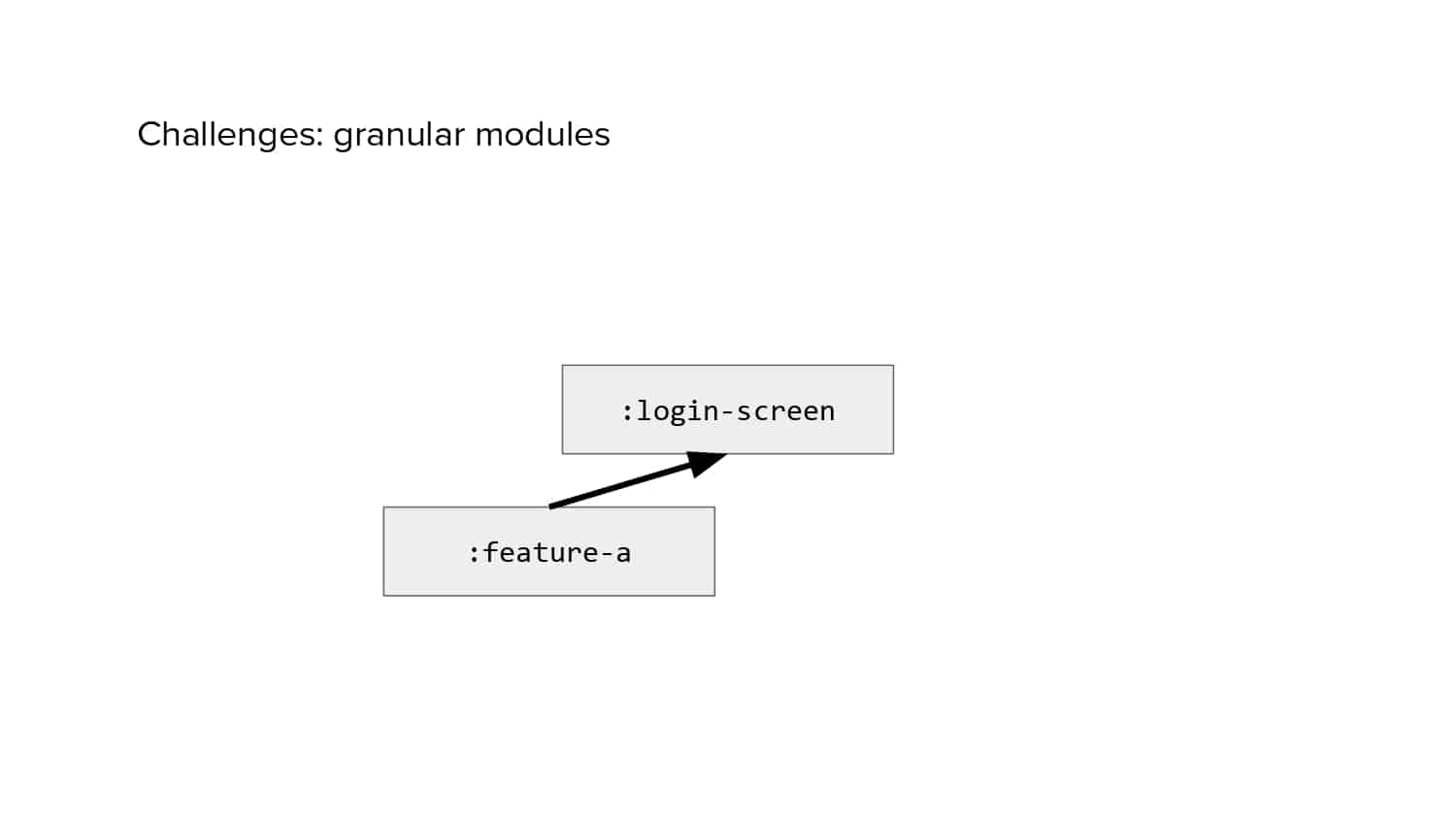
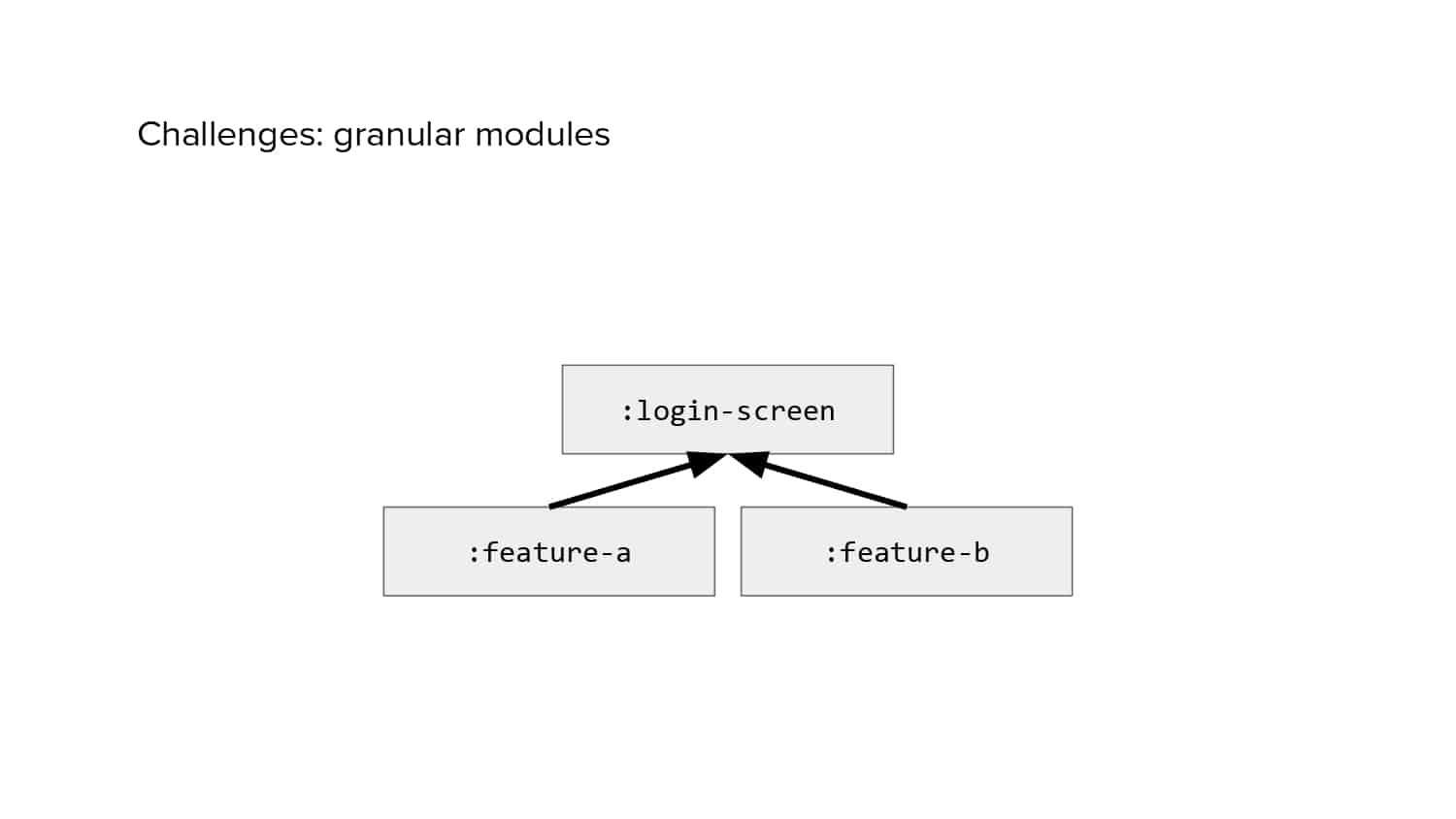
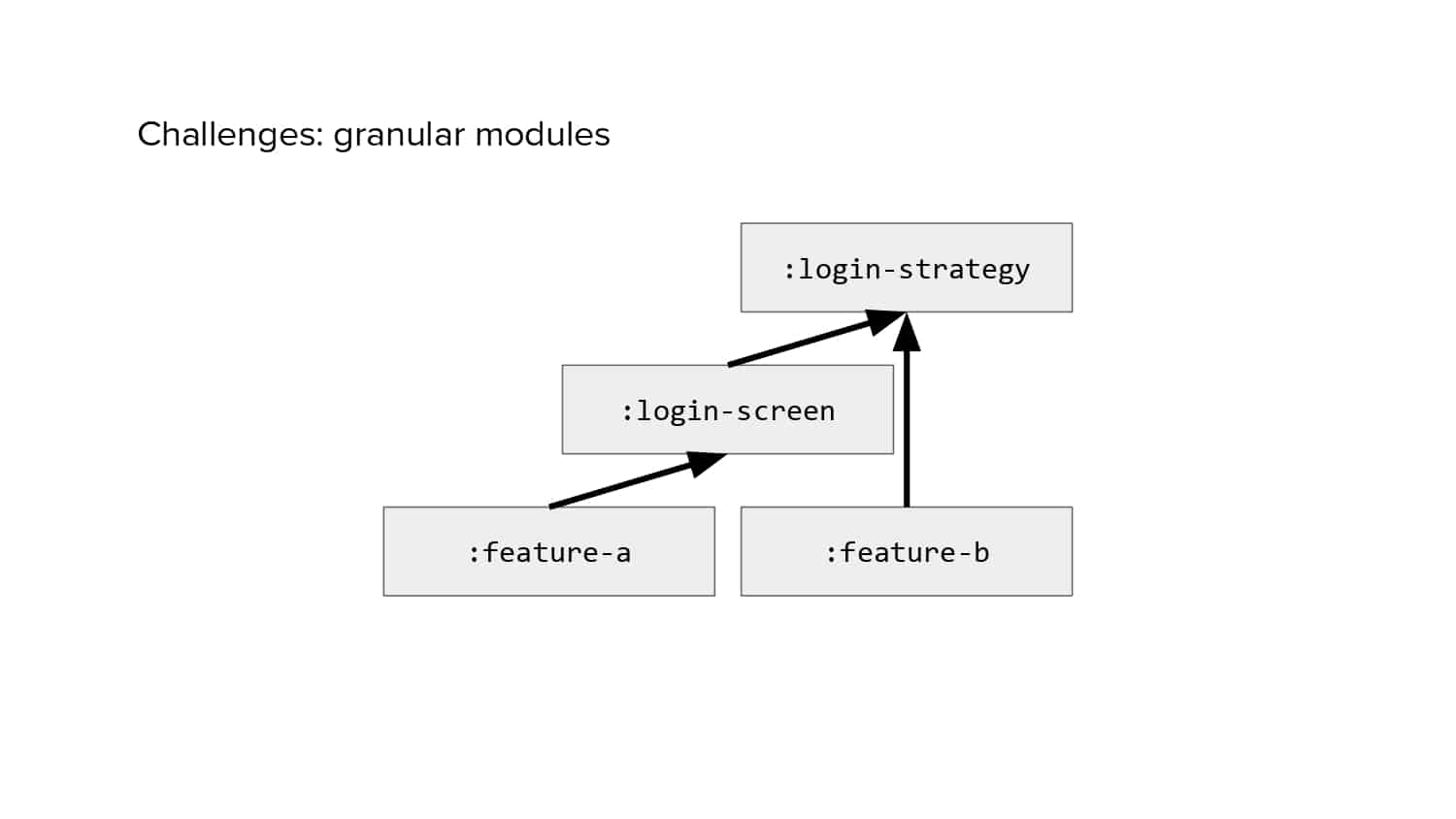
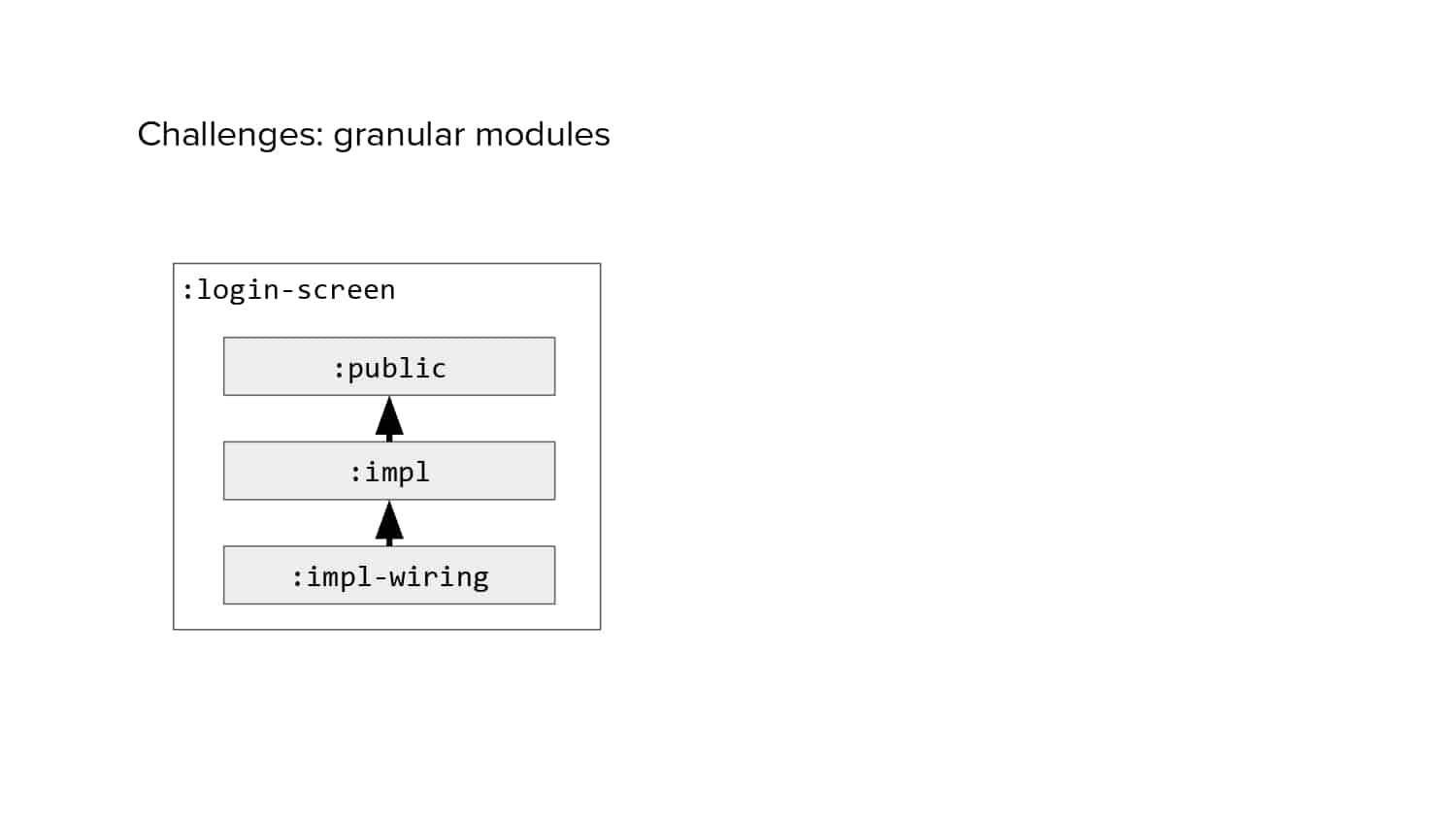
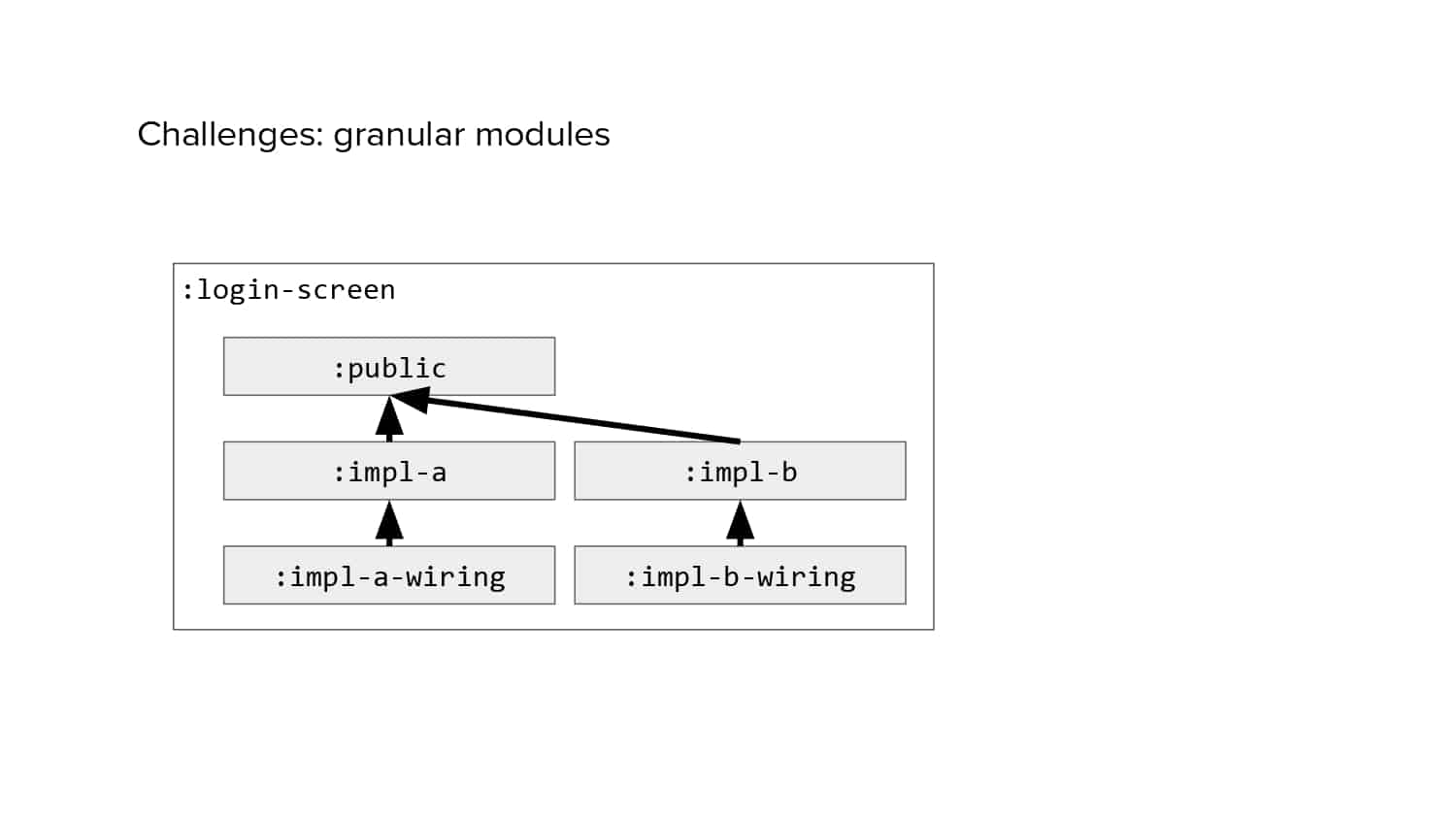
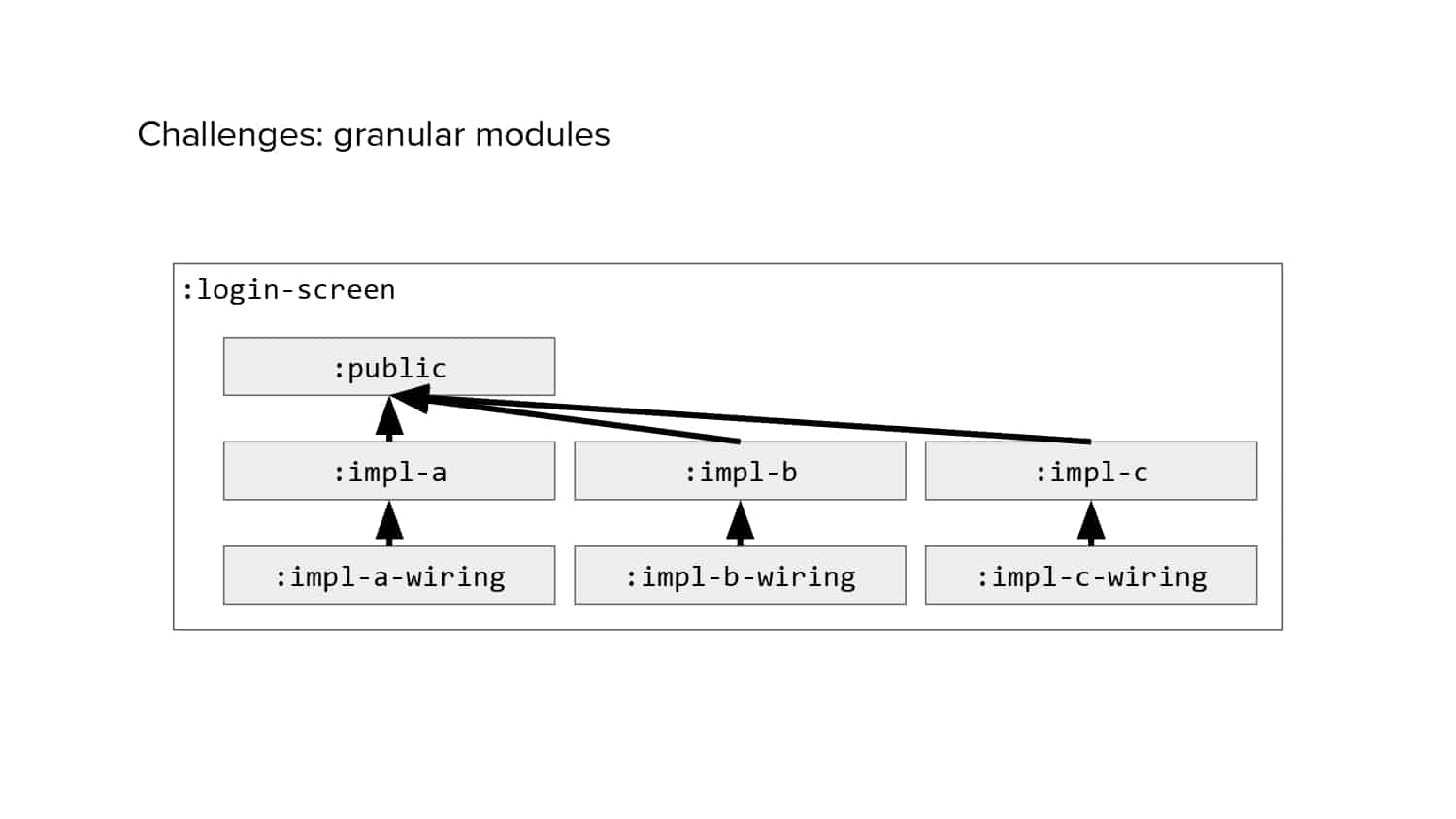
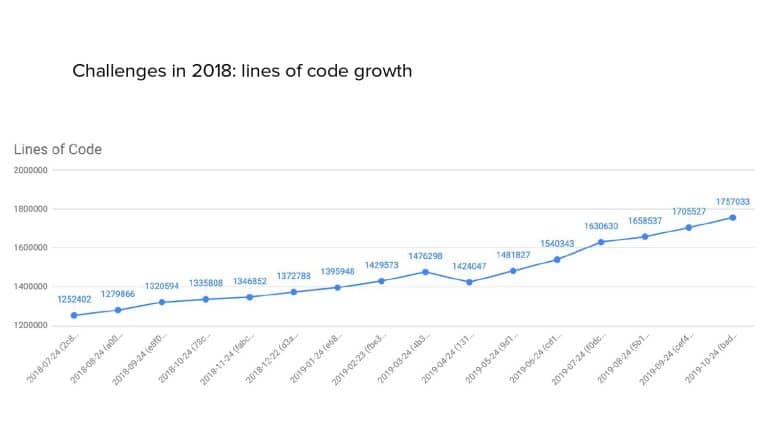
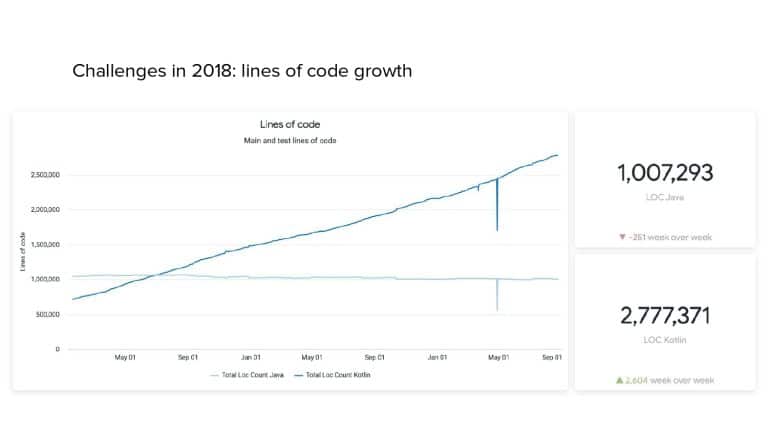
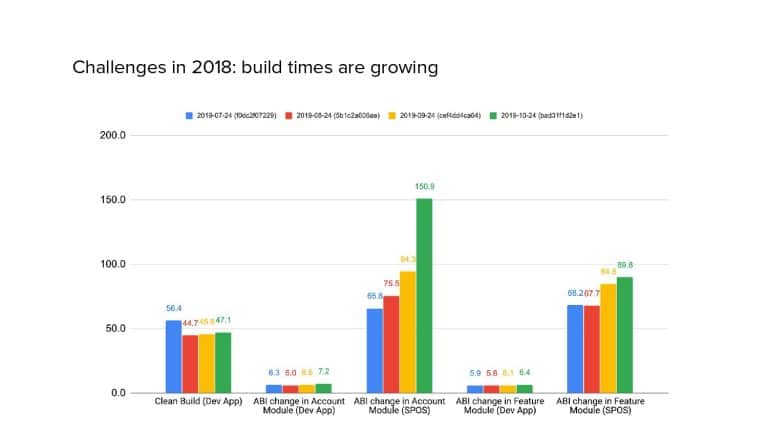
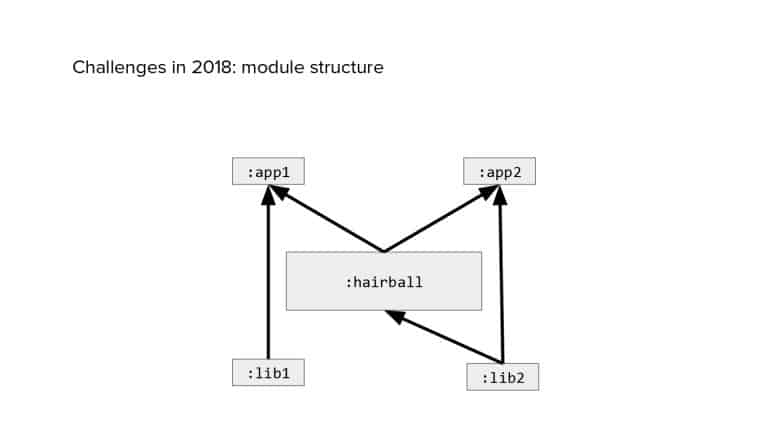
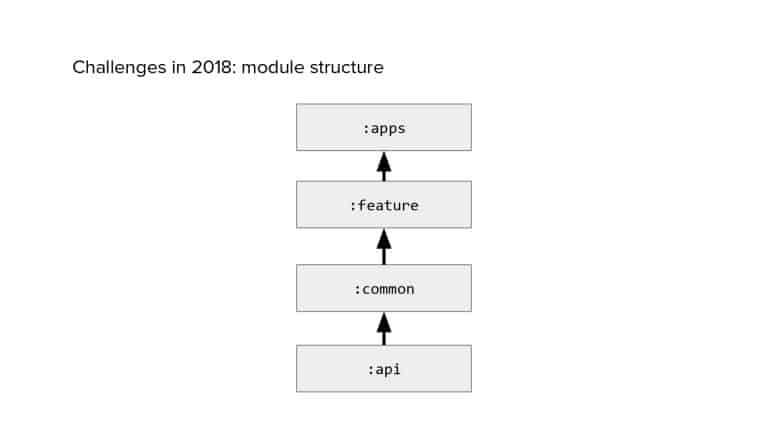
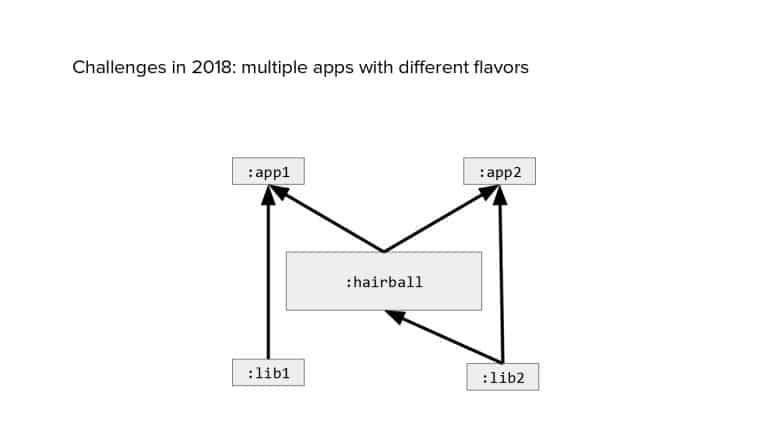
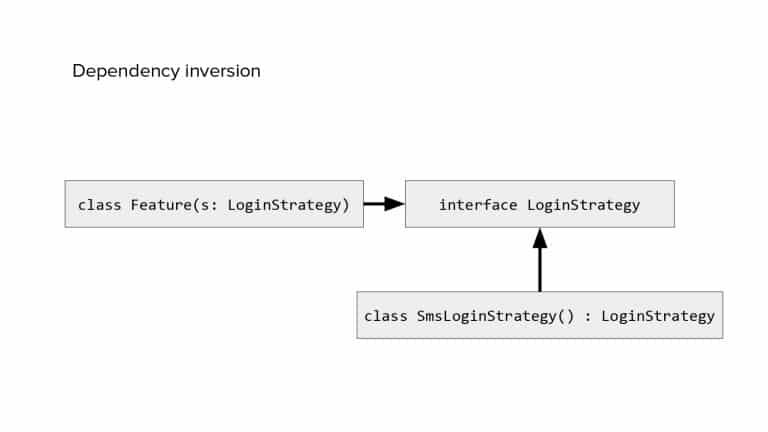
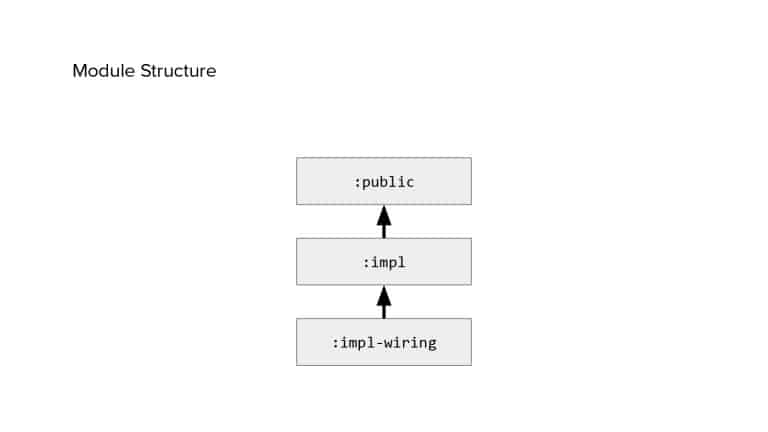
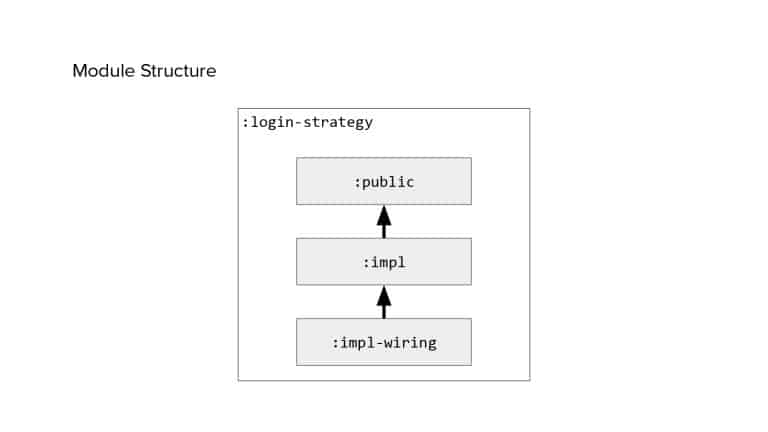
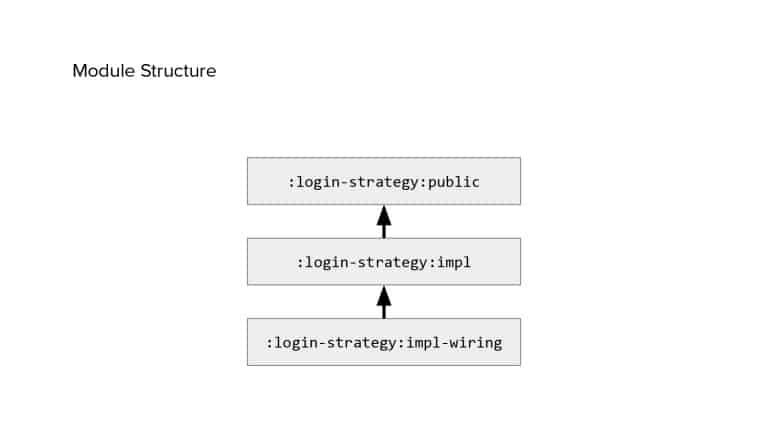
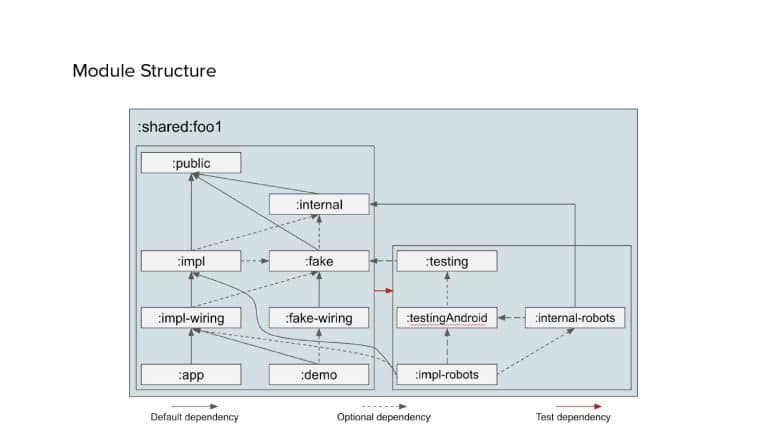
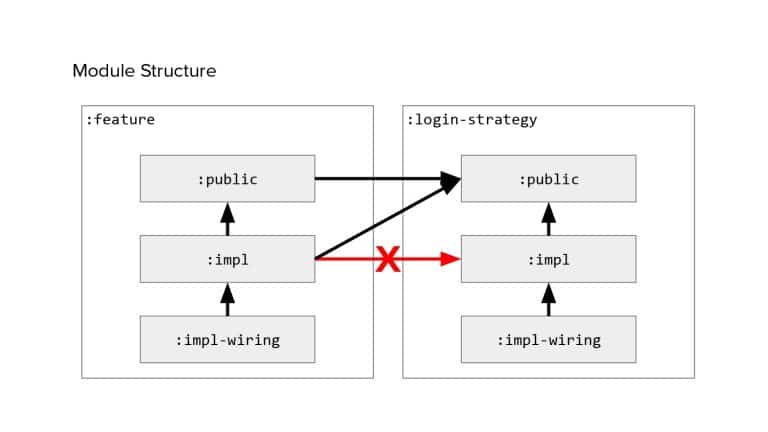
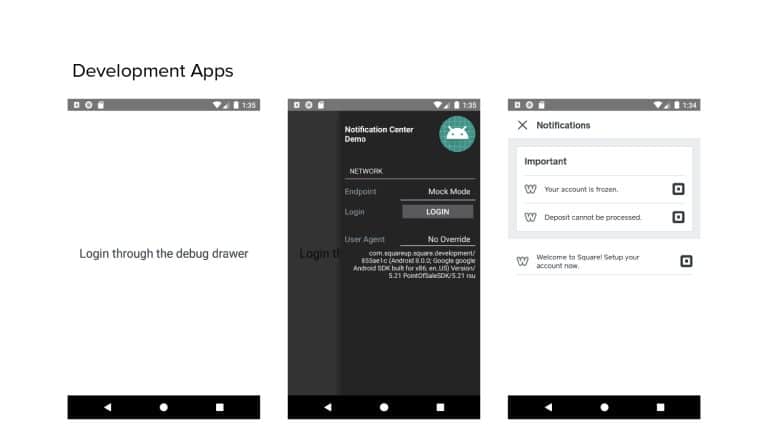
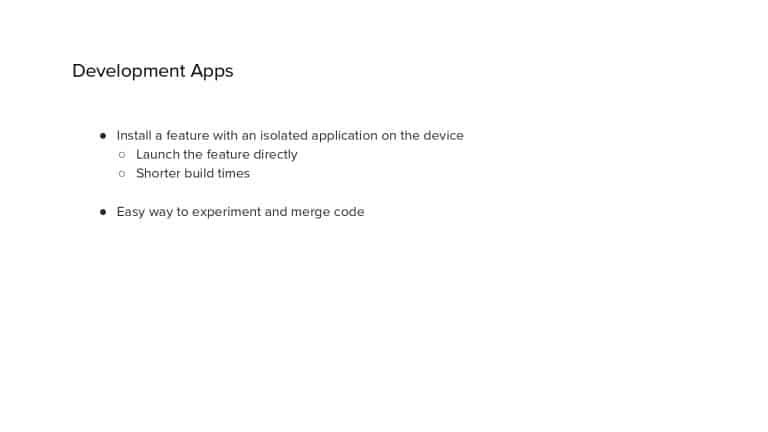
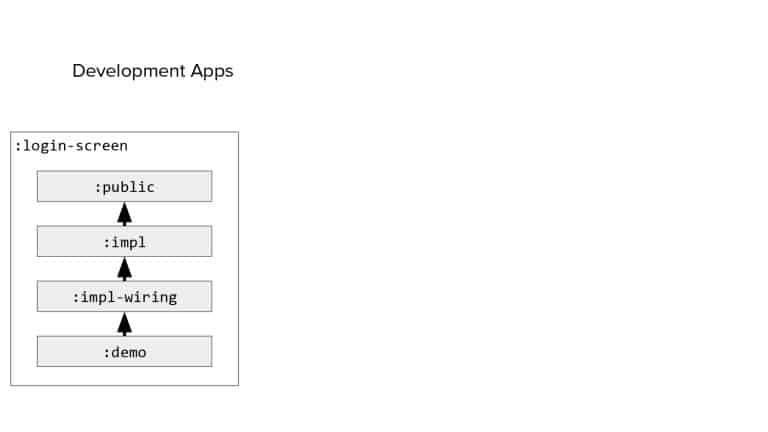
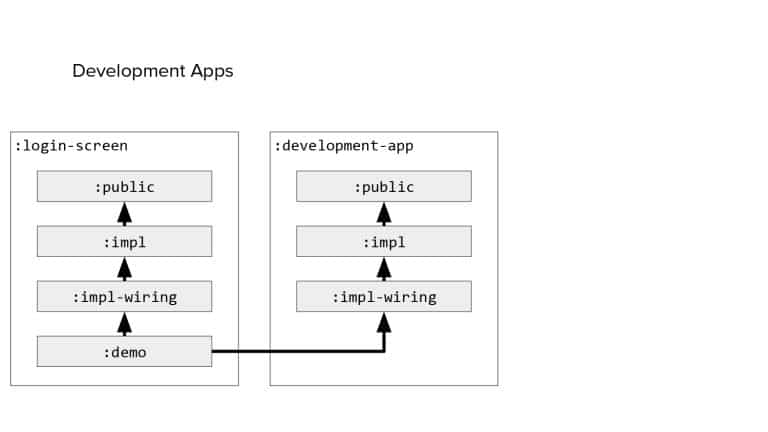
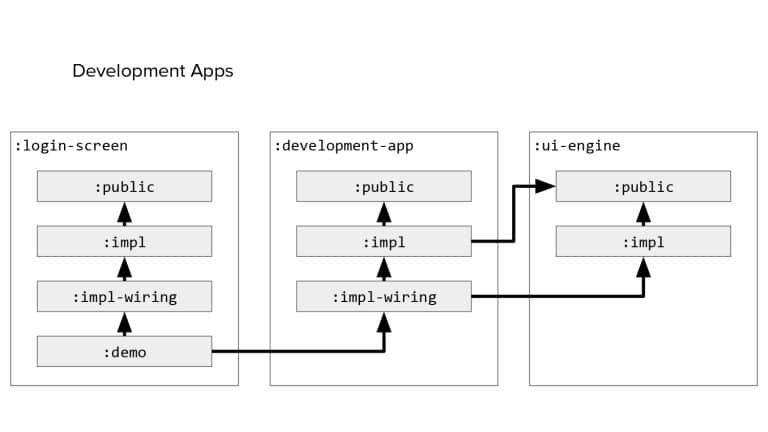
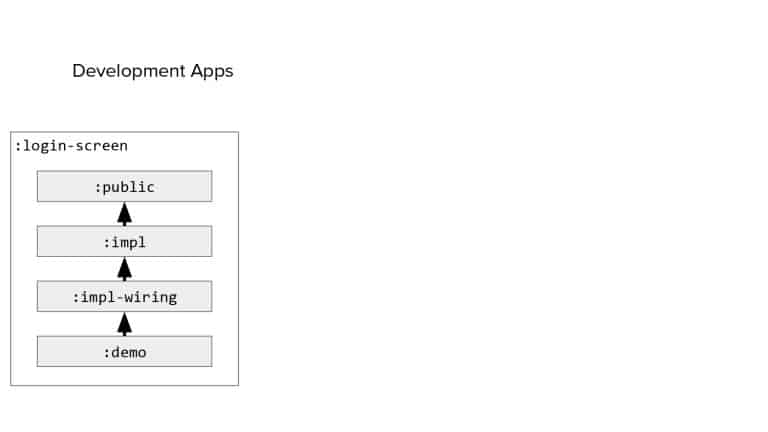
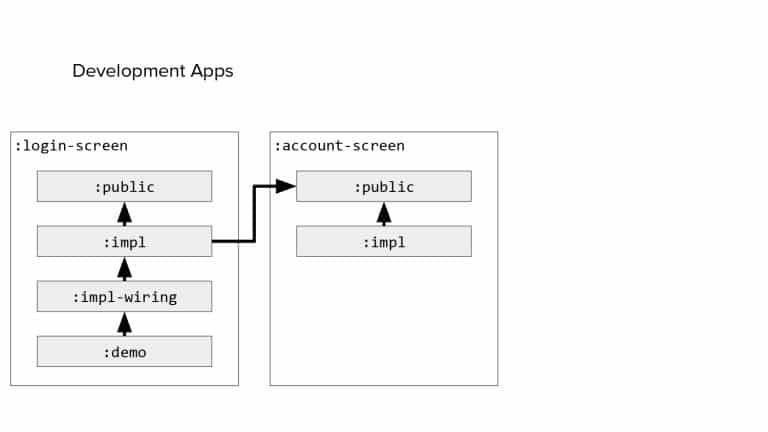
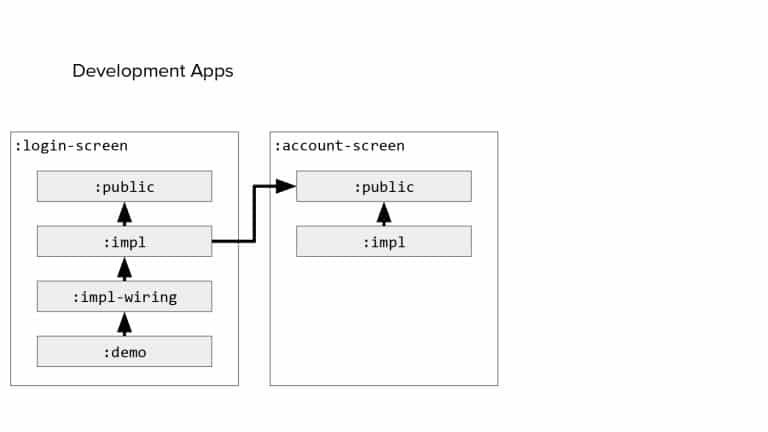
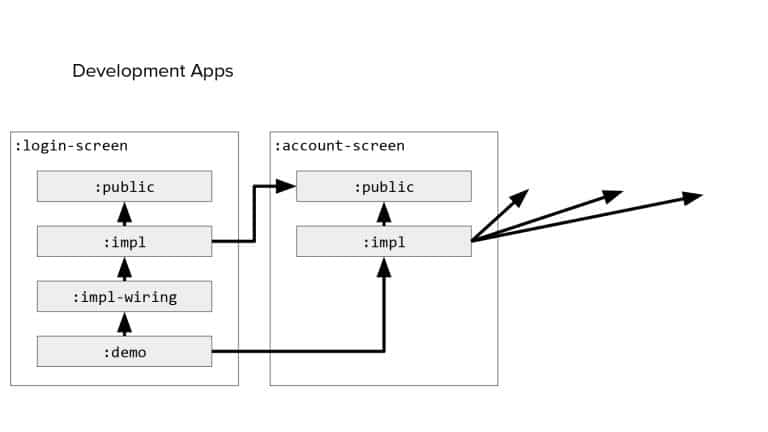
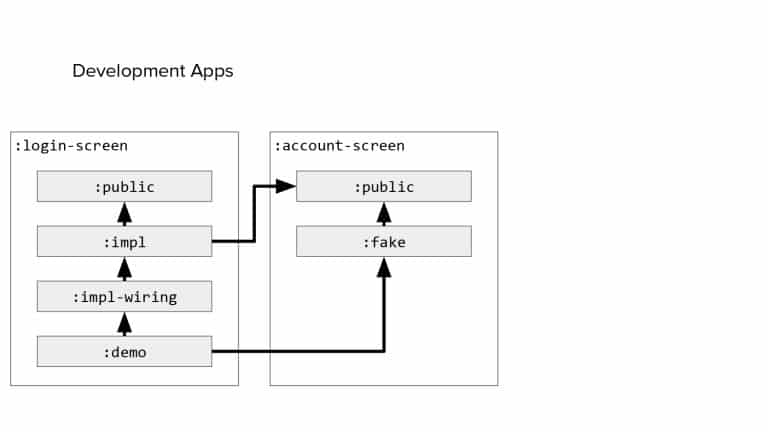
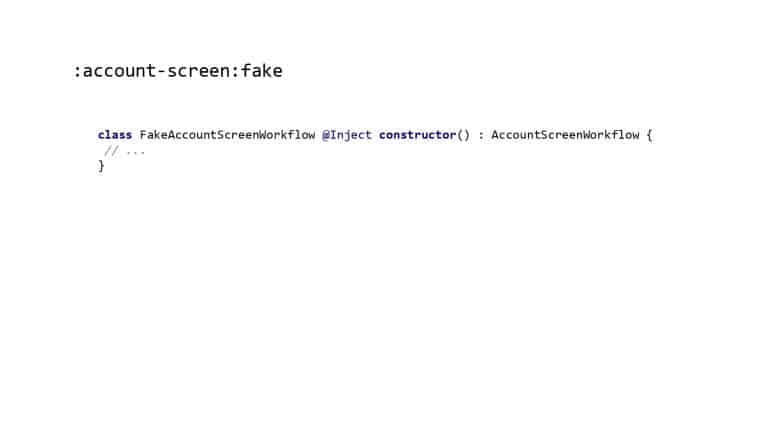
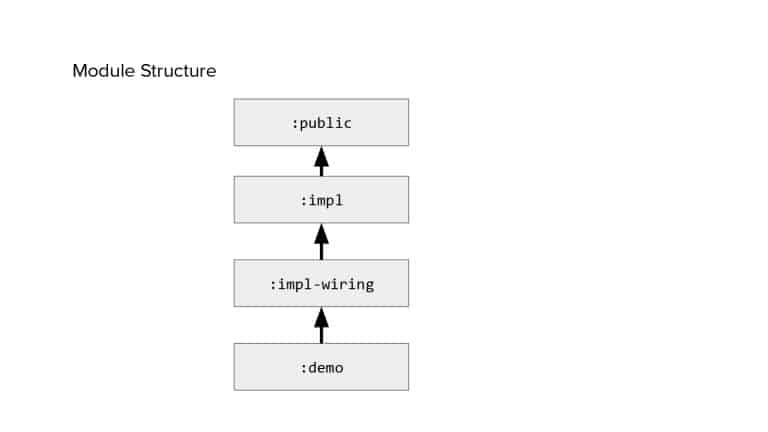
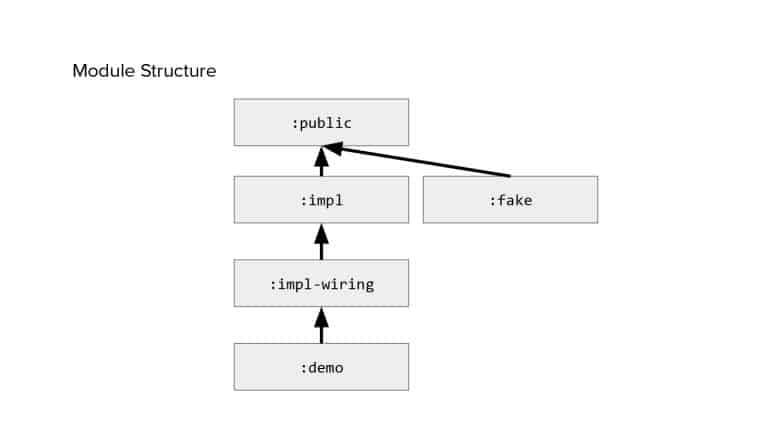
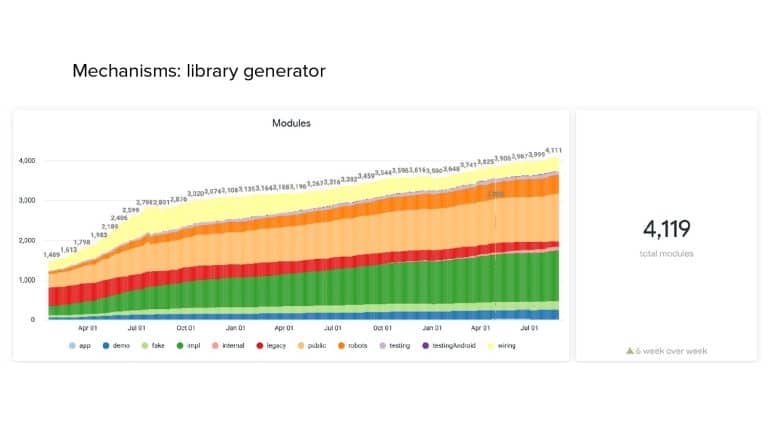
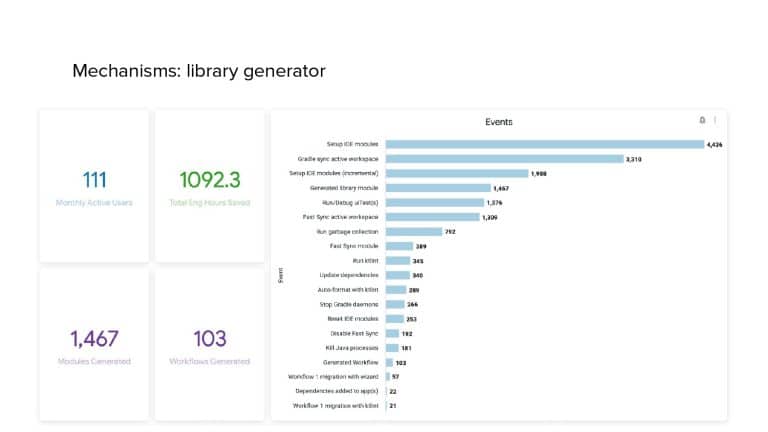
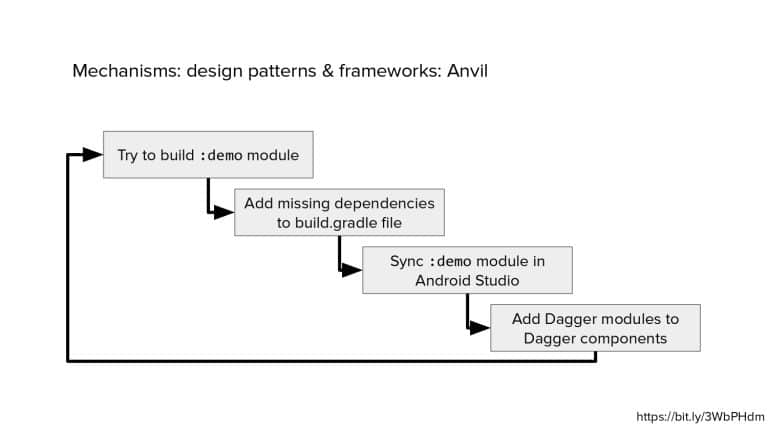
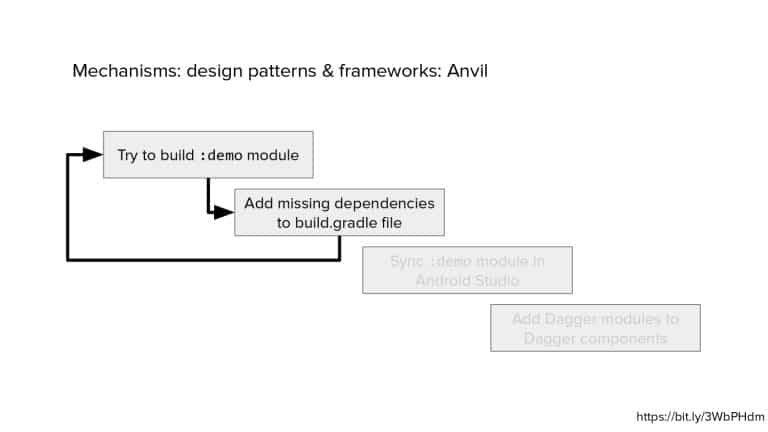
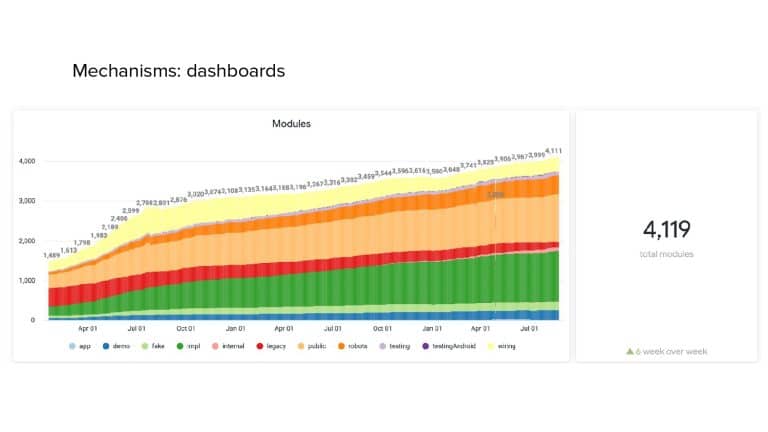
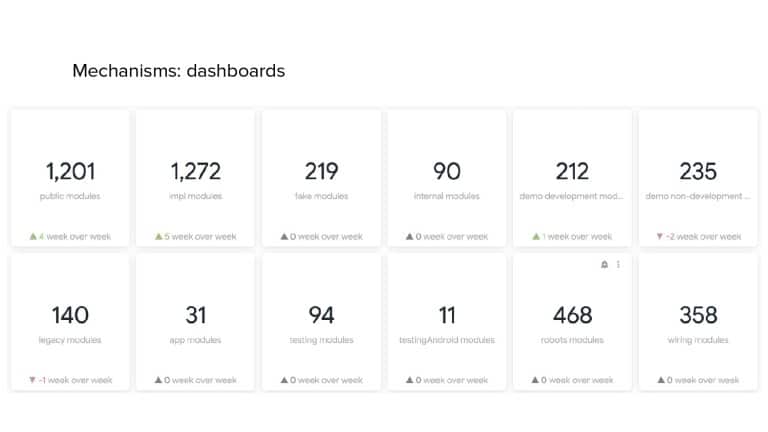
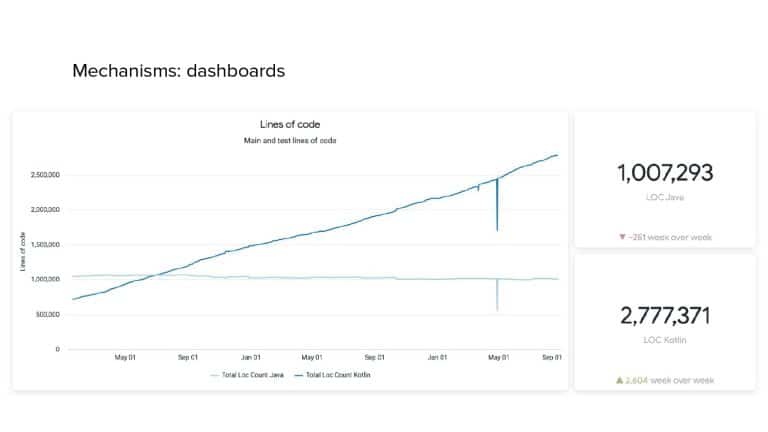
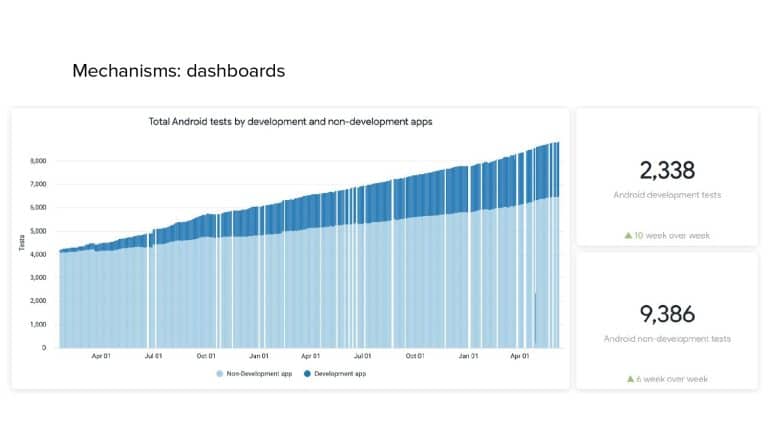
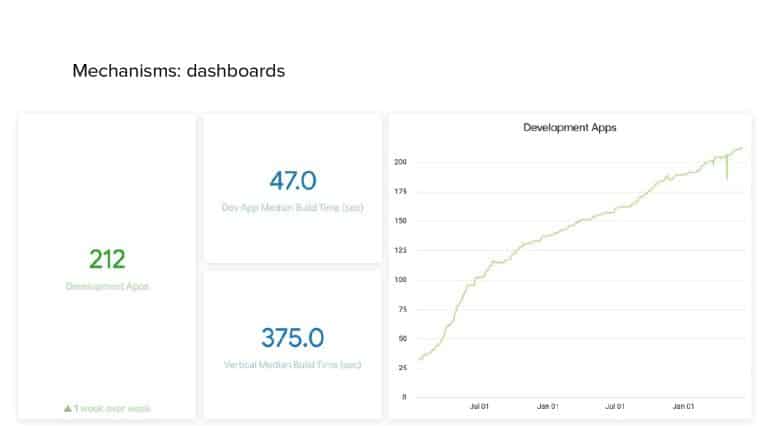
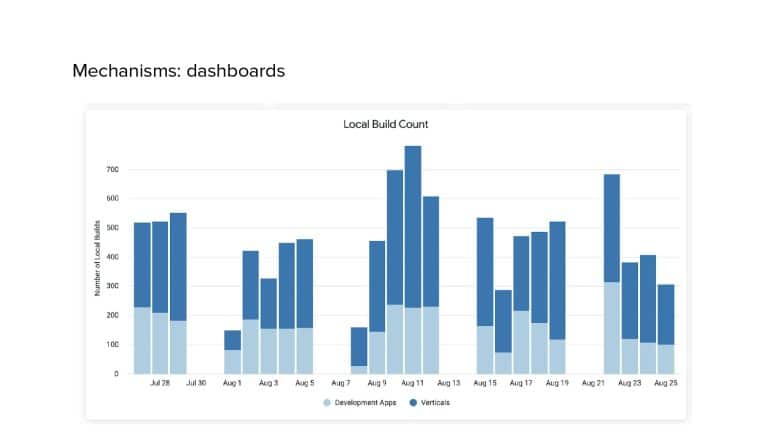
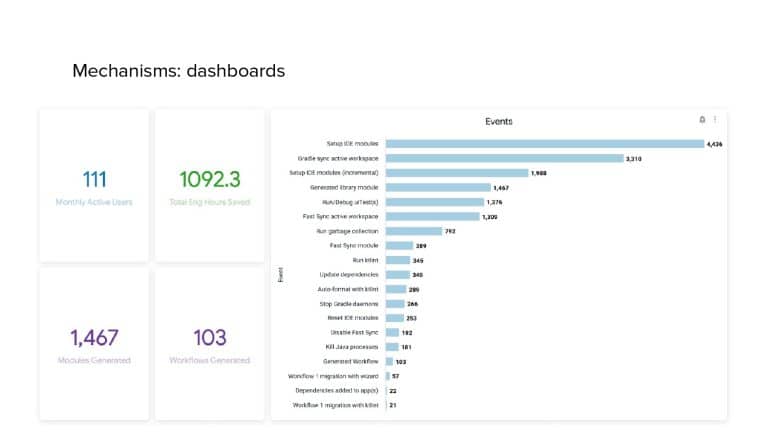
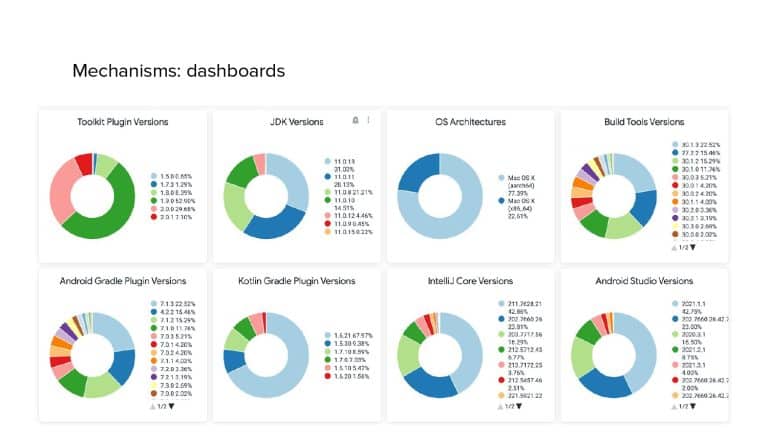
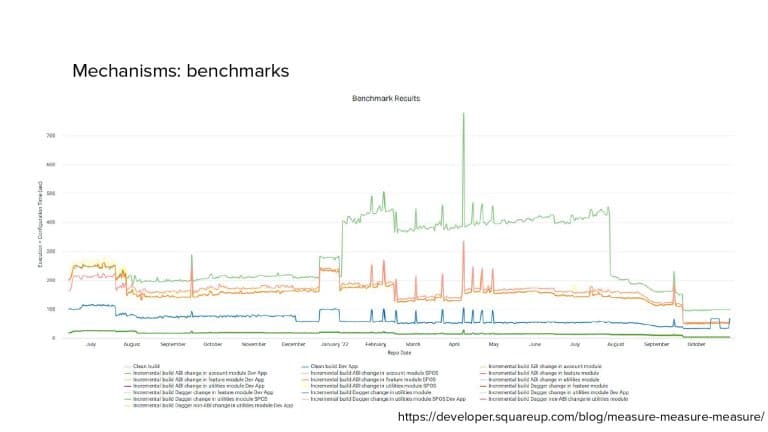
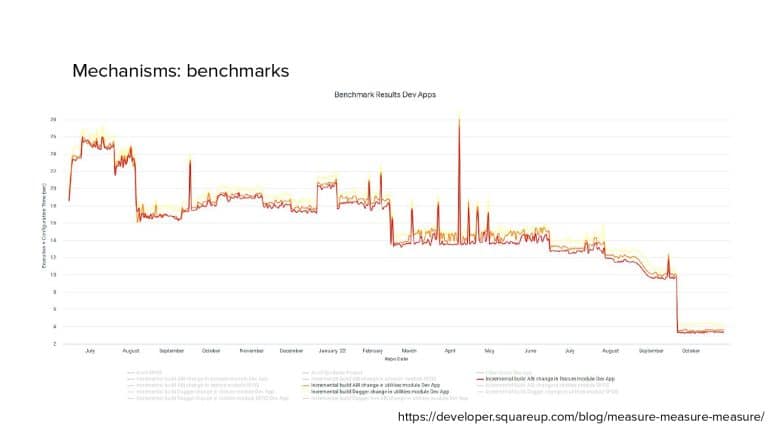
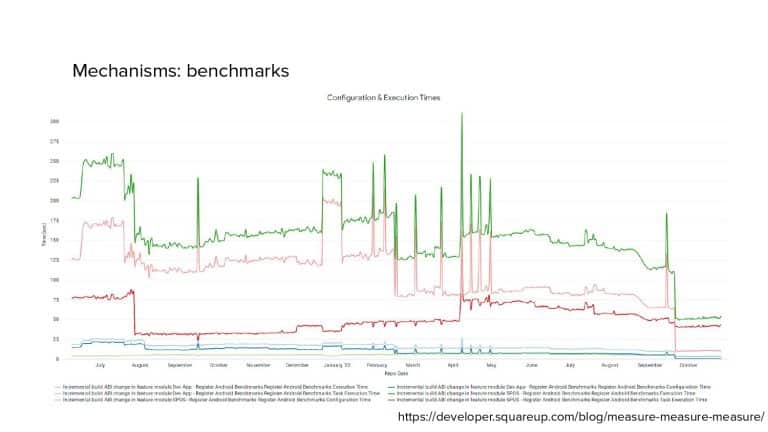
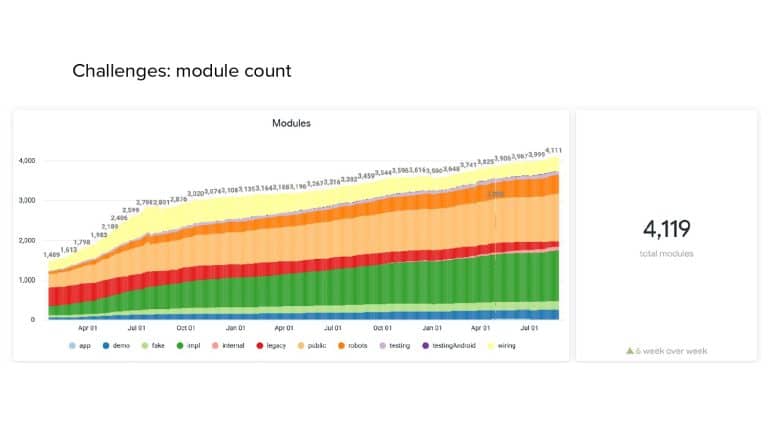
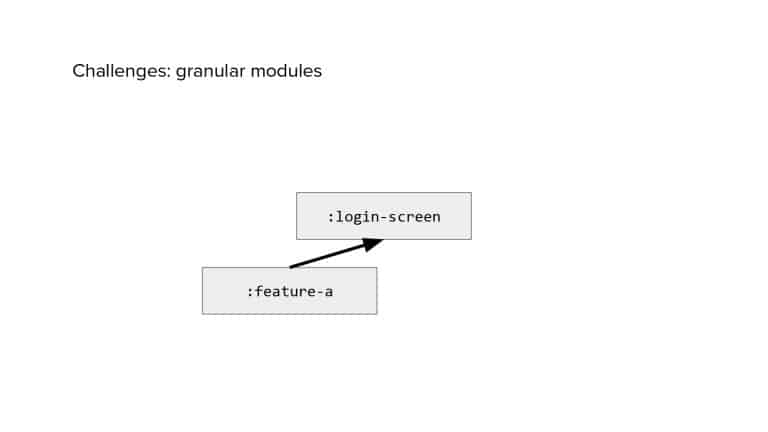
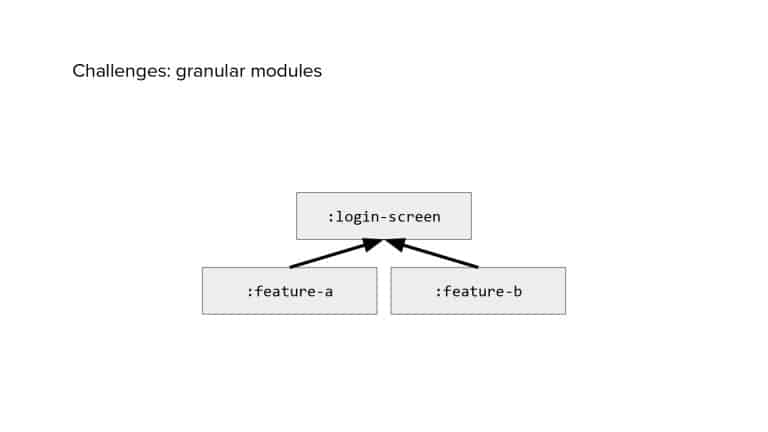
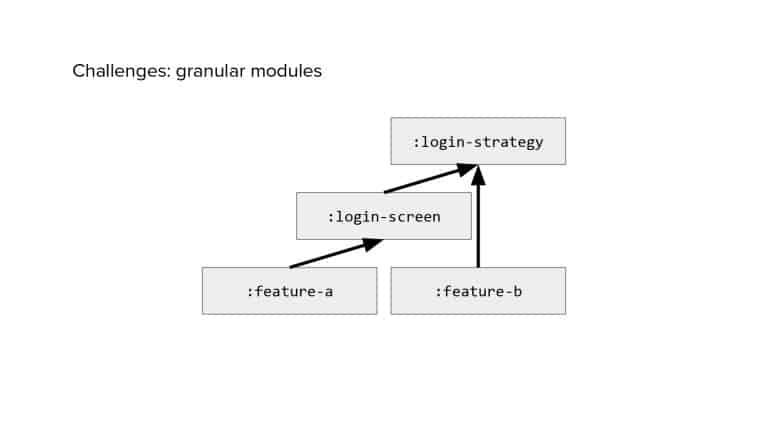
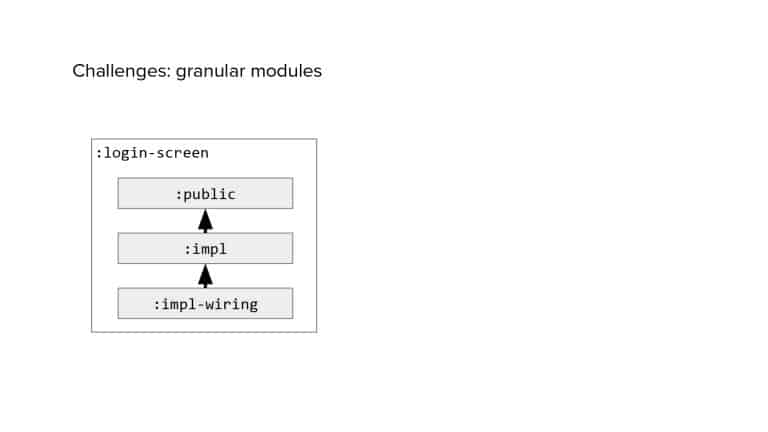
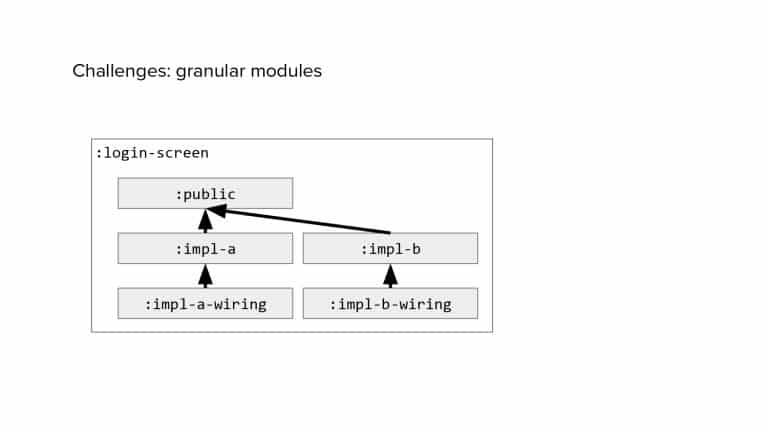
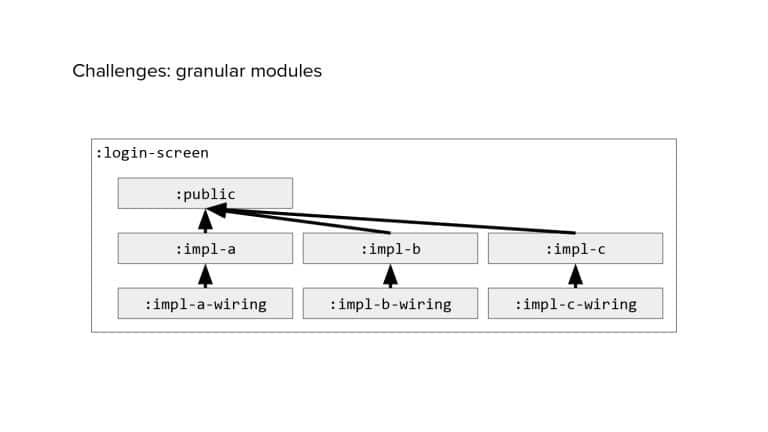
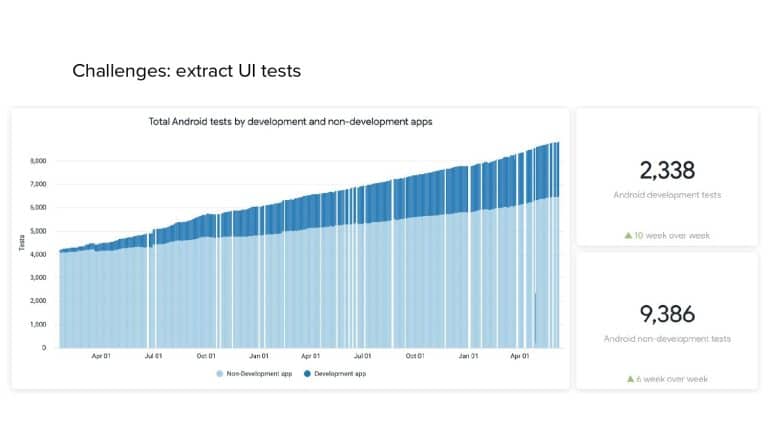
In 2018, Square predicted that their 1 million lines of code (LoC) codebase would double in size every couple of years; a prediction that came true when they reached 4 million LoC in late 2021. This growth negatively impacted build and test times for Square’s 300+ modules and 20+ applications that were all part of the same codebase. Enter Isolated Development, a practice of creating demo applications for sandboxing new features without pulling in everything from the entire application. This led to new opportunities for using DPE techniques (and Gradle Enterprise features) like build and configuration caching, test parallelization, and observability dashboards. This experience revealed more efficient workflows and actionable data for improving productivity that ultimately resulted in a 60% decrease in build and test cycle times.
Ralf Wondratschek is a Principal Engineer at Amazon (formerly at Square) who helps simplify the delivery process of millions of packages. This includes providing a platform for internal and external partners to integrate their features, shipping applications for vehicles and other form factors, and making the whole delivery process safer. Prior to joining Amazon, Ralf worked for Evernote and several companies in Germany, and he has published four apps in the Google Play Store as an independent developer.

Gradle Enterprise customers like Square use the Gradle Enterprise Build Cache to reduce build and test times by avoiding re-running code that hasn’t changed since the last successful build, and Test Distribution to further improve test times (often 90% of the entire build process) by parallelizing tests across all available infrastructure. You can learn more about these features by running a free Build Scan™ for Maven and Gradle Build Tool, watching videos, and registering for our free instructor-led Build Cache deep-dive training.