What’s inside?
Valera Zakharov talks about how addressing tech debt to maintain a healthy codebase enables their software engineers to ship software faster to customers. Learn how to accumulate code analysis data from sources like static code analysis, style checks, and linting into a single, usable metric.
Valera Zakharov talks about how addressing tech debt to maintain a healthy codebase enables their software engineers to ship software faster to customers. Learn how to accumulate code analysis data from sources like static code analysis, style checks, and linting into a single, usable metric.
Summit Producer’s Highlight
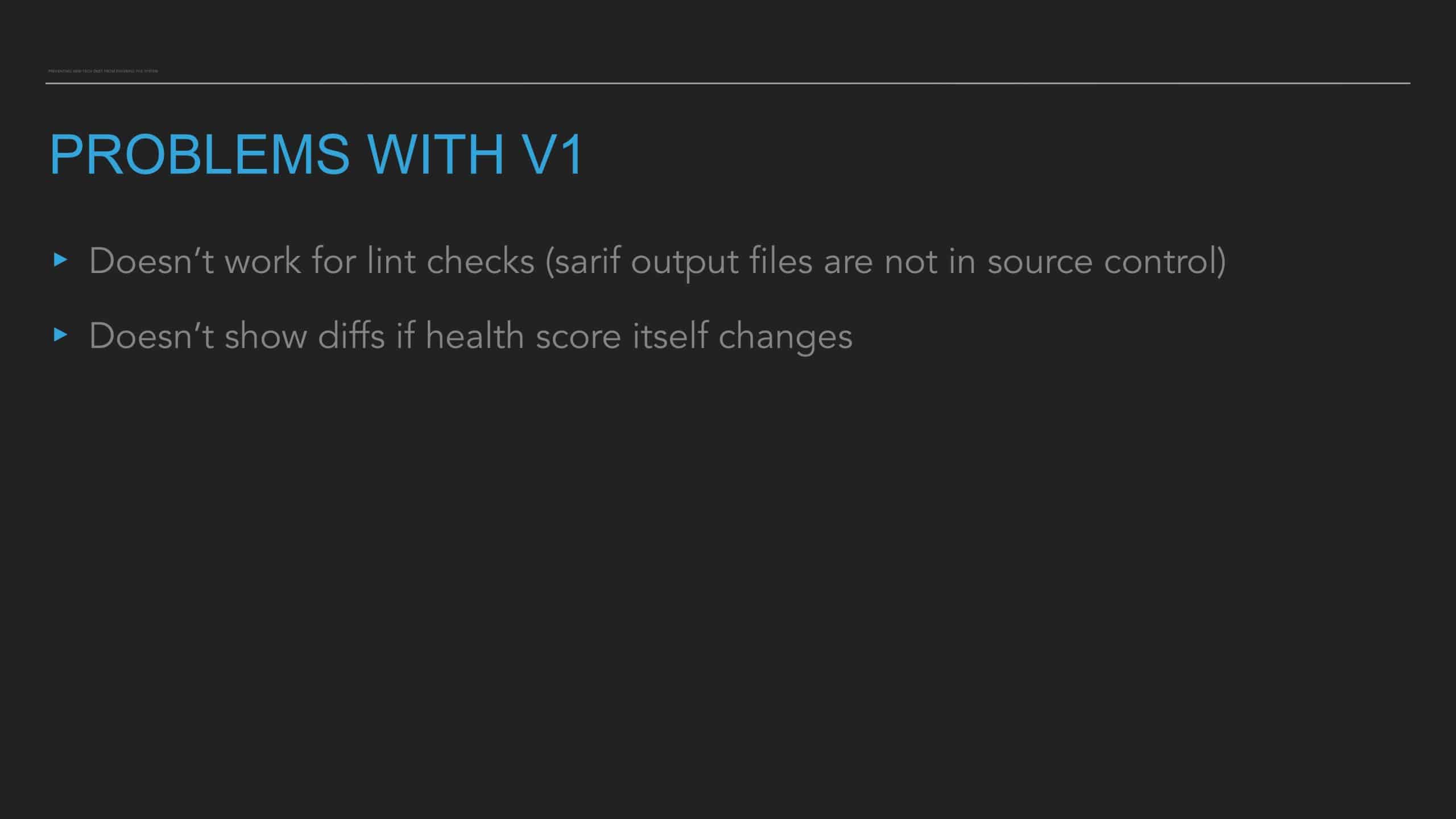
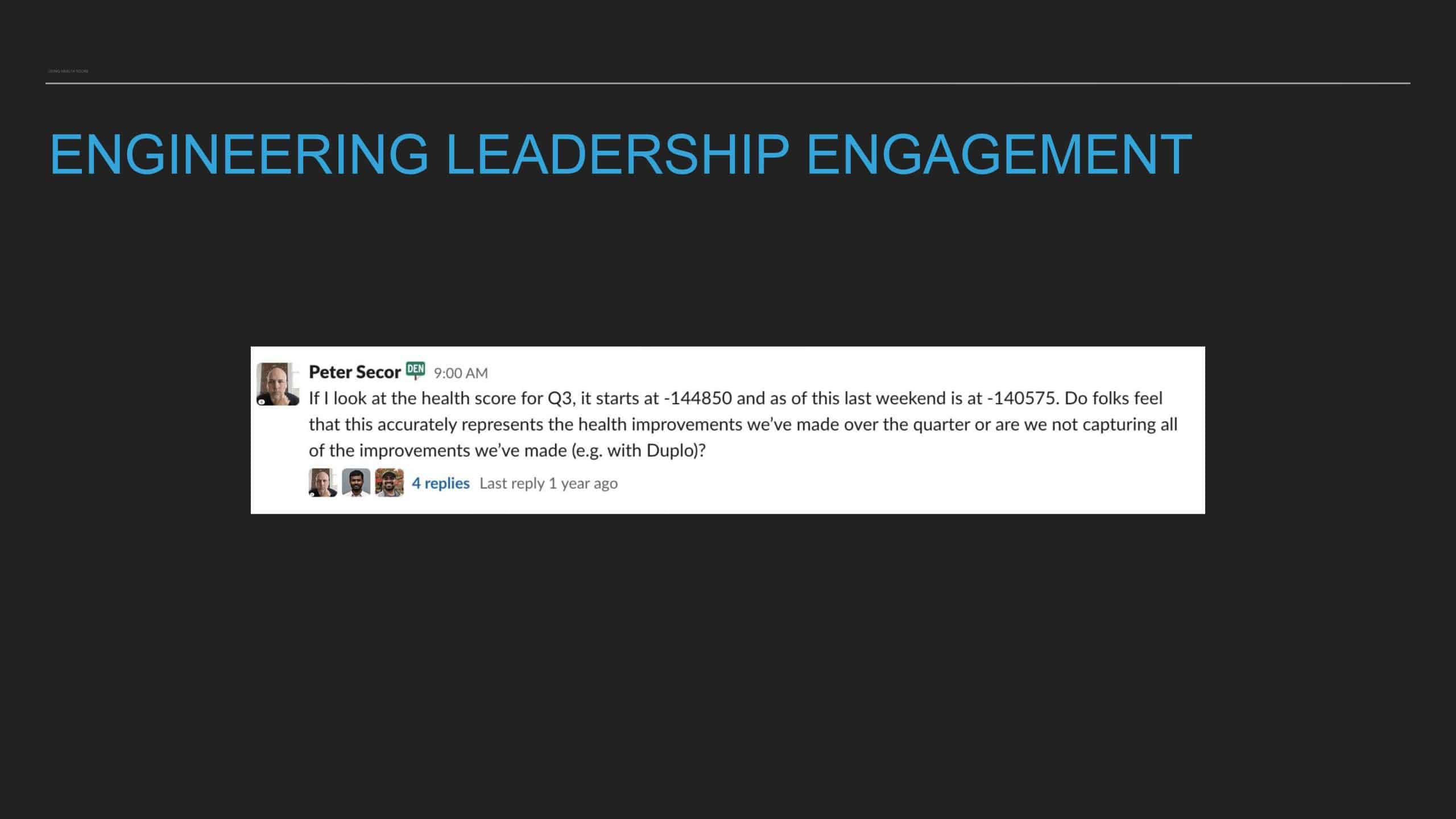
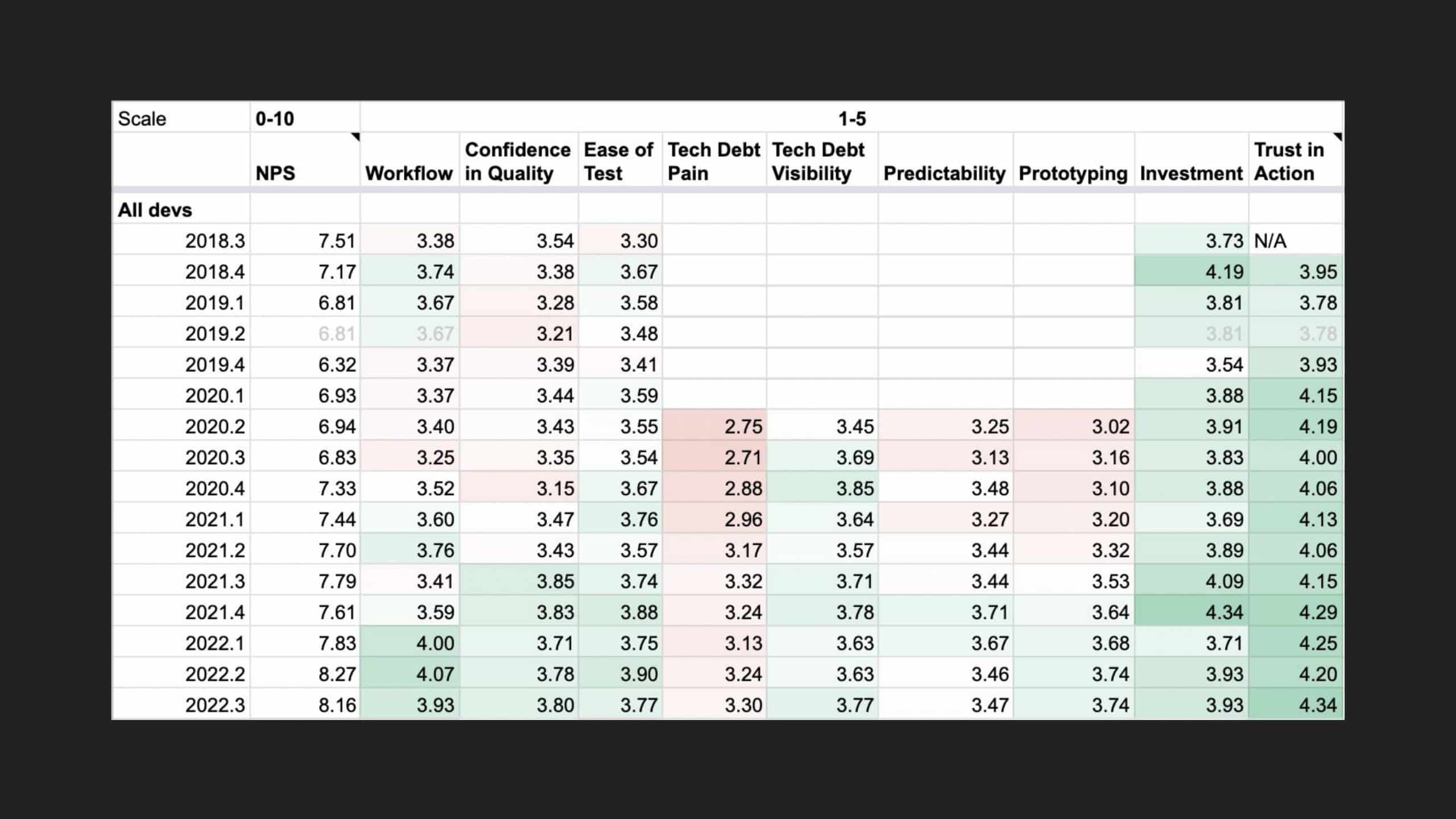
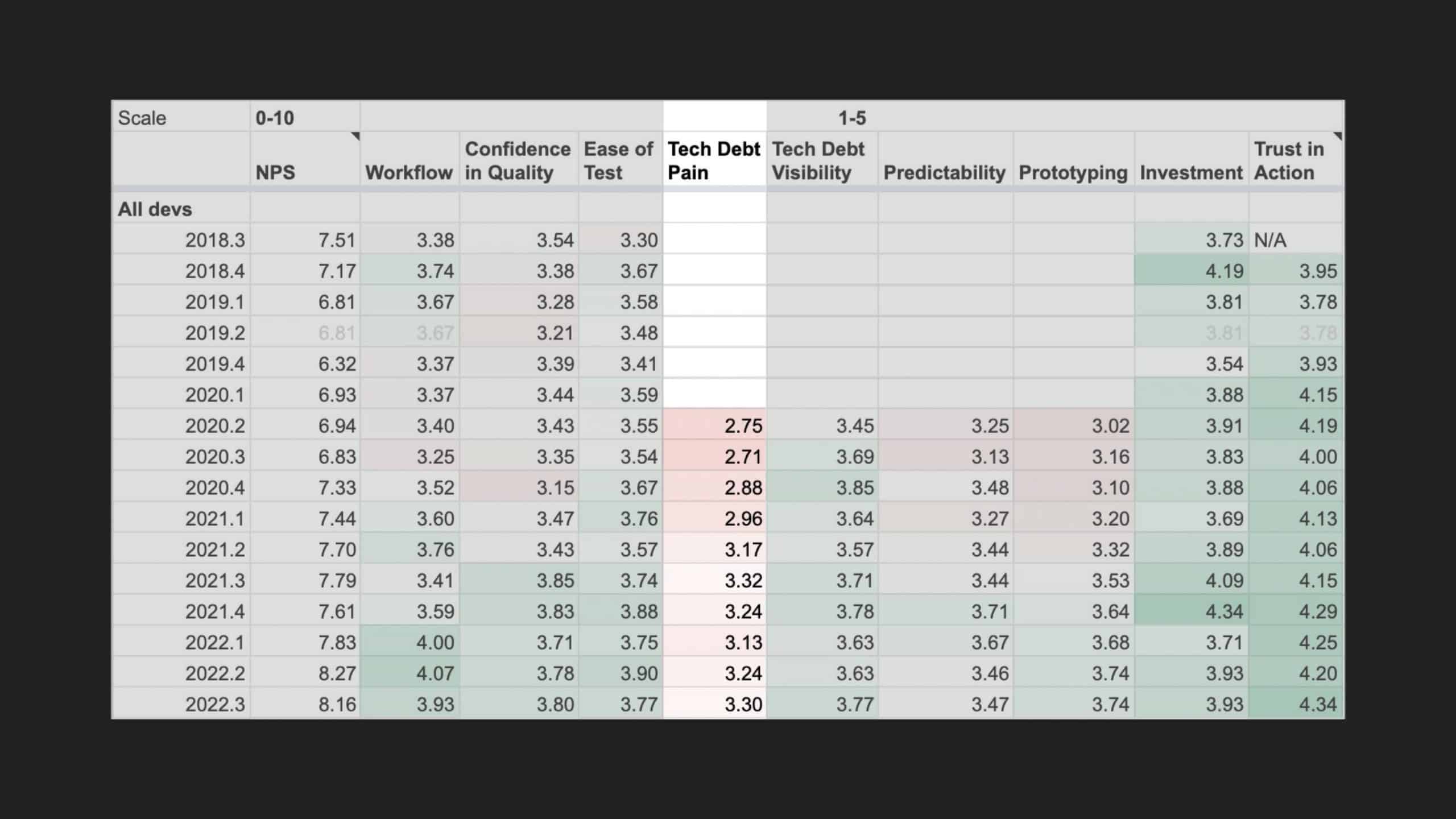
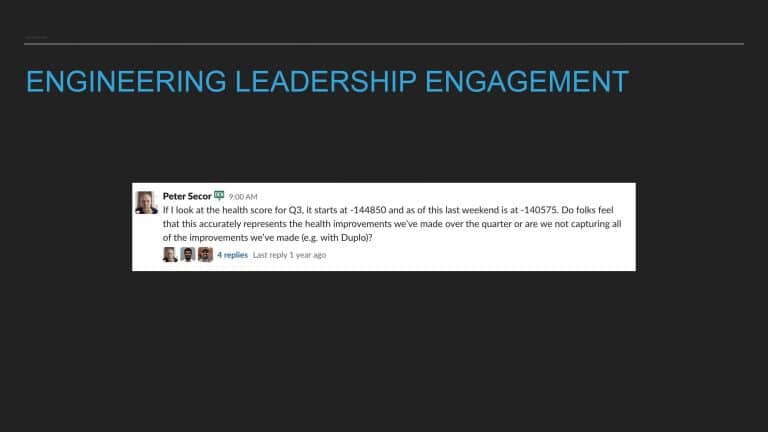
All codebases have technical debt. Sometimes developers plan to clean it up later. Other times they act on the urge to go on a refactoring binge. Addressing technical debt can be rewarding and useful. But how can we make sure that it is not simply left to the whim of a good samaritan? And can such work be consistently seen and encouraged by engineering leadership?
All codebases have technical debt. Sometimes developers plan to clean it up later. Other times they act on the urge to go on a refactoring binge. Addressing technical debt can be rewarding and useful. But how can we make sure that it is not simply left to the whim of a good samaritan? And can such work be consistently seen and encouraged by engineering leadership?
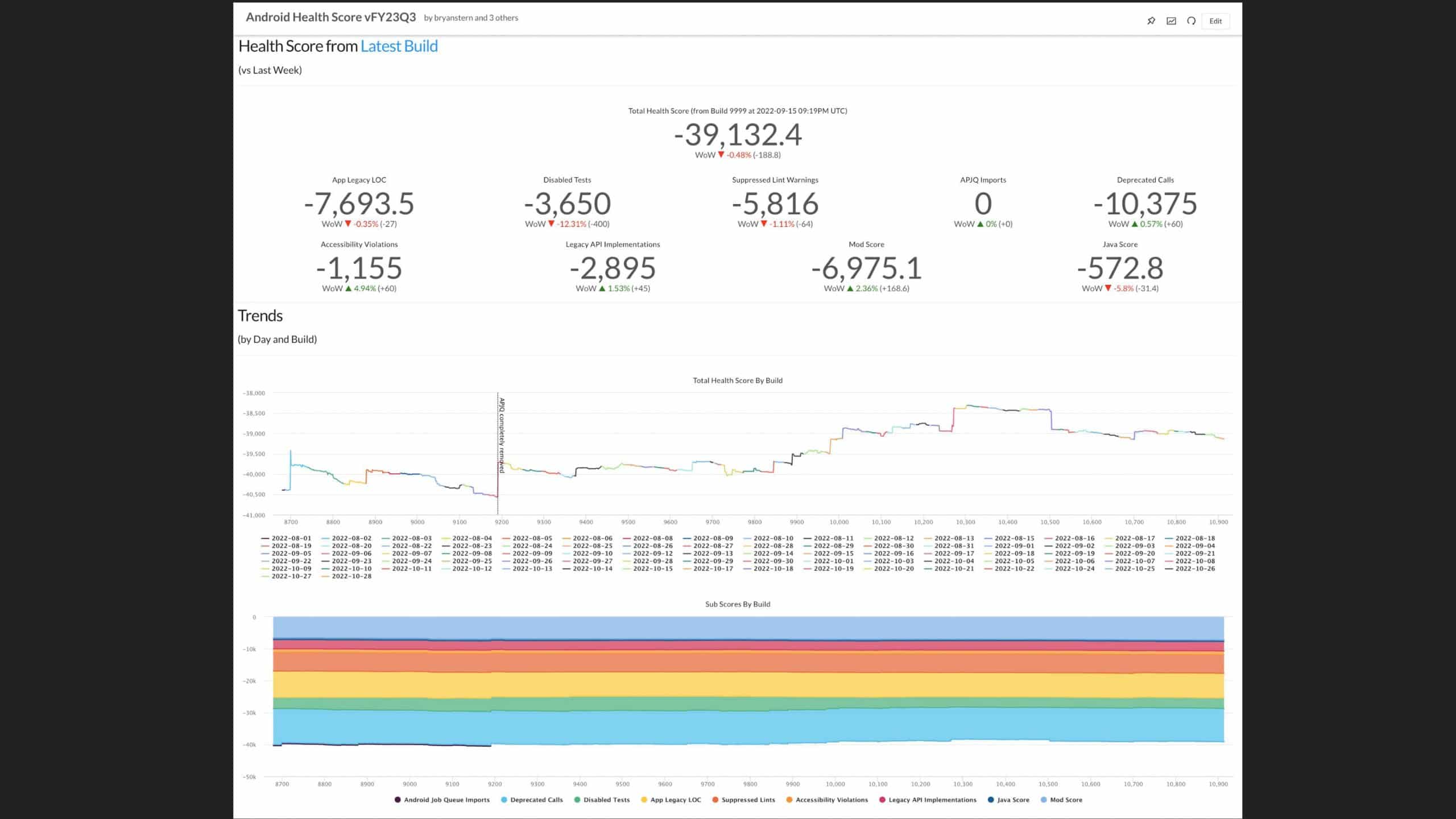
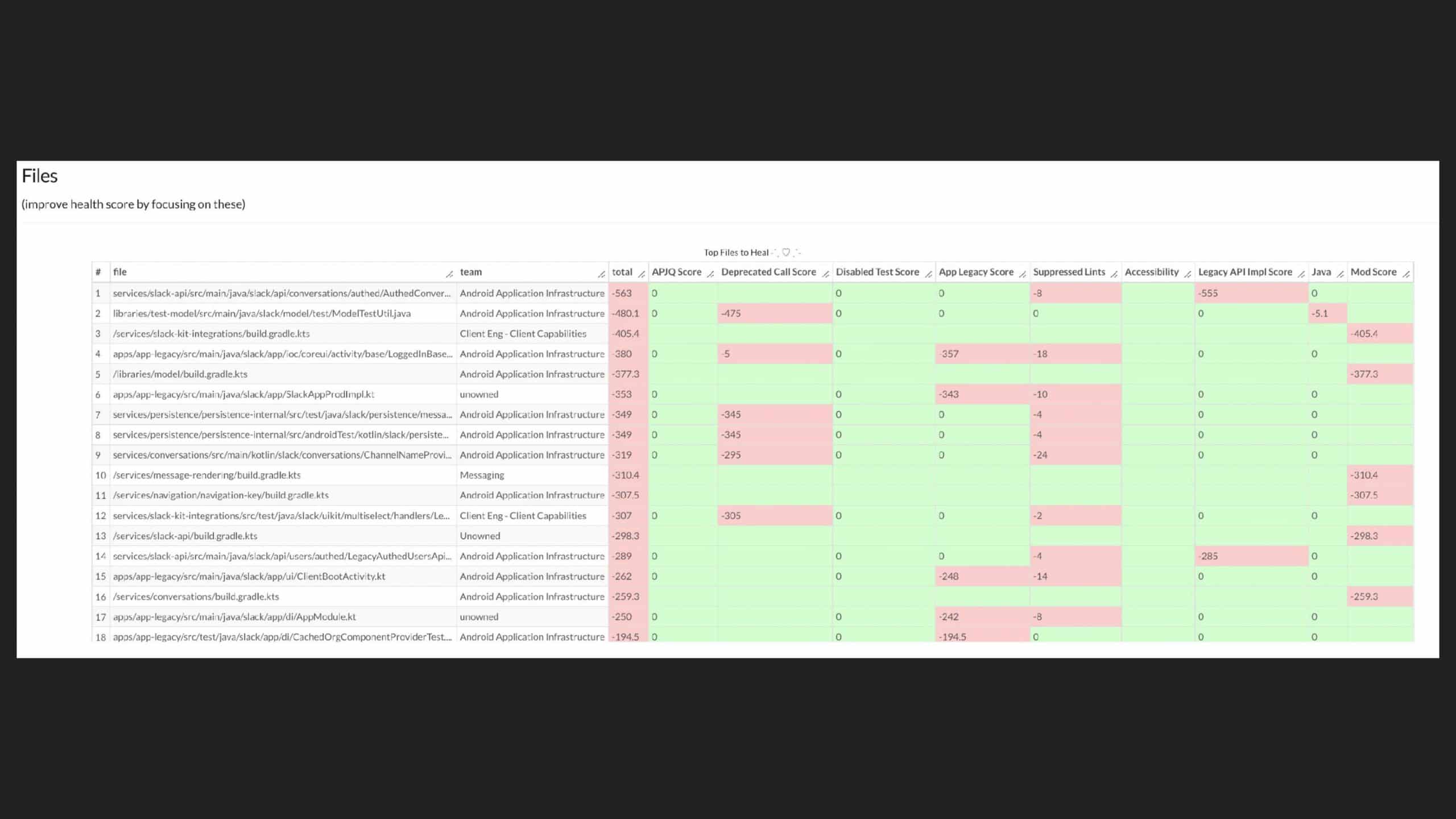
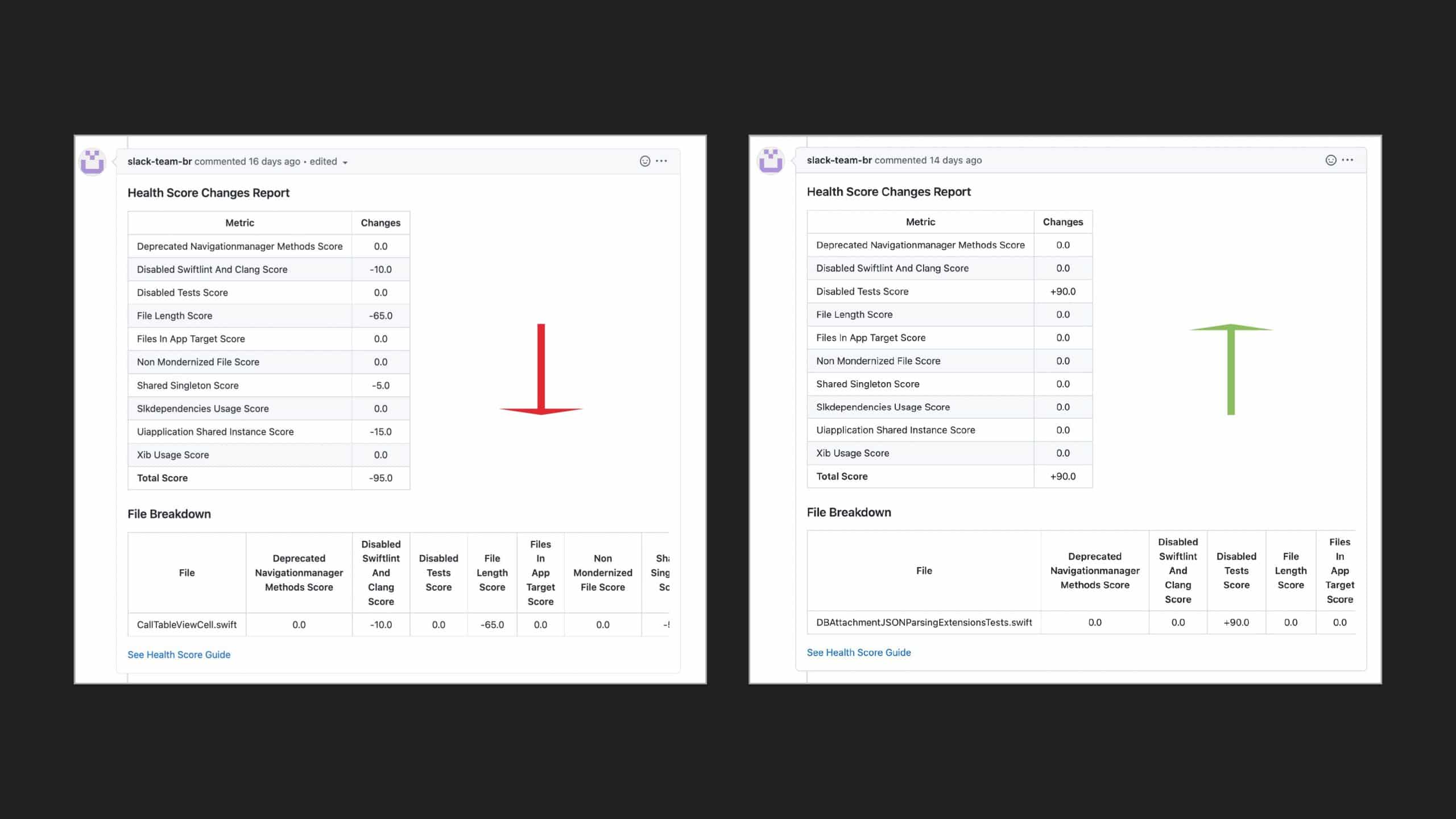
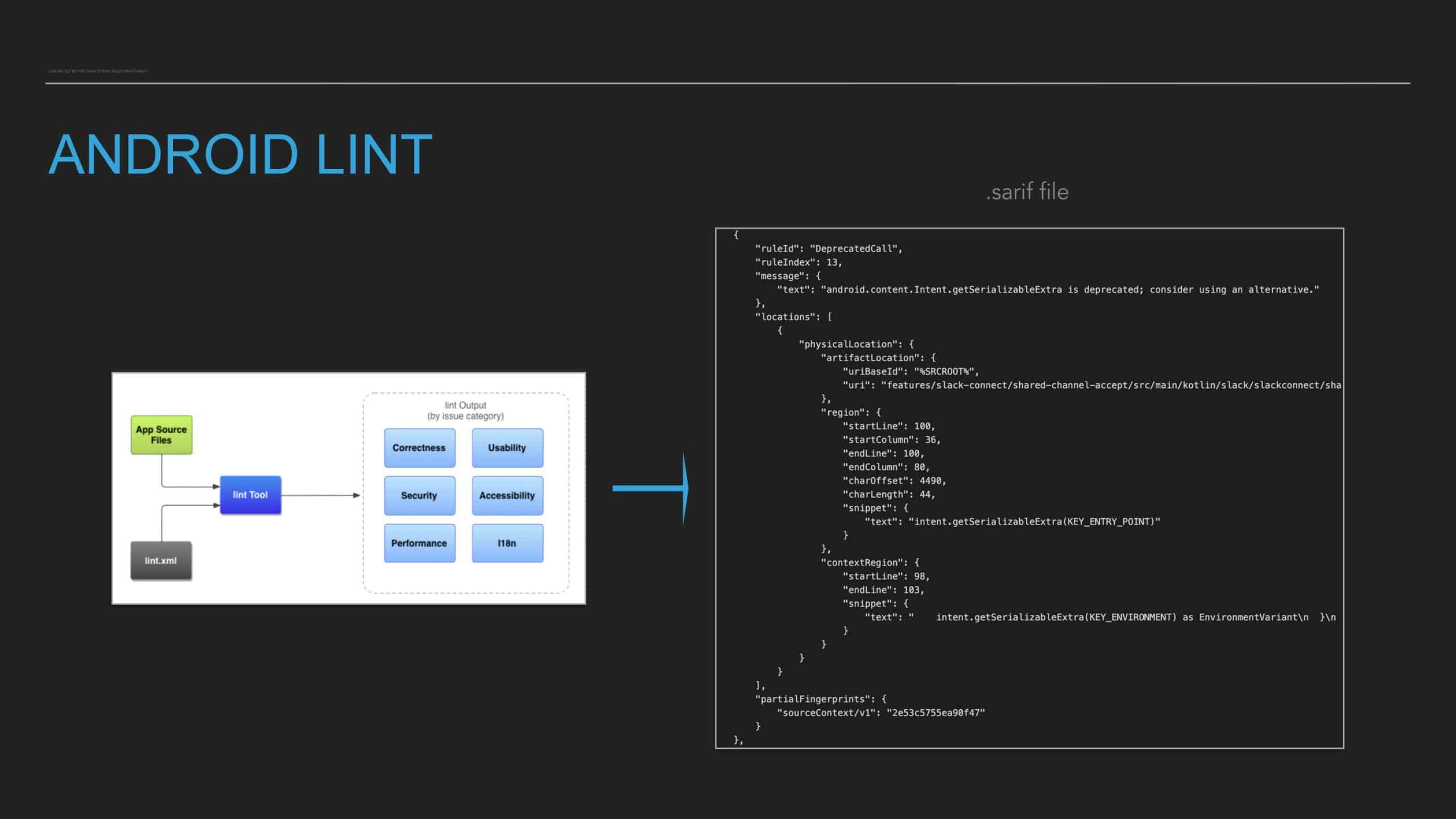
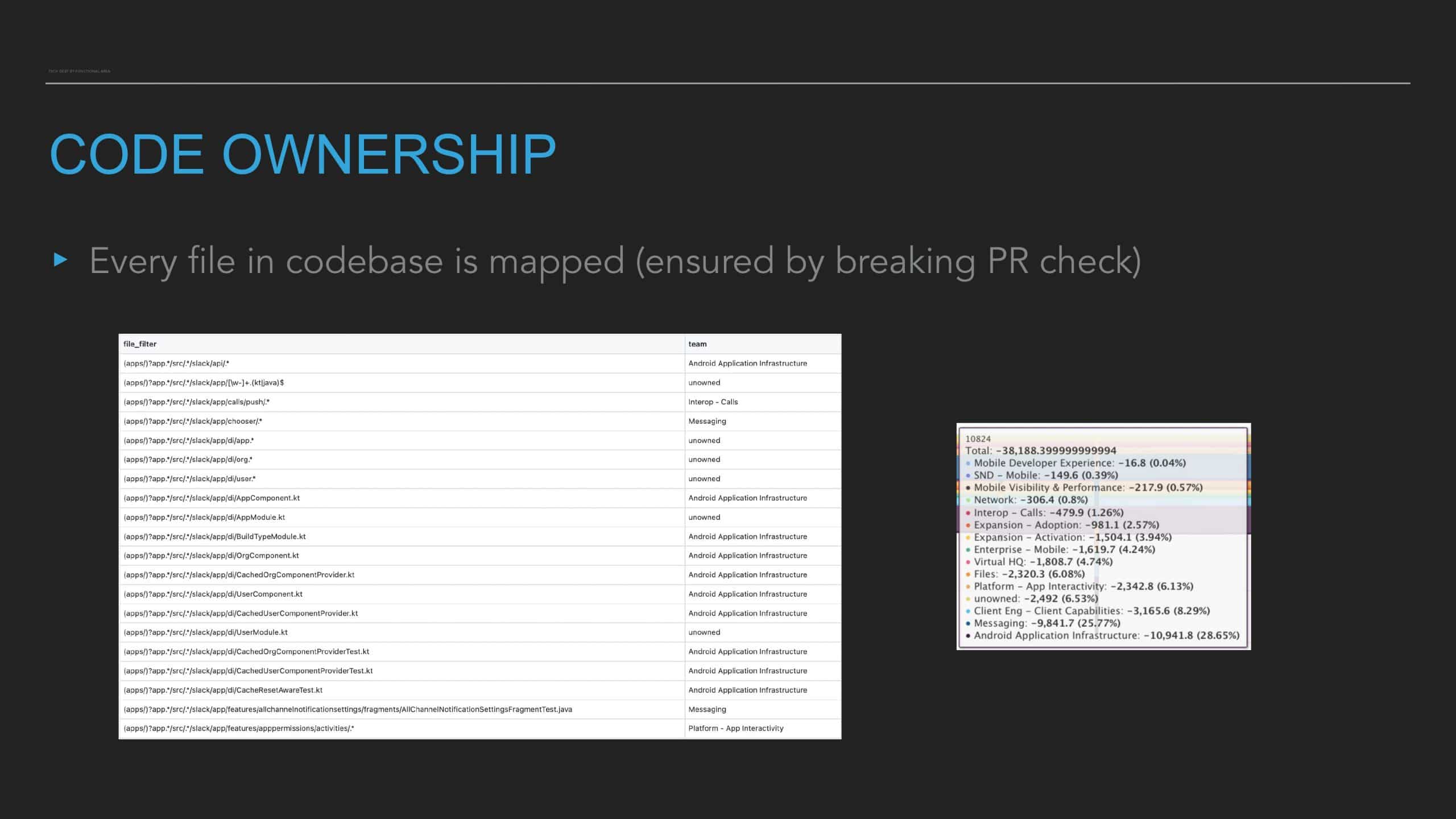
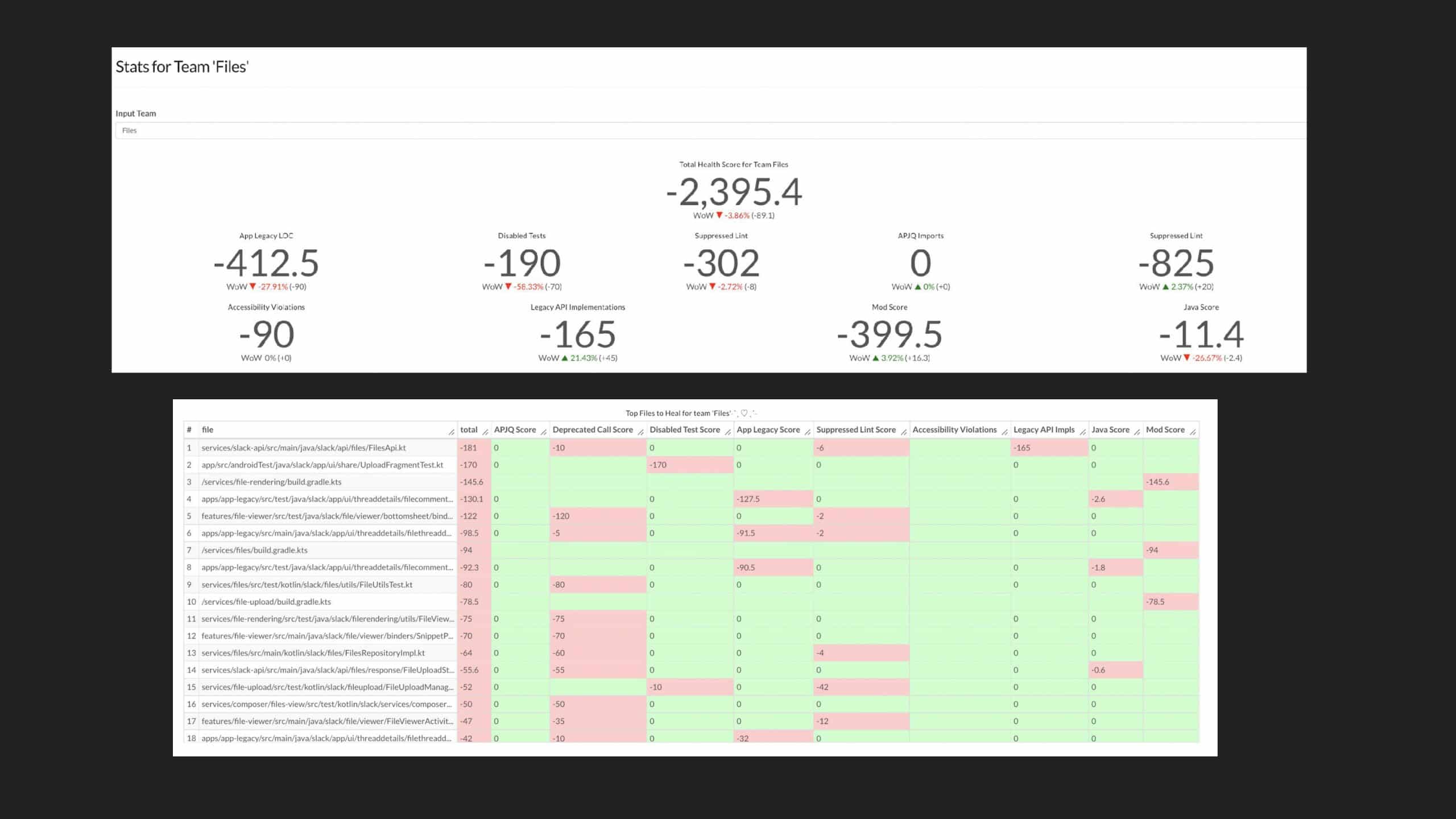
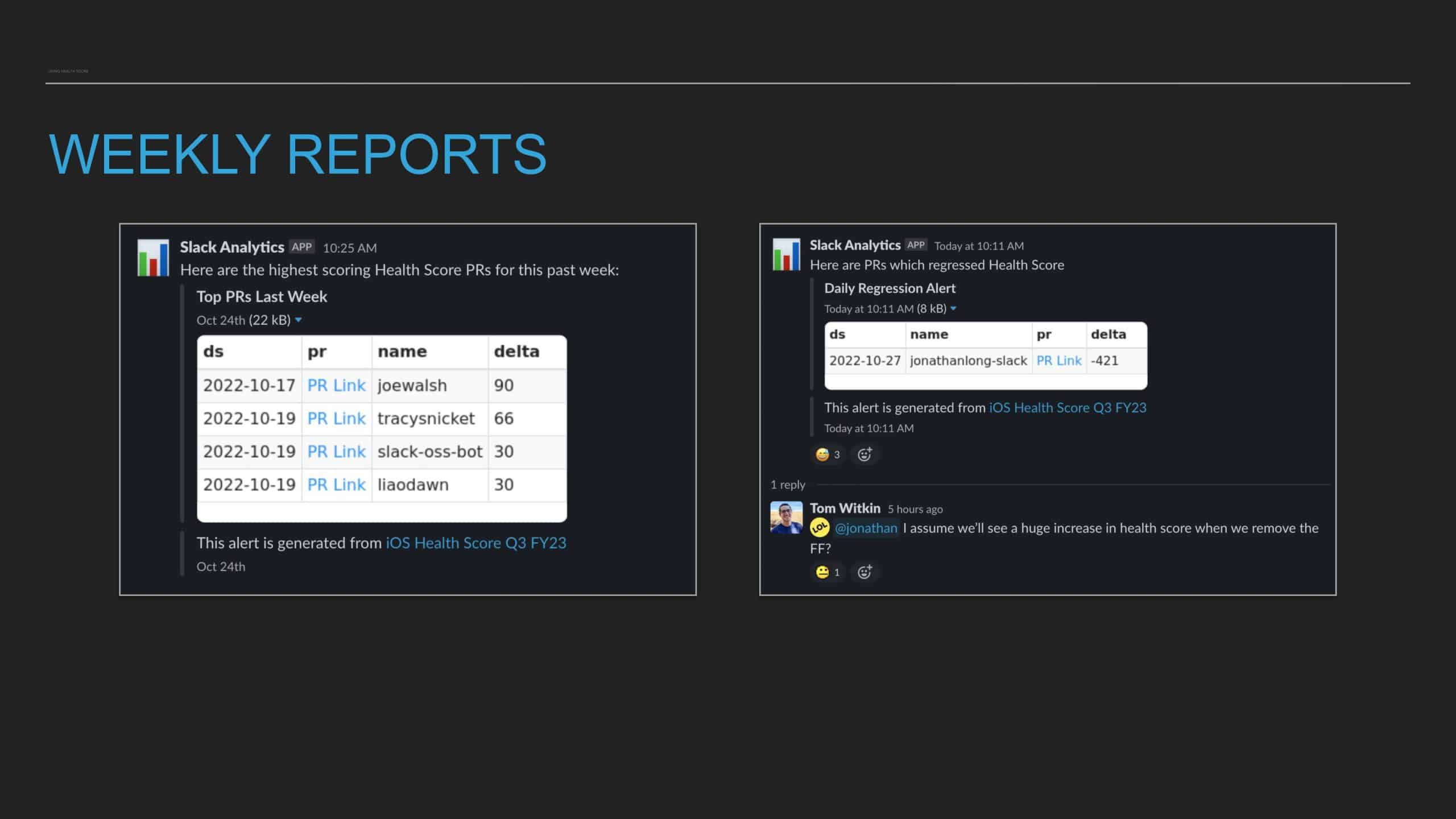
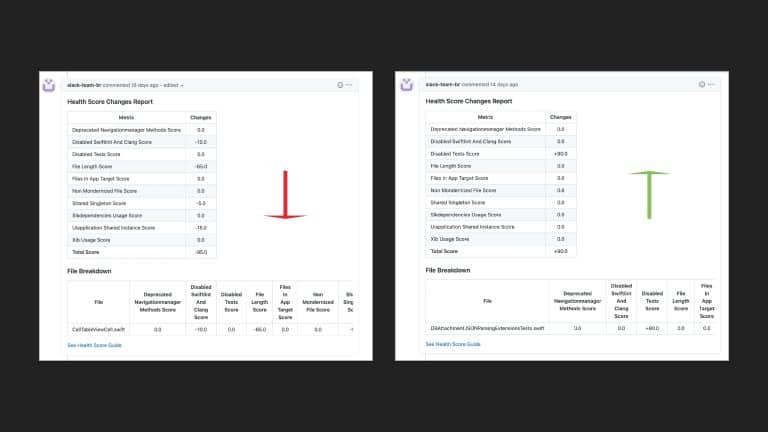
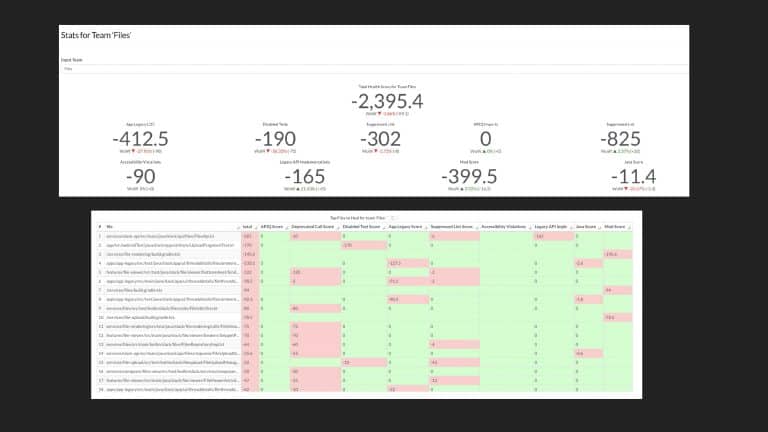
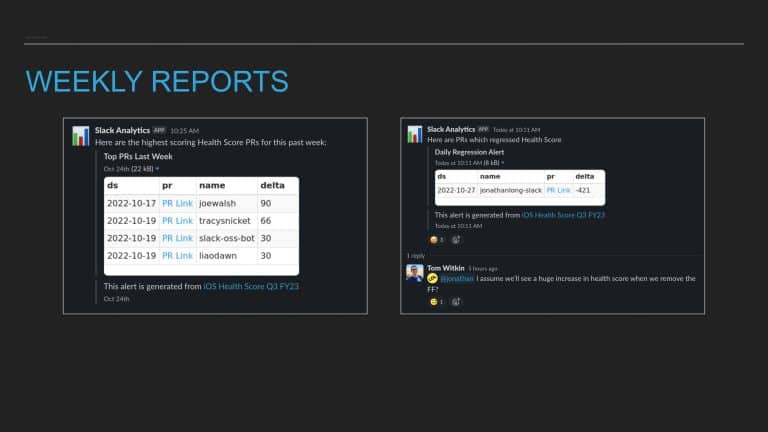
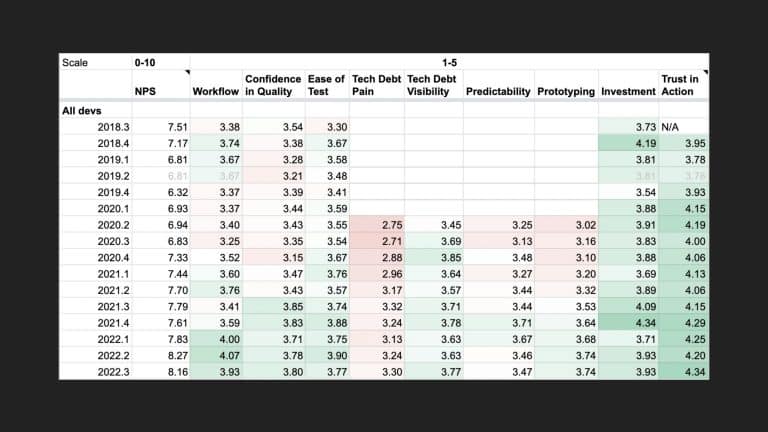
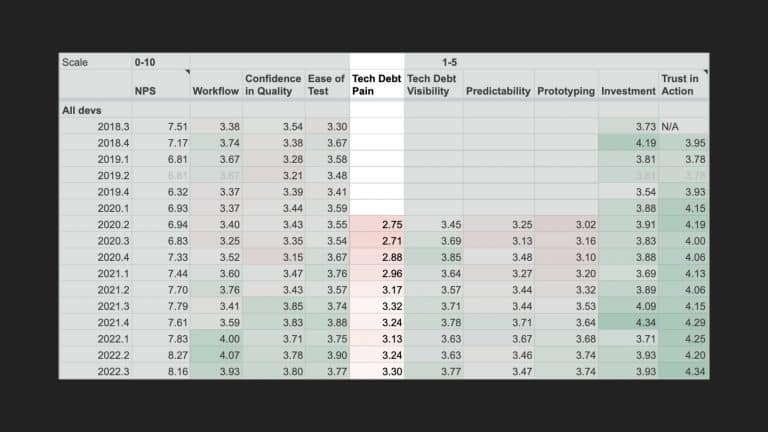
Following the trope of “you can’t improve what you don’t measure,” Slack employs a code health
score, which is an empirical measure that provides visibility into cumulative and team-based
technical debt to address these questions. But measurement alone isn’t enough. The quality and
reliability of the code (the feature) are important to integrate these measurements into the
day-to-day engineering culture of the team.
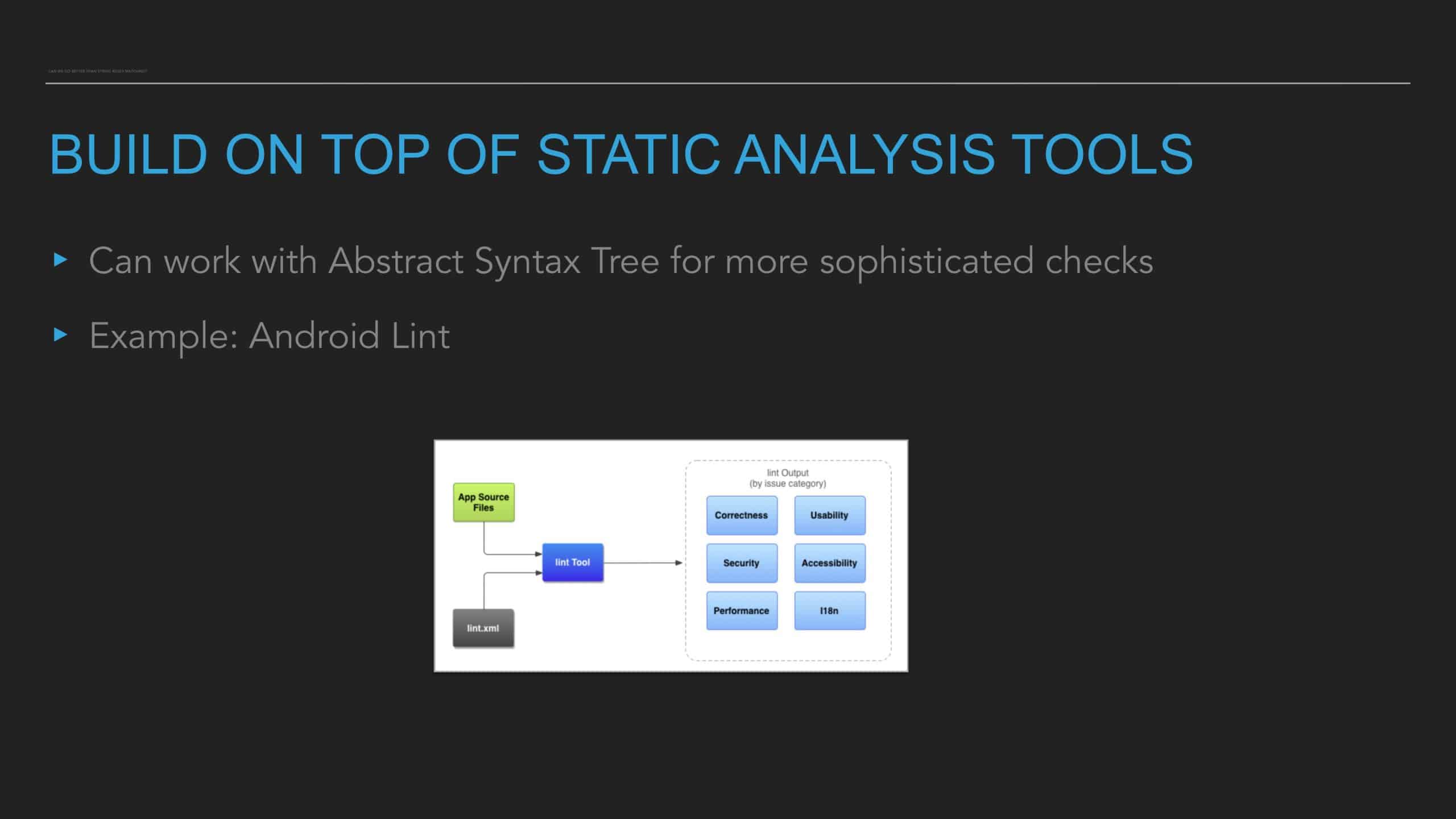
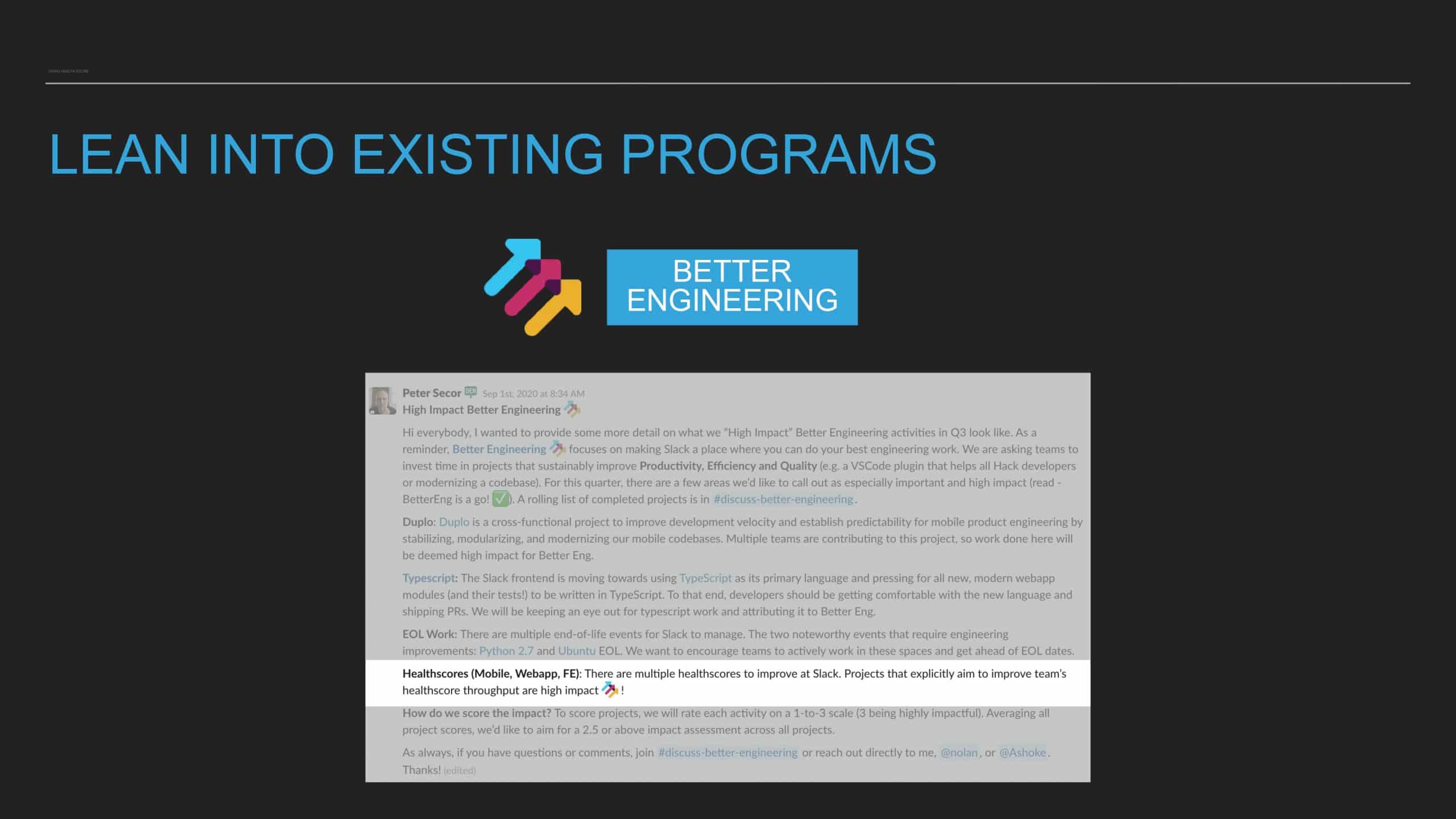
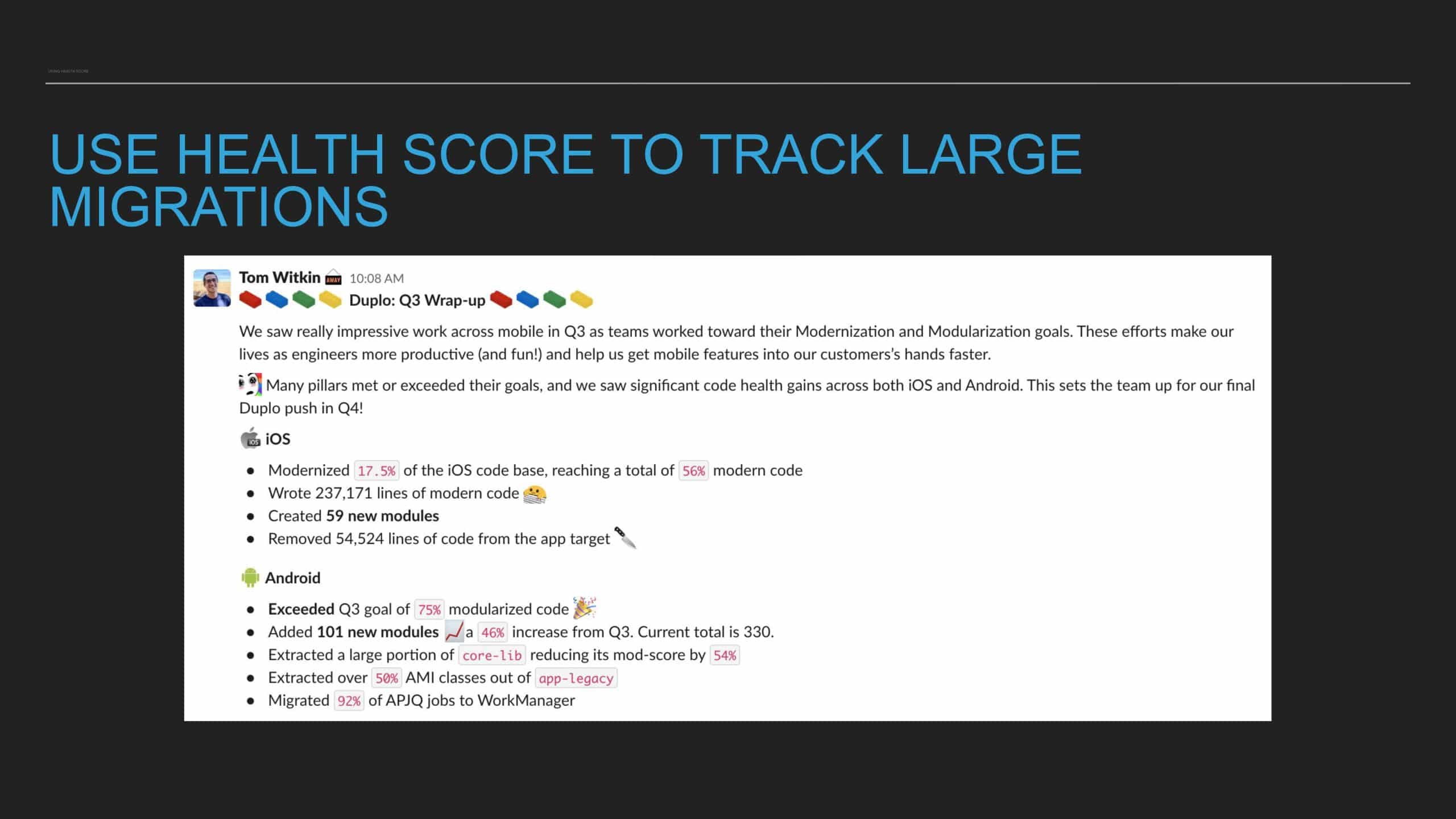
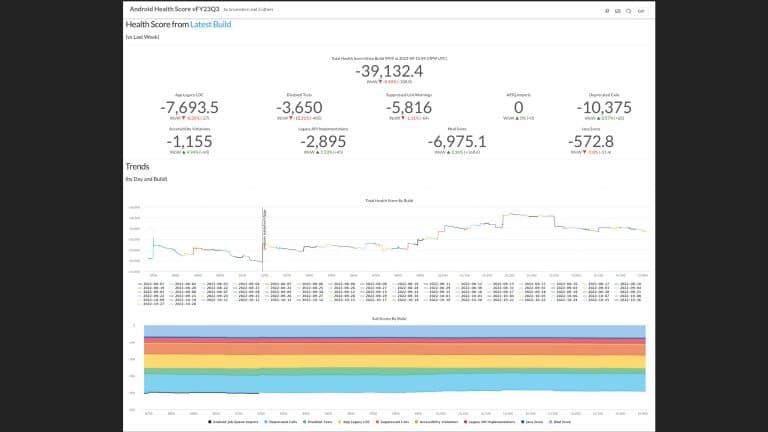
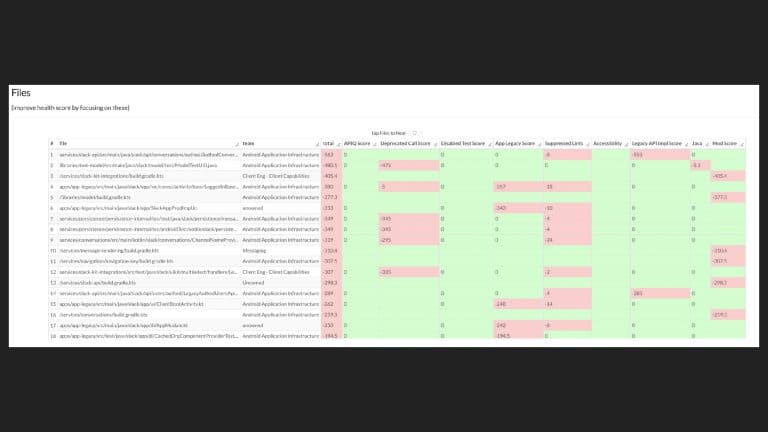
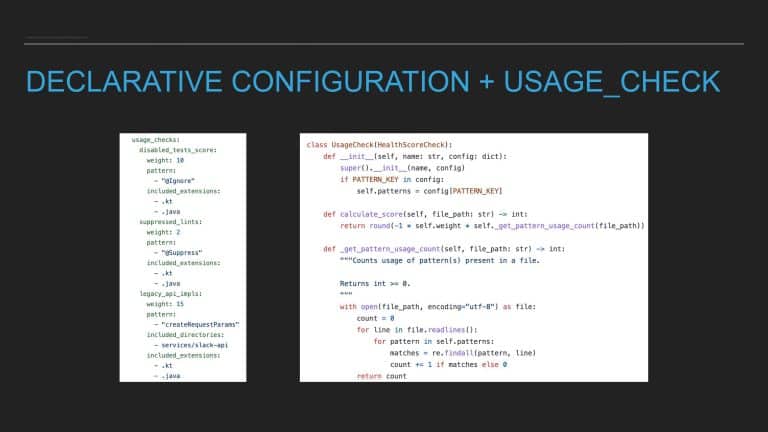
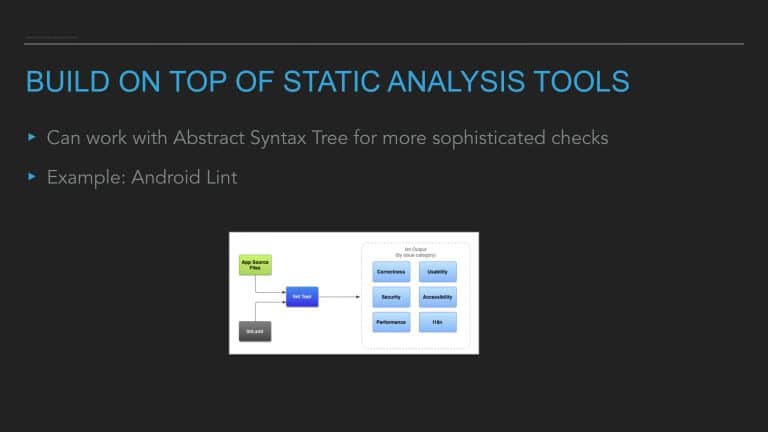
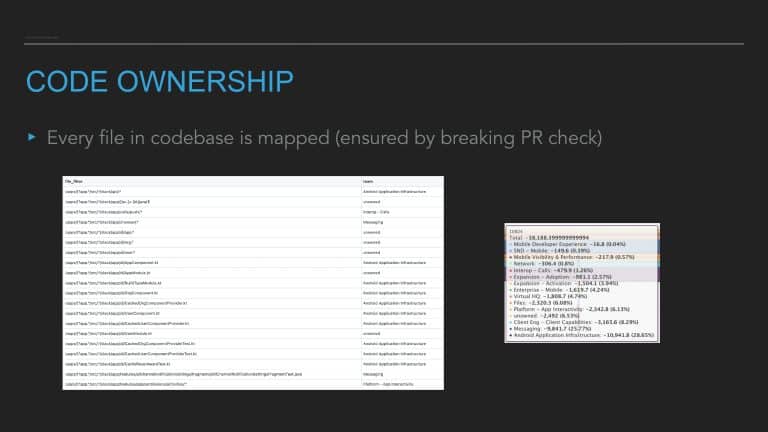
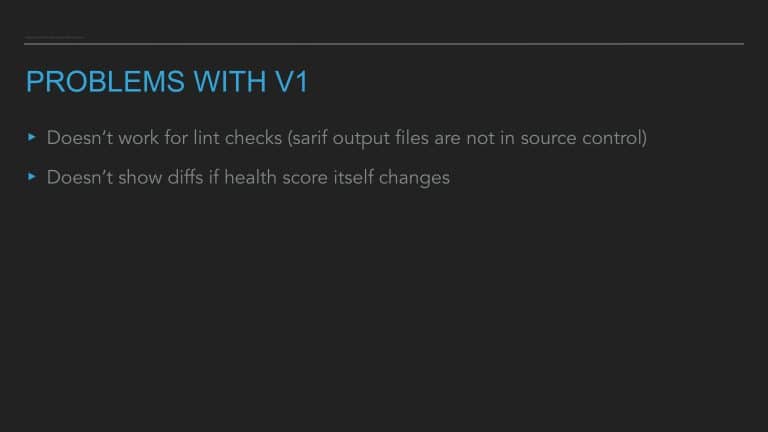
This talk provides the formula for building a code health score for any codebase, touches on the nuances of its implementation on Android/iOS, and shares lessons learned about integrating this tool into an engineering process.
This talk provides the formula for building a code health score for any codebase, touches on the nuances of its implementation on Android/iOS, and shares lessons learned about integrating this tool into an engineering process.
About Valera
Valera Zakharov leads the mobile developer experience team at Slack. Prior to Slack, he led the development of Espresso at Google and contributed to the infrastructure that runs hundreds of android tests per second. He is passionate about building (and presenting about!) infrastructure that makes the lives of developers more pleasant and productive.
Valera Zakharov leads the mobile developer experience team at Slack. Prior to Slack, he led the development of Espresso at Google and contributed to the infrastructure that runs hundreds of android tests per second. He is passionate about building (and presenting about!) infrastructure that makes the lives of developers more pleasant and productive.

Gradle Enterprise Solutions
for
Addressing Tech Debt
& Build
Quality
Generating a health score for your codebase provides a valuable addition to a comprehensive Developer Productivity Engineering practice. In combination with Gradle Enterprise’s Performance Acceleration, Performance Continuity, and Failure Analytics technologies, code health scores promote consistent, faster, and more reliable builds.
Generating a health score for your codebase provides a valuable addition to a comprehensive Developer Productivity Engineering practice. In combination with Gradle Enterprise’s Performance Acceleration, Performance Continuity, and Failure Analytics technologies, code health scores promote consistent, faster, and more reliable builds.
Slides