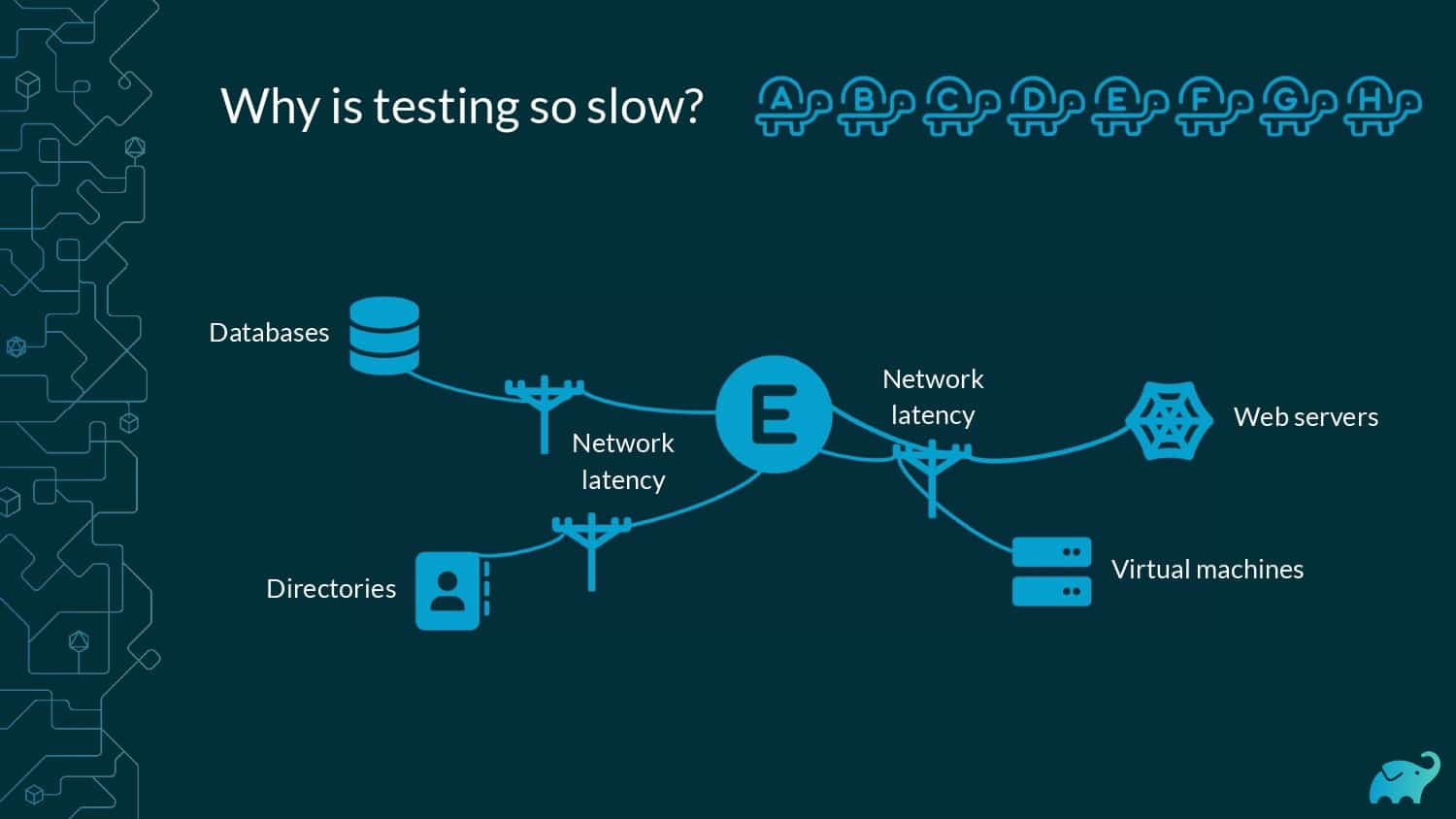
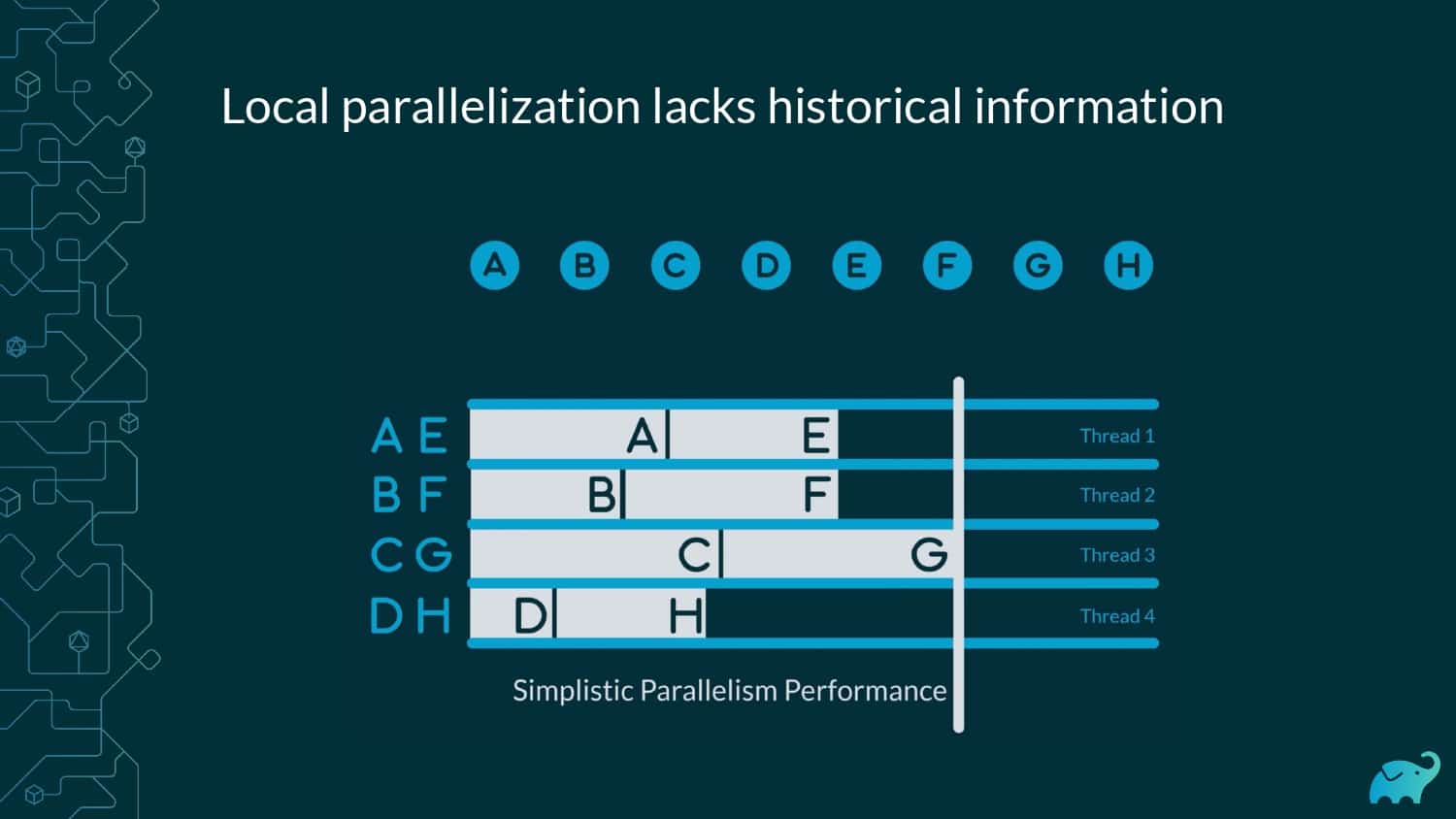
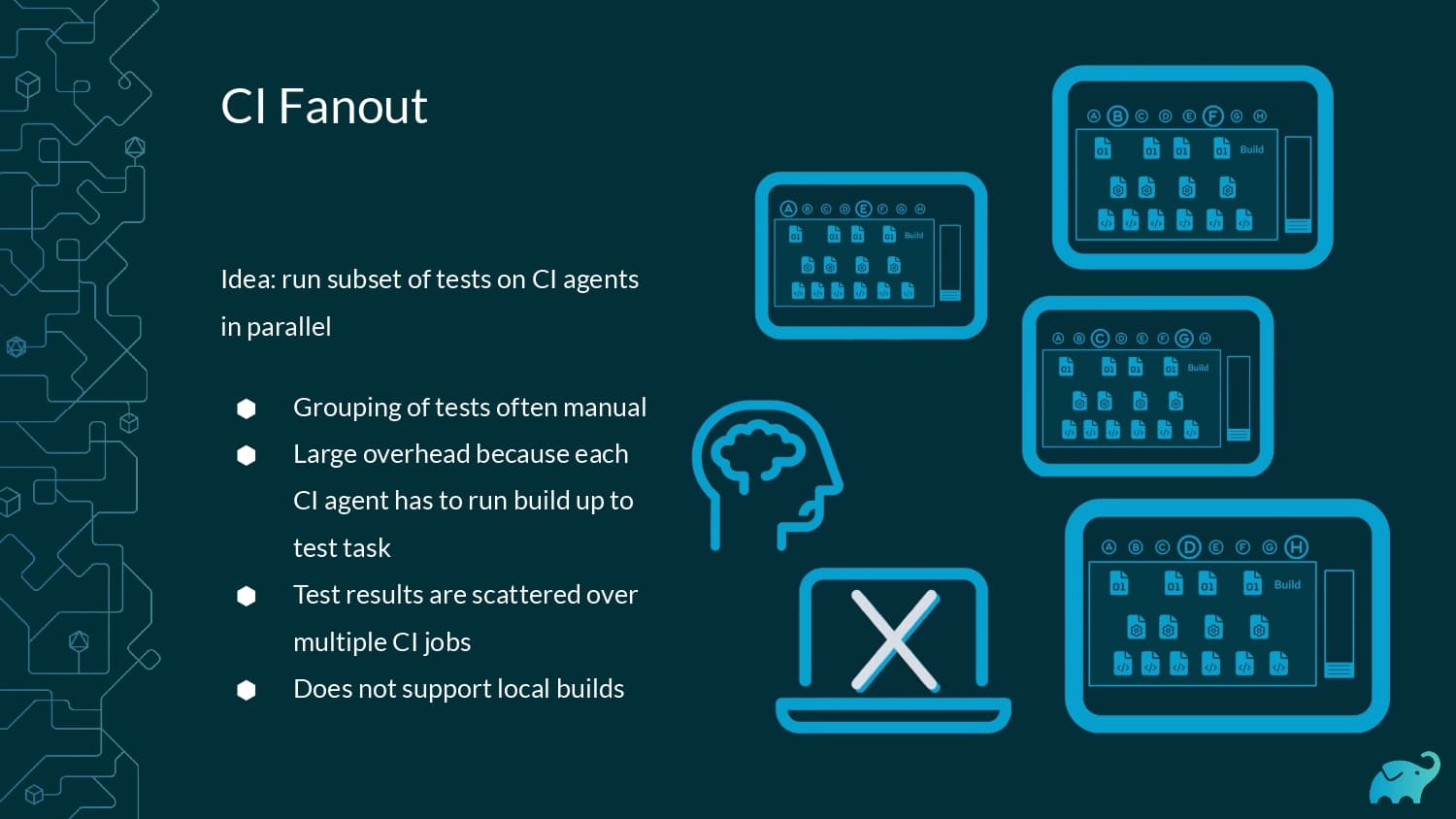
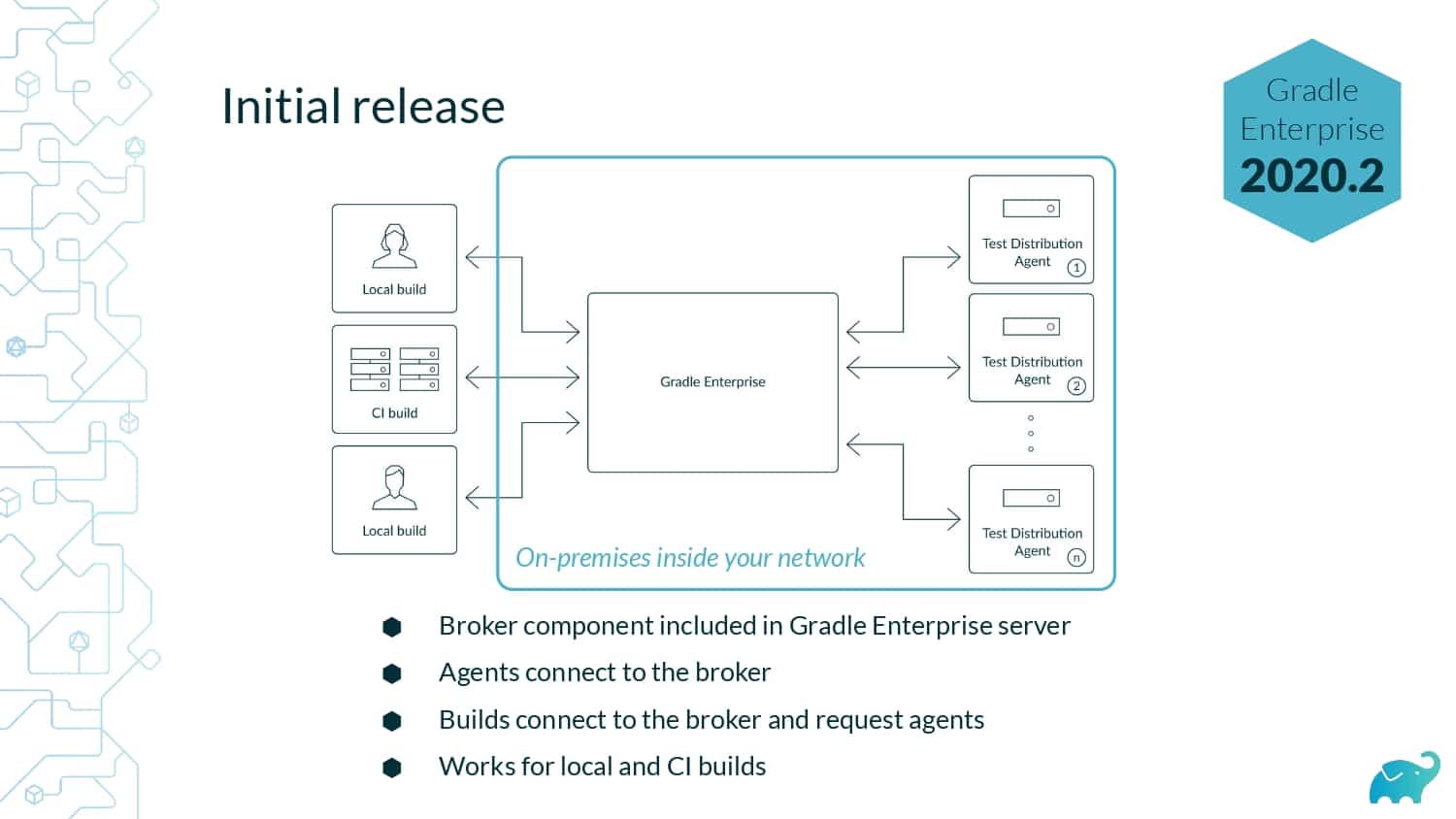
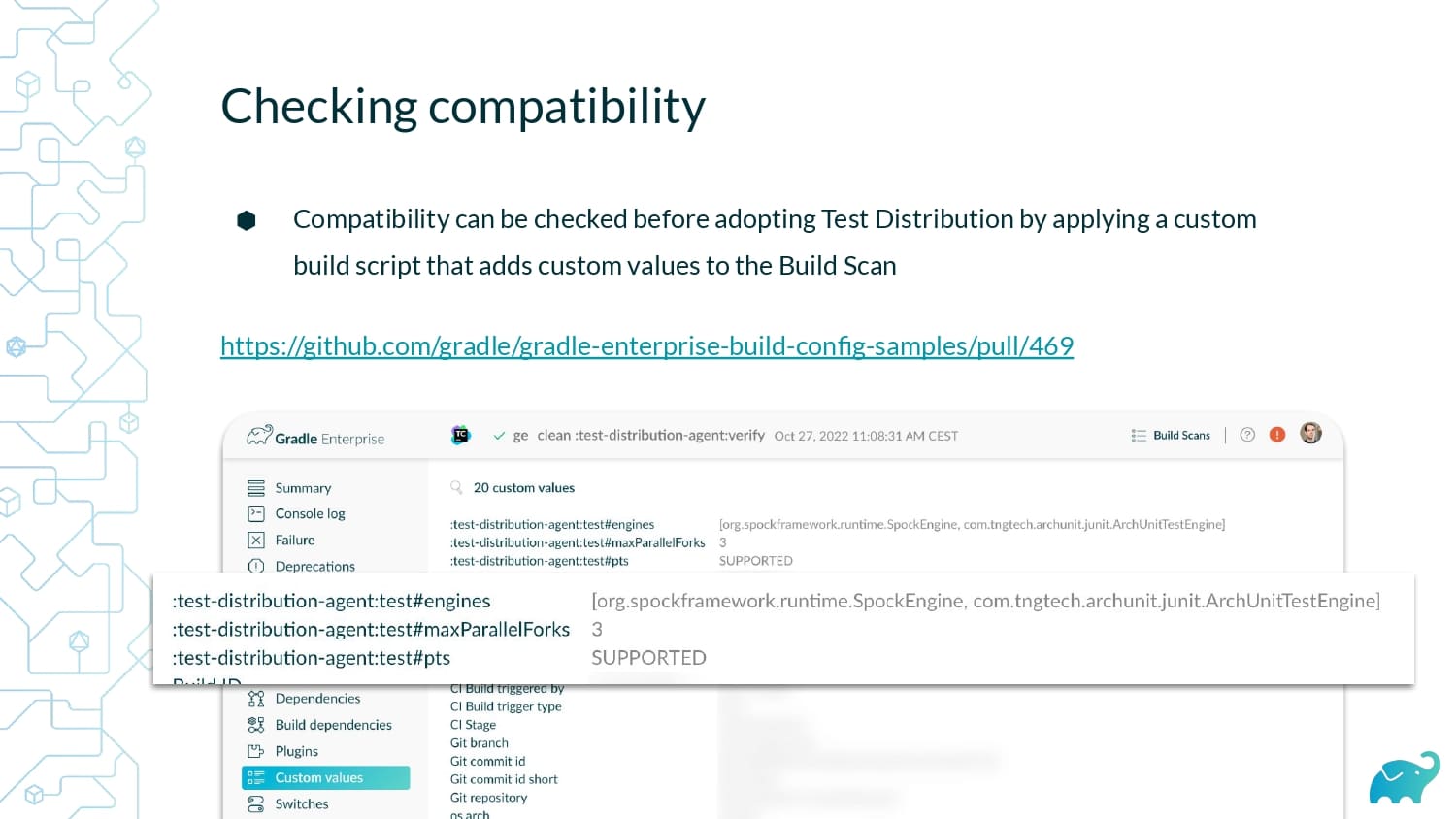
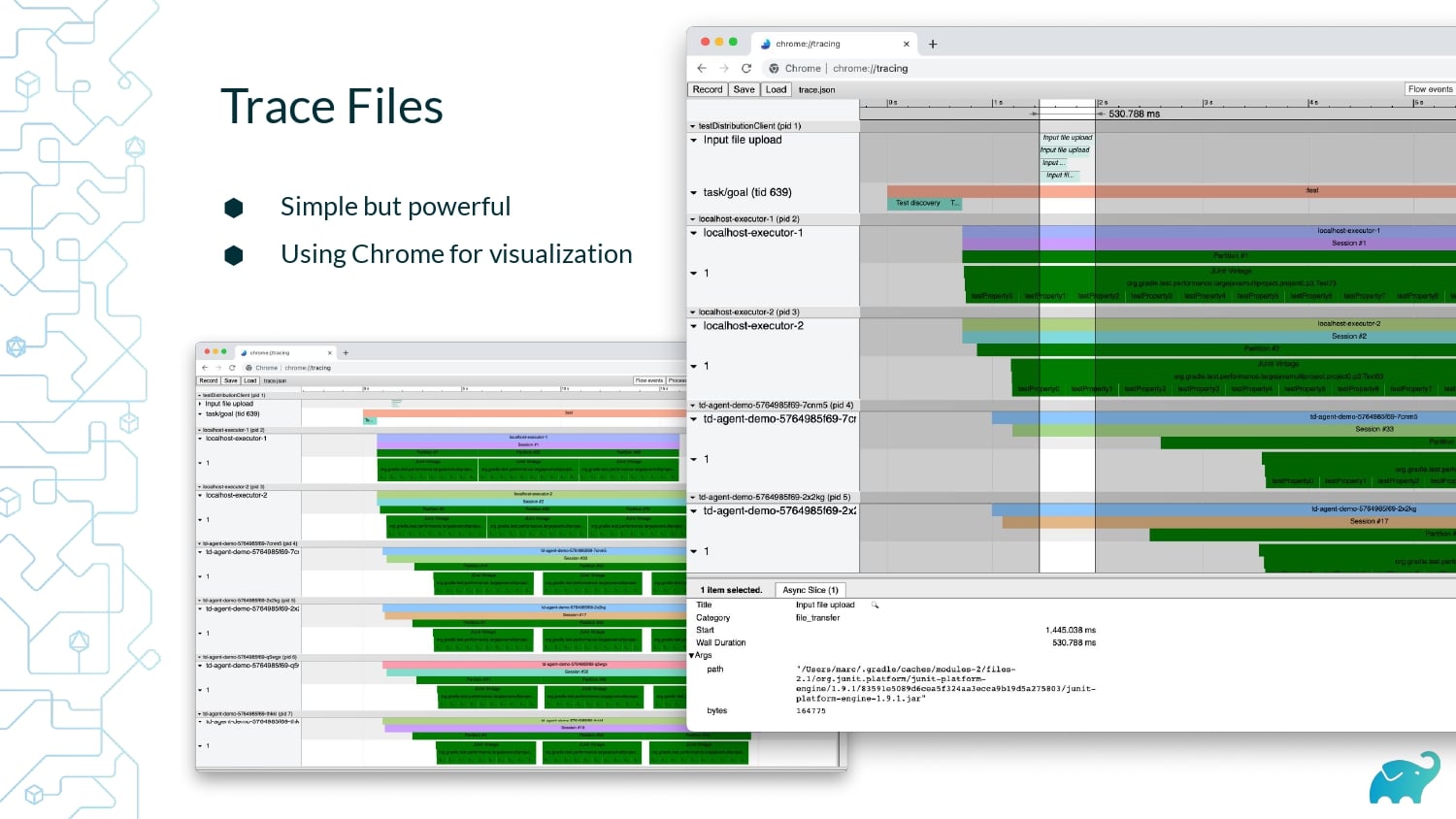
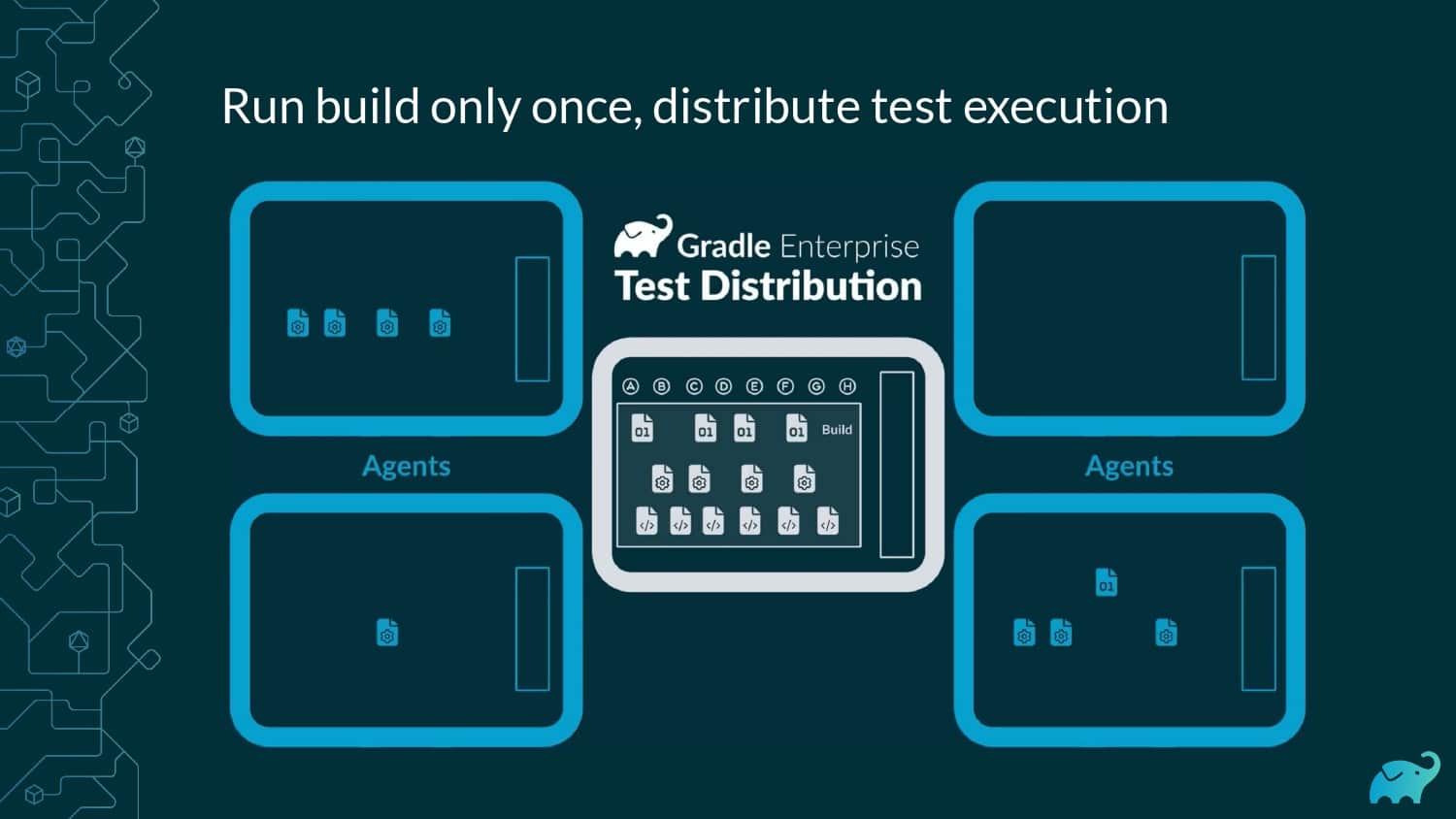
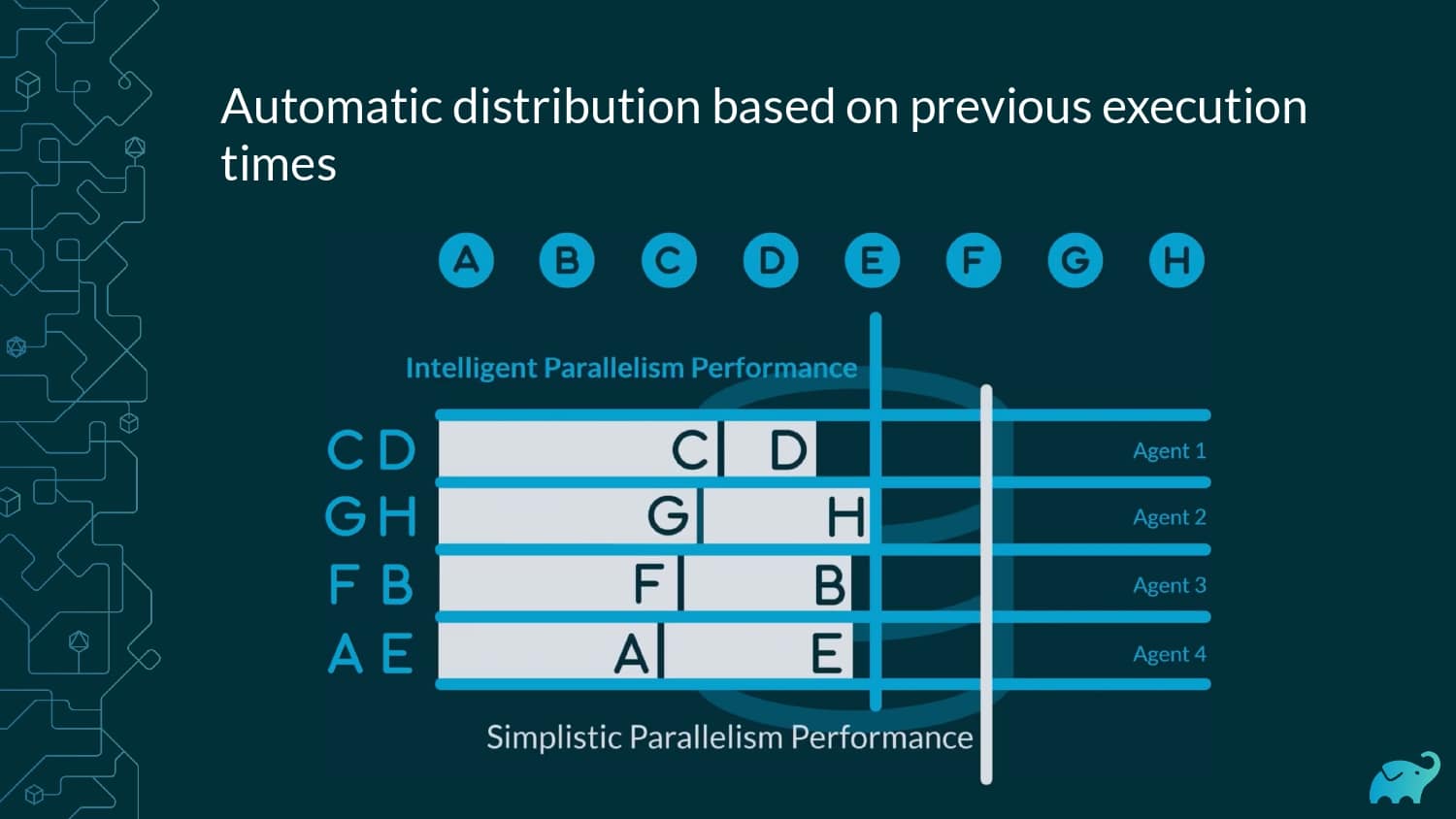
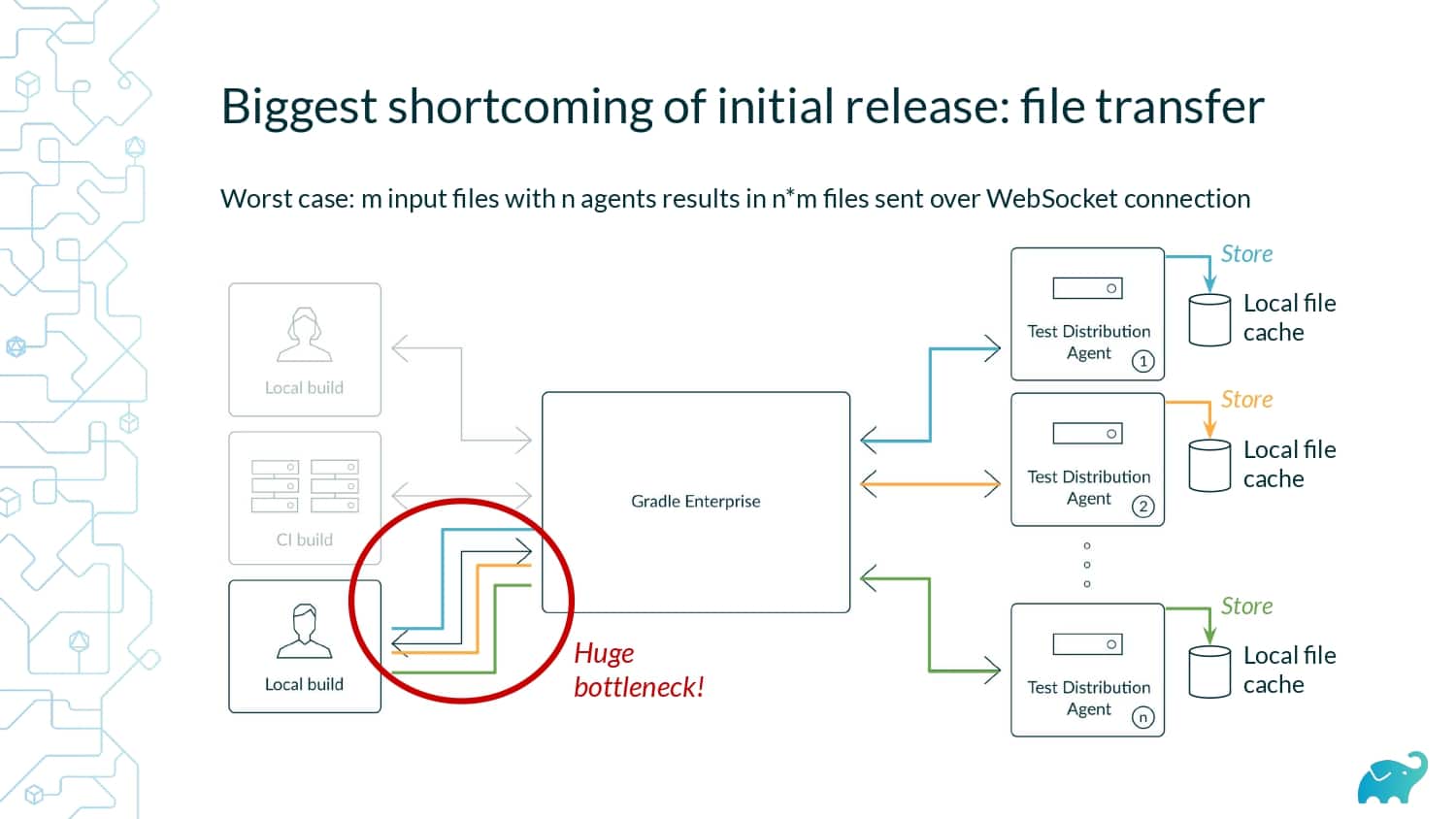
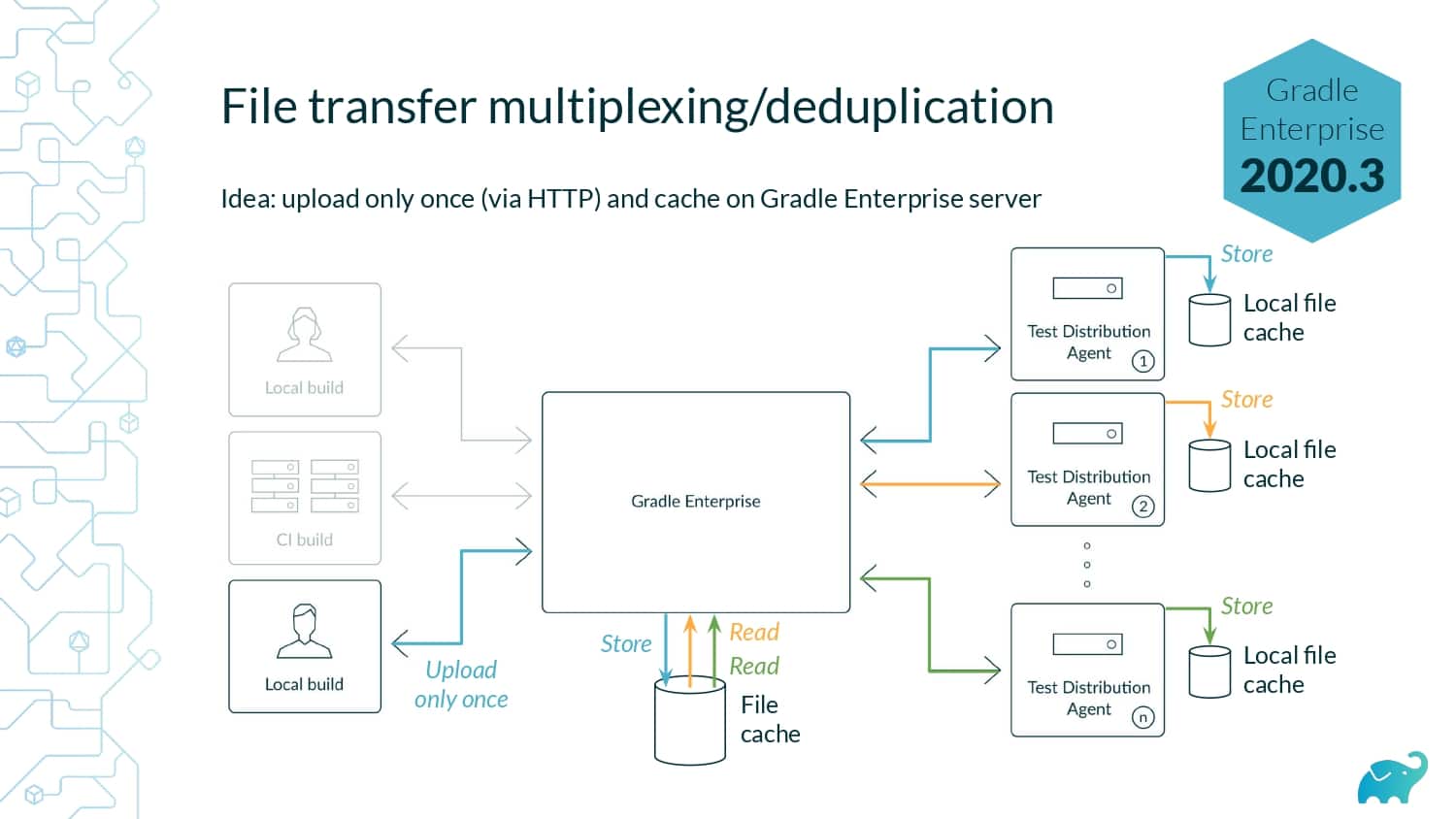
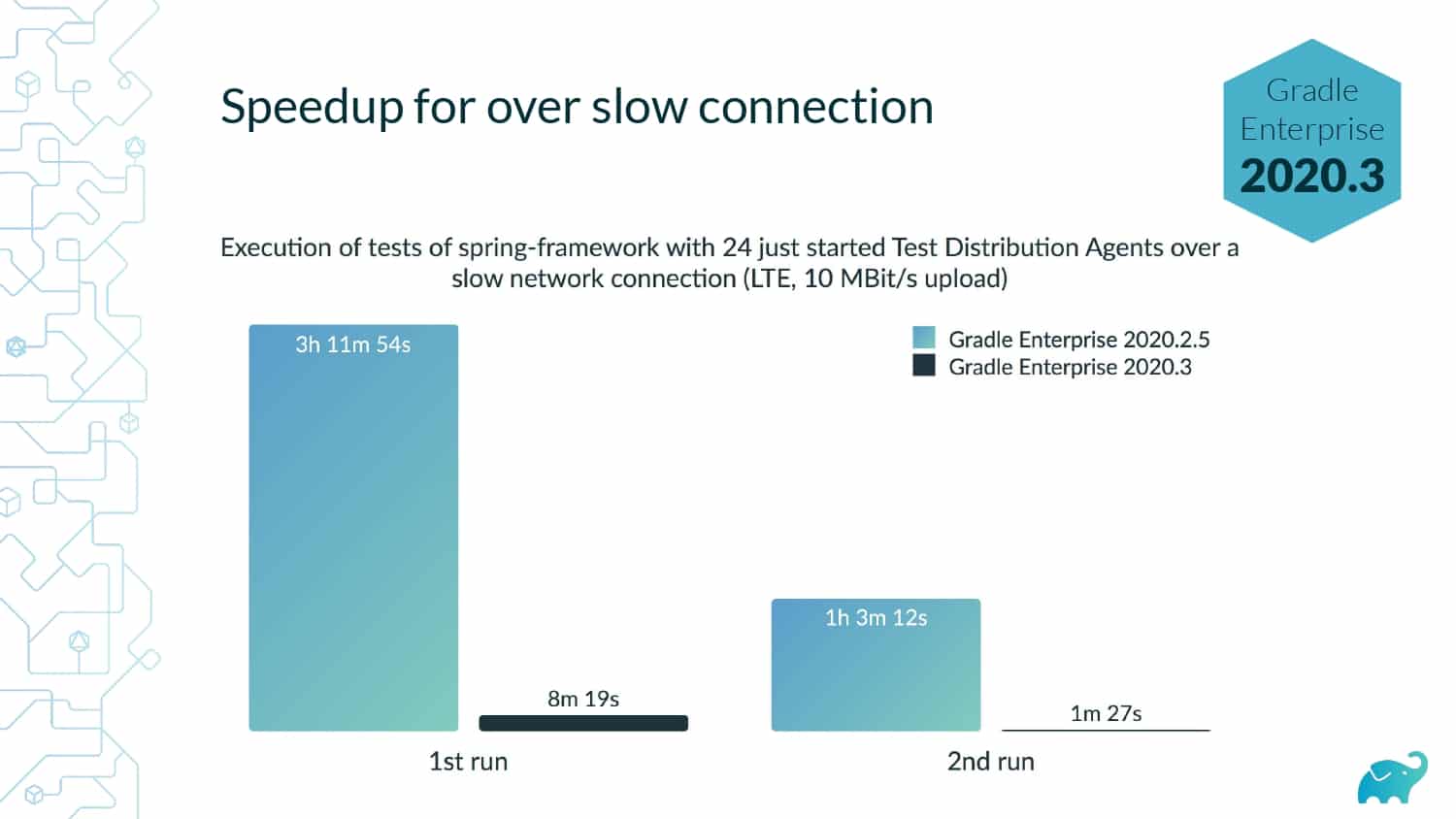
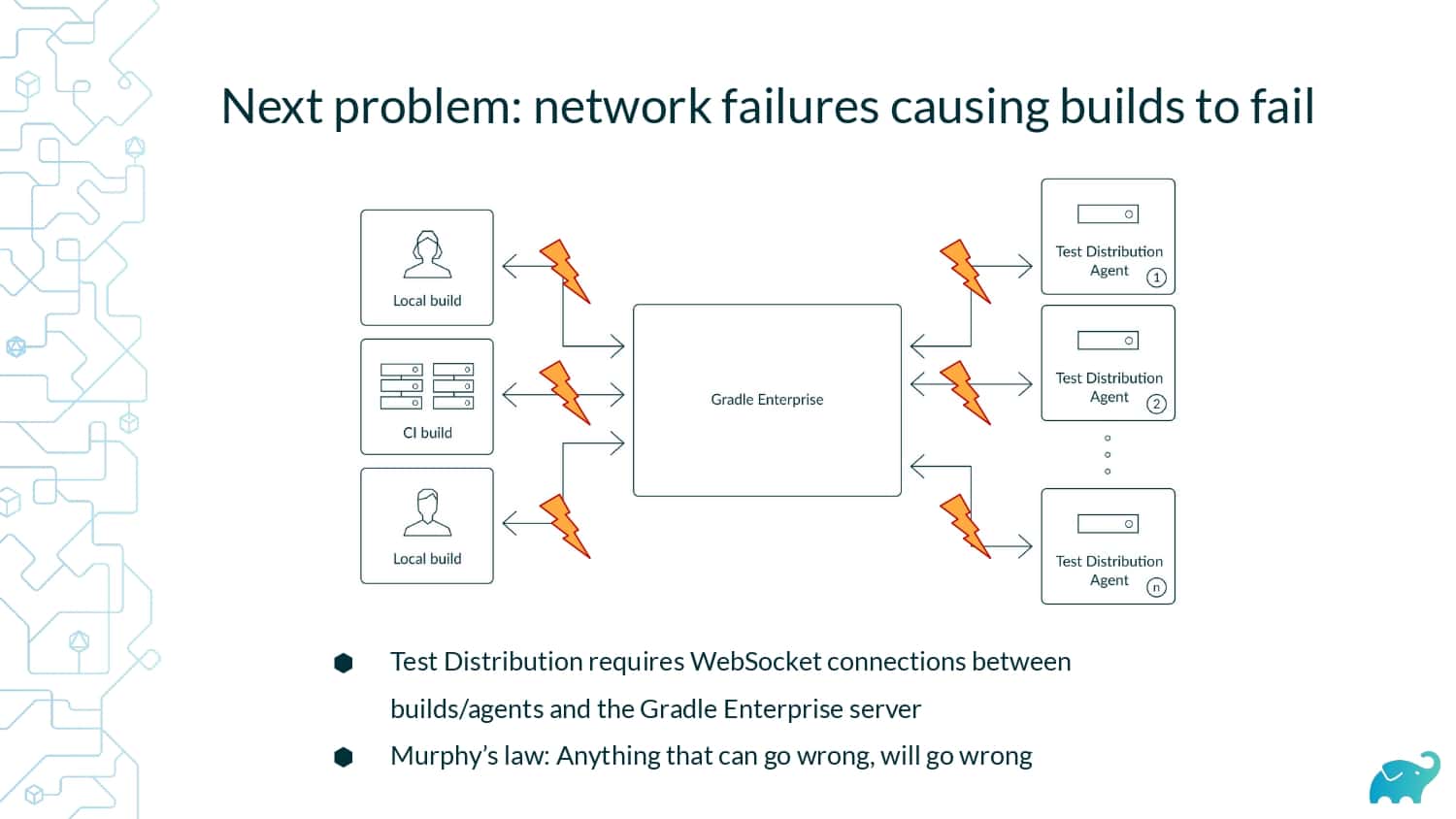
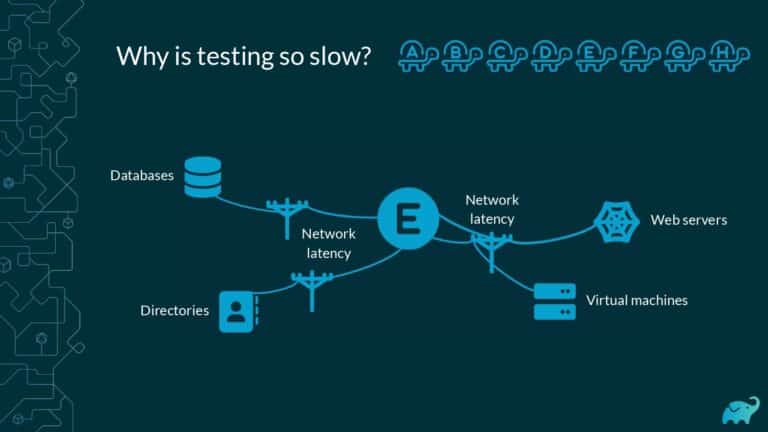
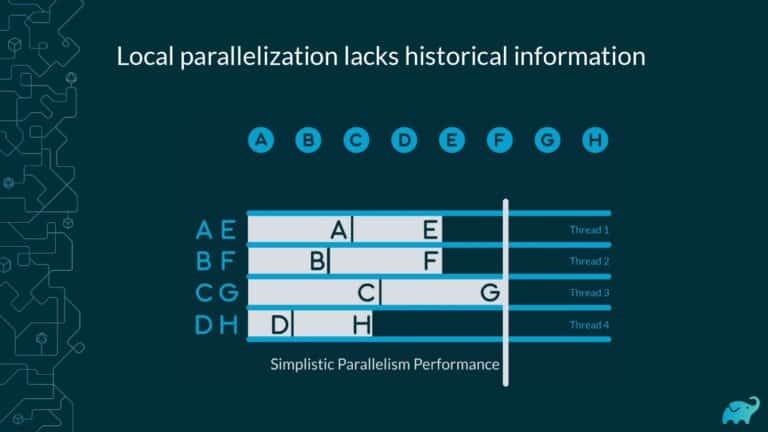
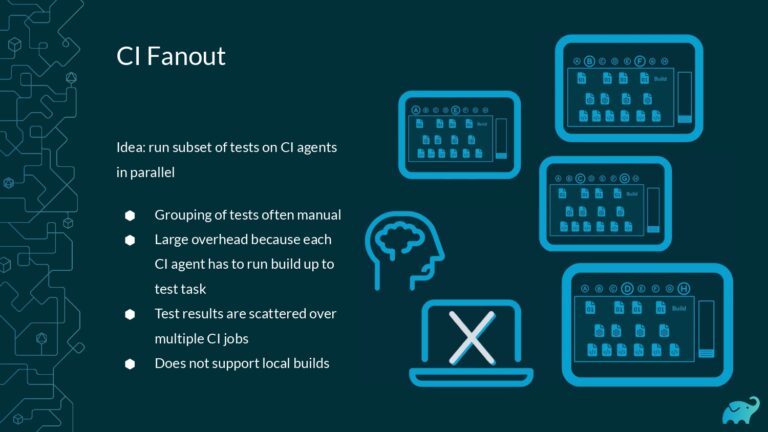
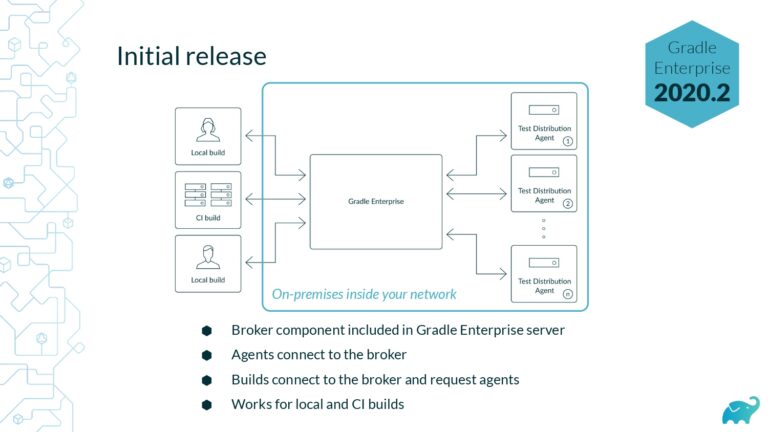
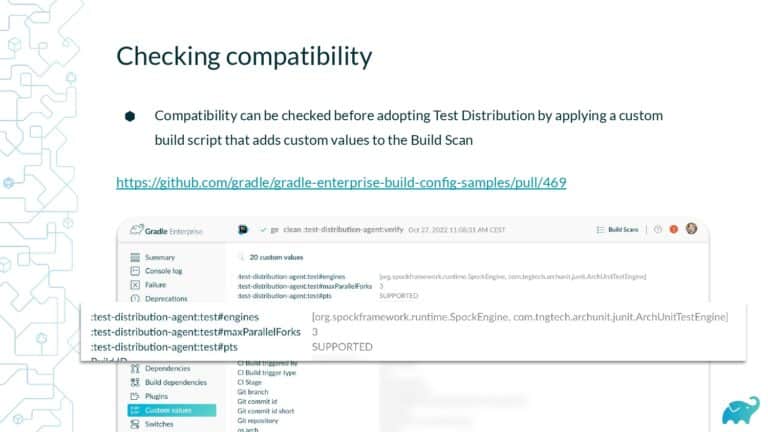
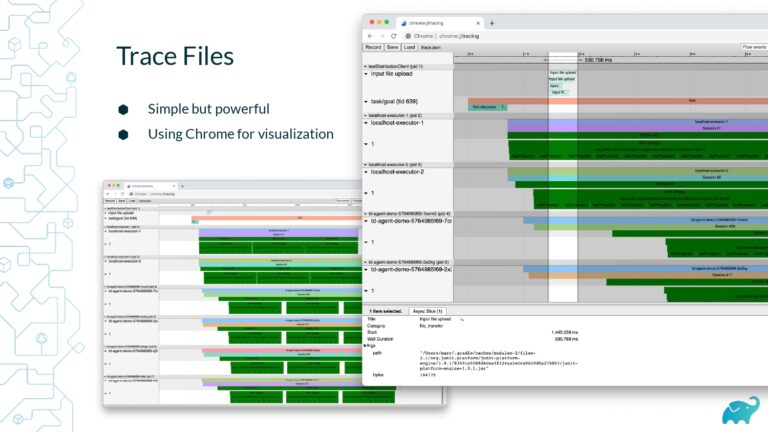
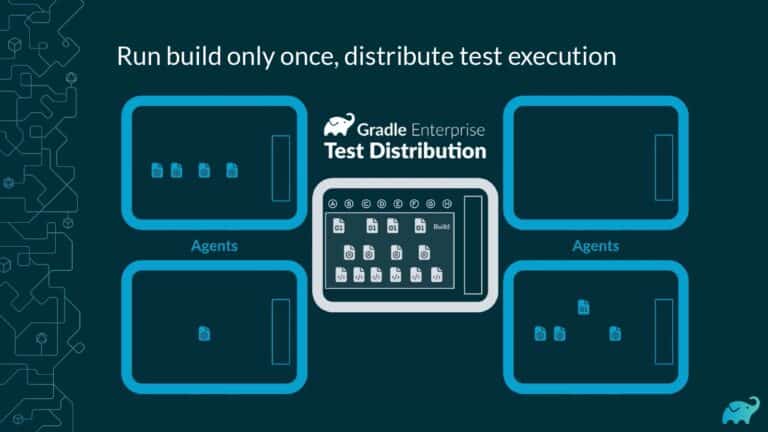
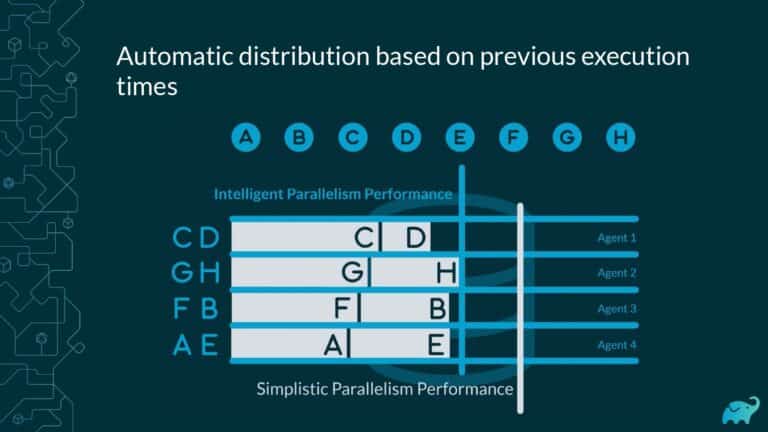
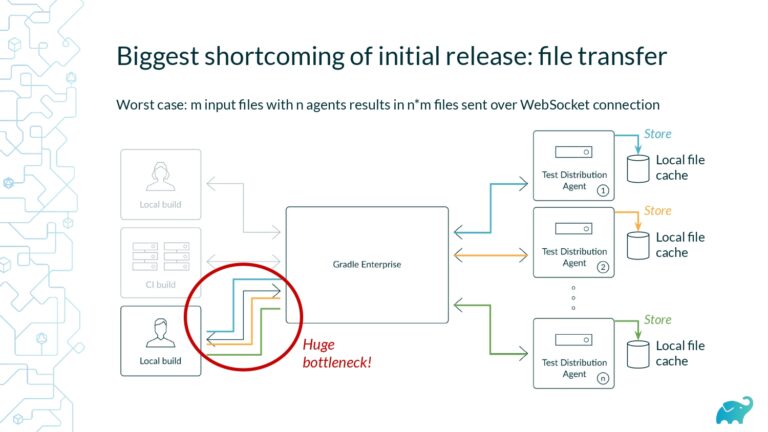
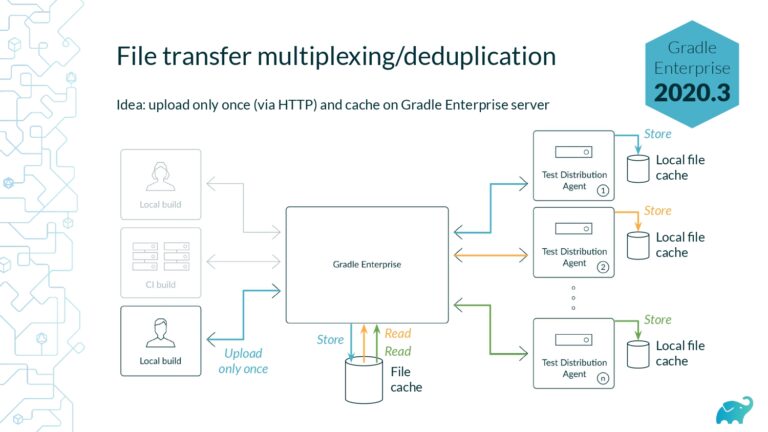
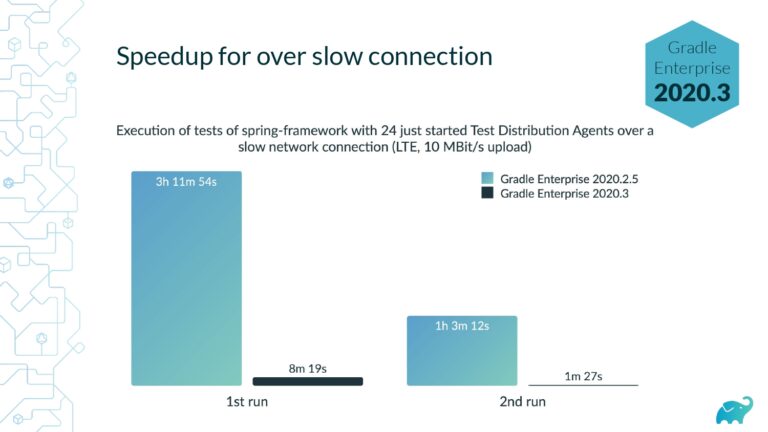
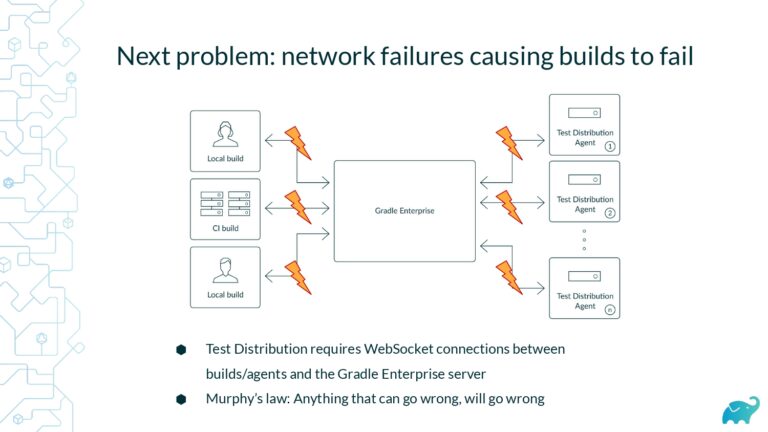
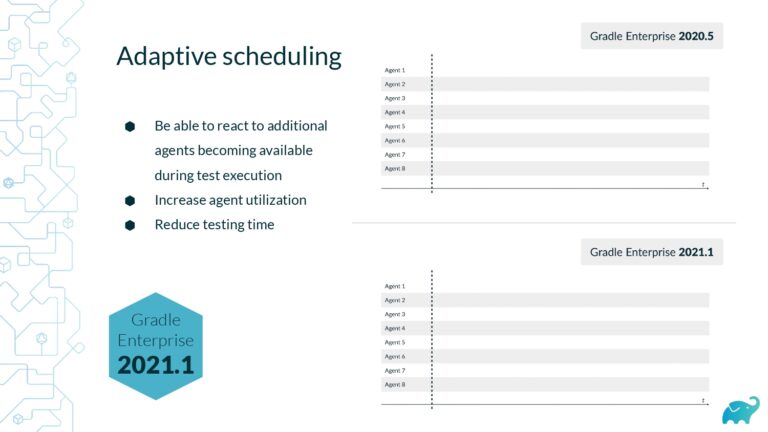
Testing is one of the main contributors to long build times, representing up to 90% of the total. Multiple factors contribute to test times. These include the number of tests, sequential versus parallel test execution, and testing dependencies on expensive external resources/services. In fact, covering this wide range of inputs with tests is one of the main reasons teams are starting to run tests only on CI, which pushes tests further “to the right” and considerably lengthens the feedback loop.
In this joint presentation by Gradle and Netflix, we take a behind-the-scenes look at the journey and many challenges of building a world-class Test Distribution solution. You’ll learn which specific issues came up when starting to distribute existing test suites and how these challenges were overcome.
“If we can deliver [Test Distribution] to more people, we are definitely going to change the lives of engineers at Netflix.”
– Roberto Perez Alcolea, Sr. Software Engineer at Netflix
Application testing is a necessary part of the SDLC, and even elite development organizations cannot avoid spending a vast majority of build time on testing alone. Speeding up the testing phase is thus a major priority for DPE practitioners, but it’s no easy feat–distributing tests precisely across parallel infrastructure requires the ability to increase file transfer efficiency, handle unstable network connections, enable intelligent scheduling and auto-scaling, and much more.
This talk explores the challenges and solutions behind making Test Distribution a real solution to be used by one of the world’s most advanced technology companies. Hear first-hand how Netflix reduced their build and test times from 62 minutes to just 5 minutes for hundreds of projects–built both locally and on CI–using Gradle Enterprise Test Distribution.
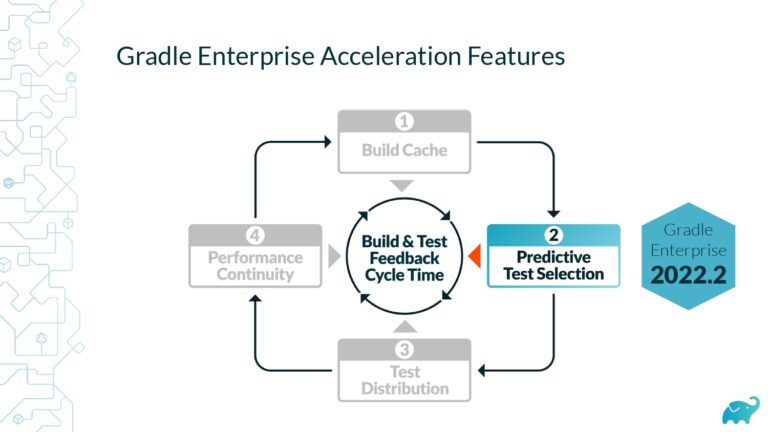
Marc Philipp is a software engineer with extensive experience in developing business and consumer applications, as well as training and coaching other developers. At Gradle Inc. he’s working on innovative products like Test Distribution and Predictive Test Selection in order to improve developer productivity. He is a long-time core committer and maintainer of JUnit and initiator of the JUnit Lambda crowdfunding campaign that started what has become JUnit 5.
Roberto Perez Alcolea is an experienced software engineer focused on microservices, cloud, developer productivity and continuous delivery. He’s a self-motivated, success-driven, and detail-oriented professional interested in solving unique and challenging problems.

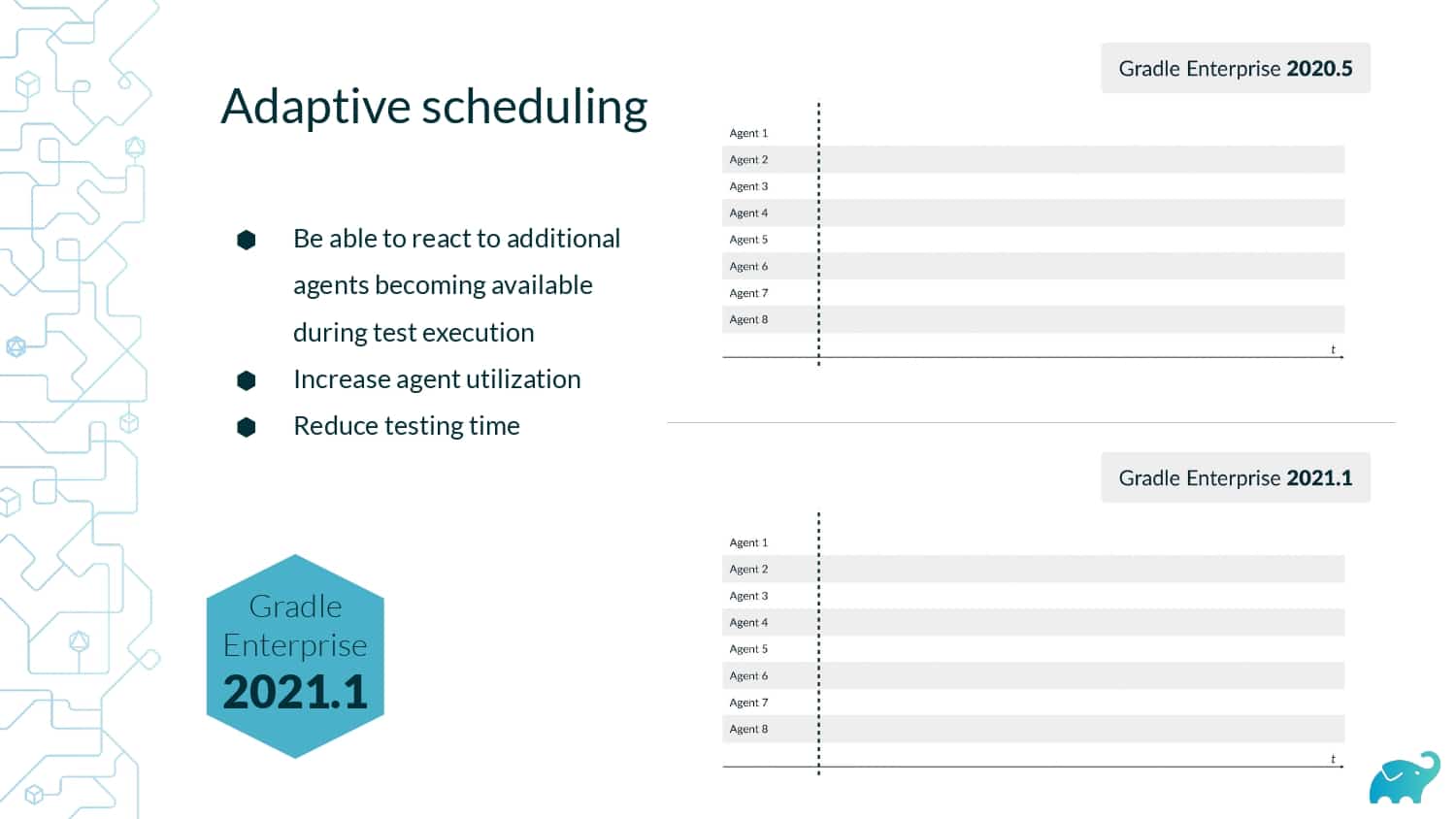
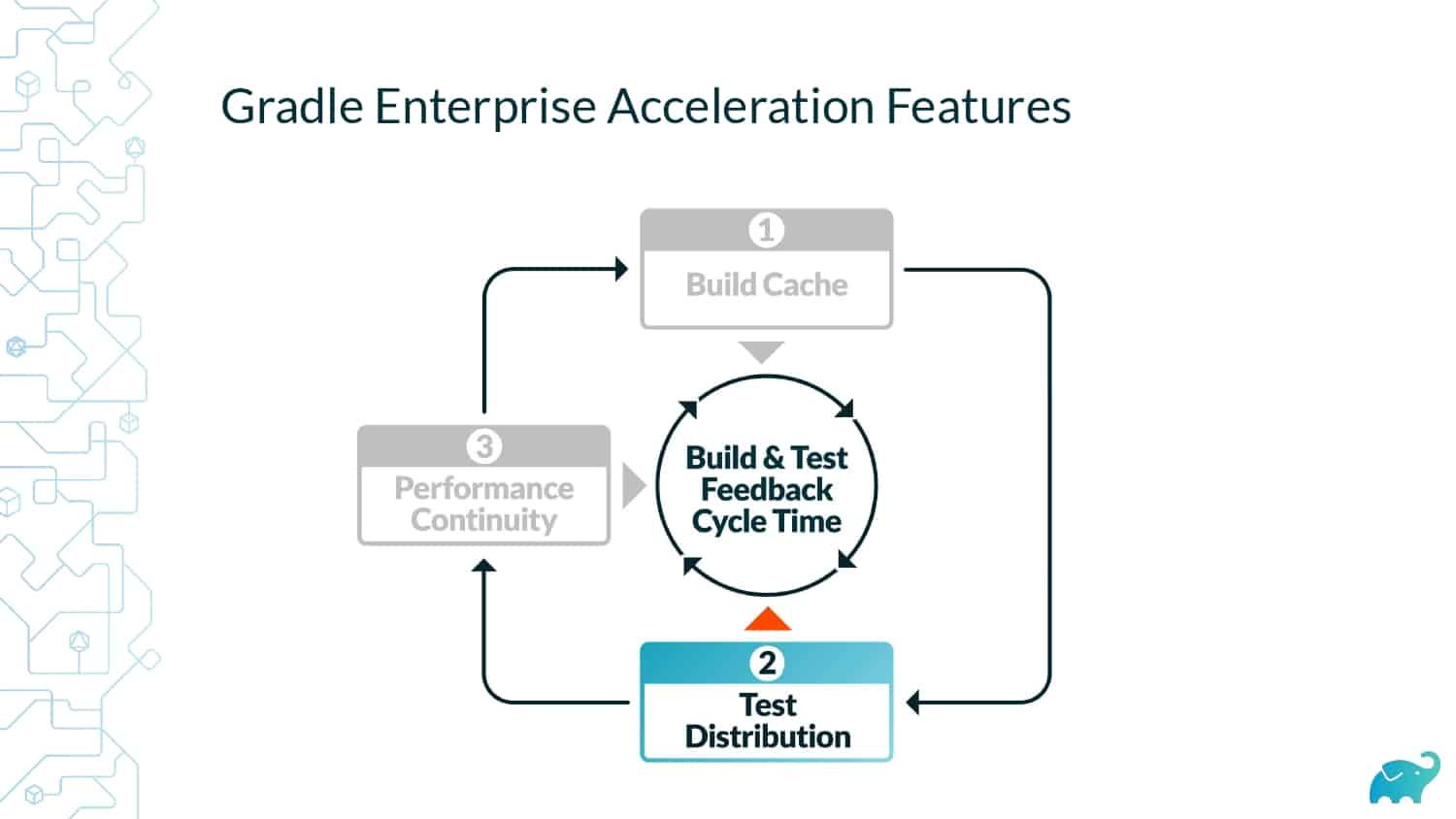
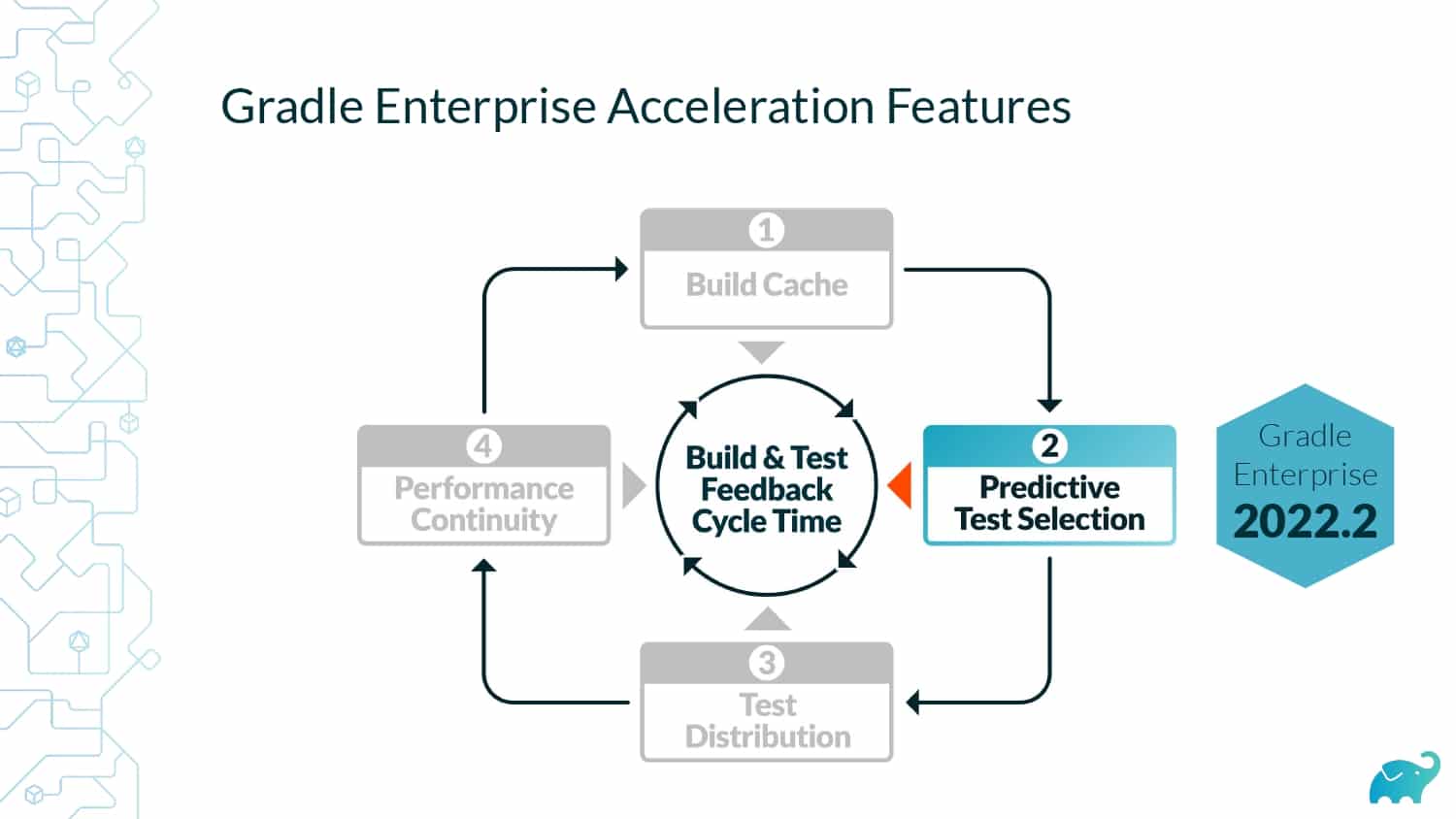
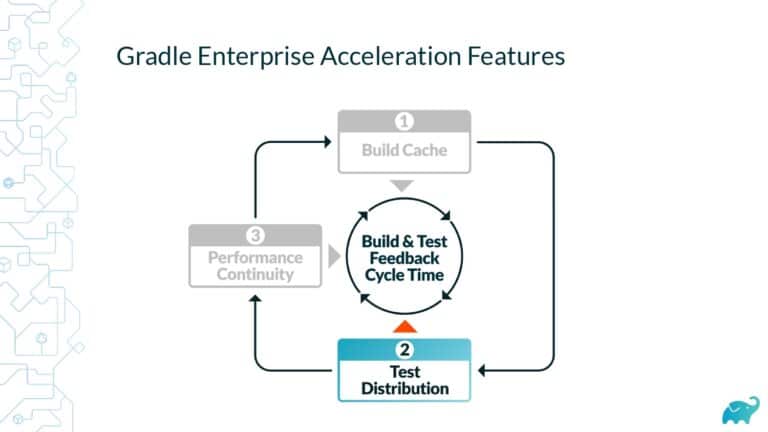
Gradle Enterprise customers use Test Distribution to reduce test times by parallelizing tests across all available infrastructure. They often combine this with Predictive Test Selection–a feature which saves significant time by using machine learning to predict and run only tests that are likely to provide useful feedback—for a force multiplier effect that accelerates the build and test process by 50-90%. Learn about these features by beginning with a free Build Scan™ for your Maven and Gradle Build Tool projects, and watching the short, informative videos.