
What’s inside?
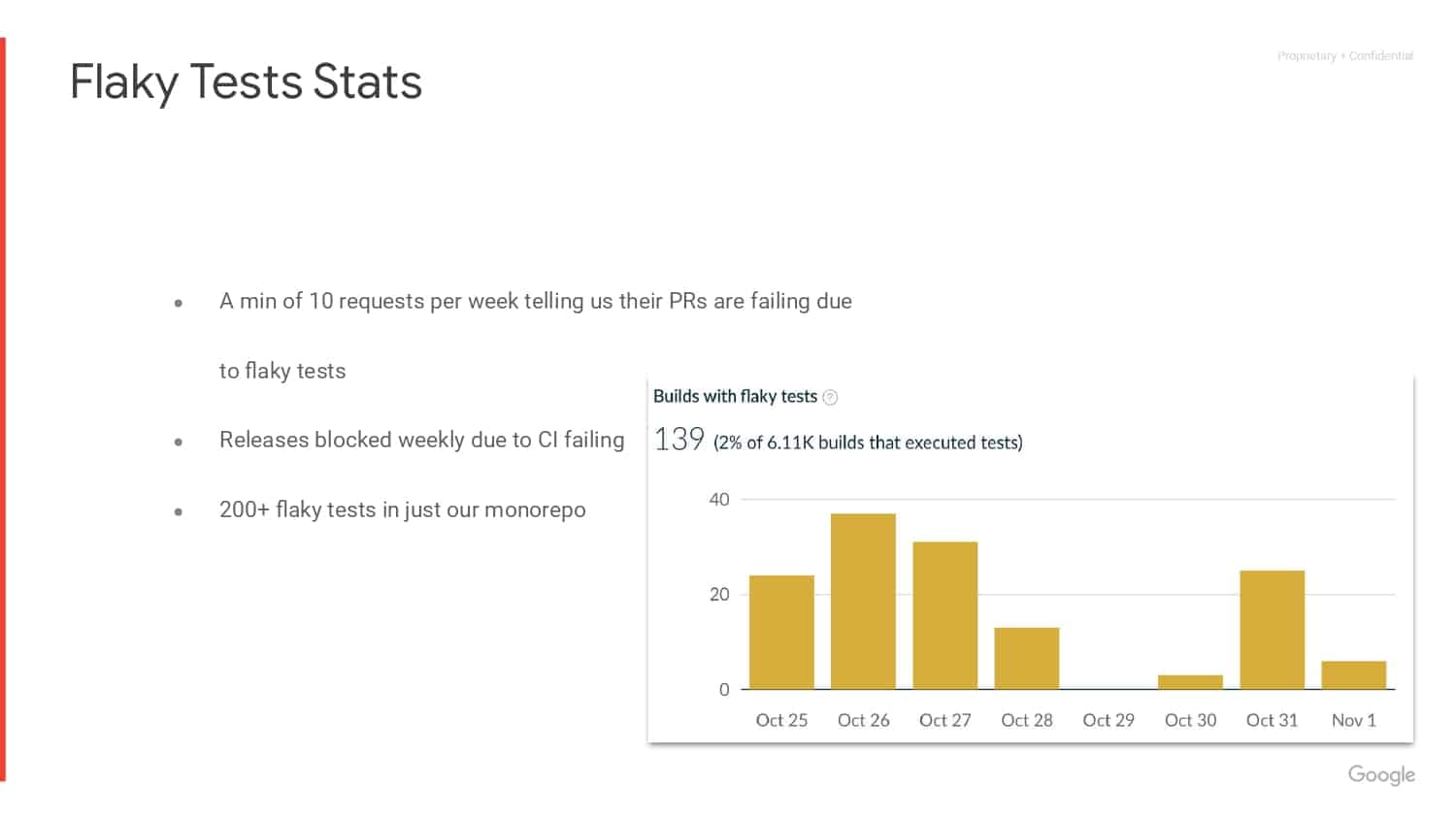
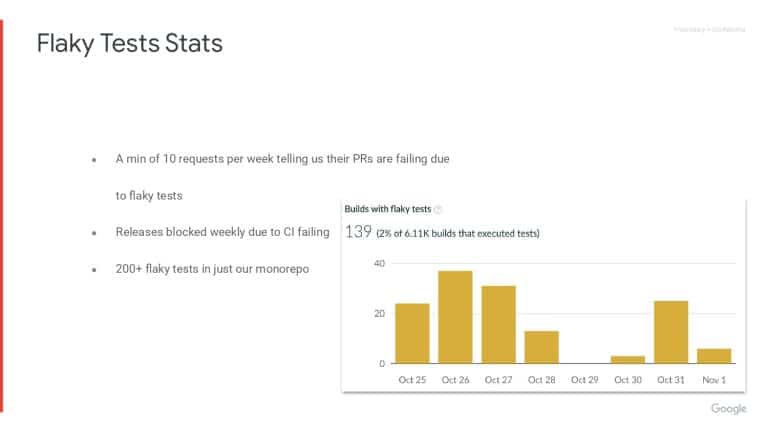
Simona Bateman discusses the signals she and her team observed by capturing test telemetry data which indicated that PR (Pull Request) builds were failing due to flaky tests. This also explained why their releases were being blocked.
Simona Bateman discusses the signals she and her team observed by capturing test telemetry data which indicated that PR (Pull Request) builds were failing due to flaky tests. This also explained why their releases were being blocked.
Summit Producer’s Highlight
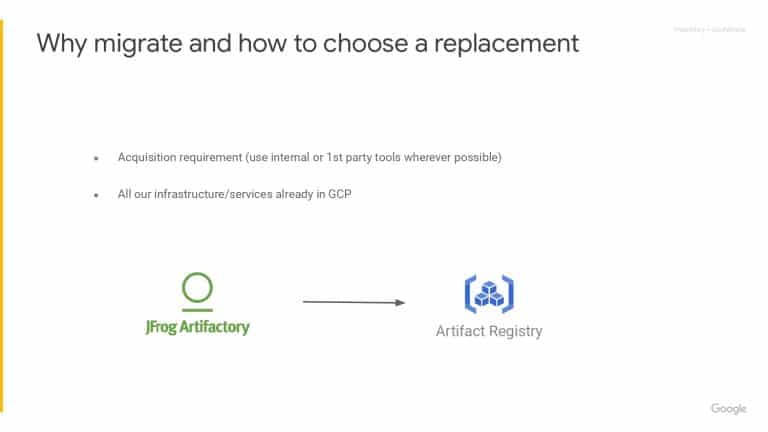
Google Fitbit’s developer productivity team shares their successful strategies for improving developer experience in the last year. Learn about Google’s best practices around Flaky Test management. Also, discover lessons learned from the migration from Artifactory to Google Clouds Artifact Registry.
Google Fitbit’s developer productivity team shares their successful strategies for improving developer experience in the last year. Learn about Google’s best practices around Flaky Test management. Also, discover lessons learned from the migration from Artifactory to Google Clouds Artifact Registry.
About Simona
Simona Bateman is a software engineer passionate about making developers’ lives easier by identifying pain points and building tools to alleviate them. She has worked in a variety of roles across startups and at larger companies like LinkedIn and Fitbit/Google, with a recent focus on Gradle and Jenkins performance. In her spare time, you’ll find her hiking and camping with her two young boys, training for Spartan races, video gaming, and reading as many books as she can.
Simona Bateman is a software engineer passionate about making developers’ lives easier by identifying pain points and building tools to alleviate them. She has worked in a variety of roles across startups and at larger companies like LinkedIn and Fitbit/Google, with a recent focus on Gradle and Jenkins performance. In her spare time, you’ll find her hiking and camping with her two young boys, training for Spartan races, video gaming, and reading as many books as she can.

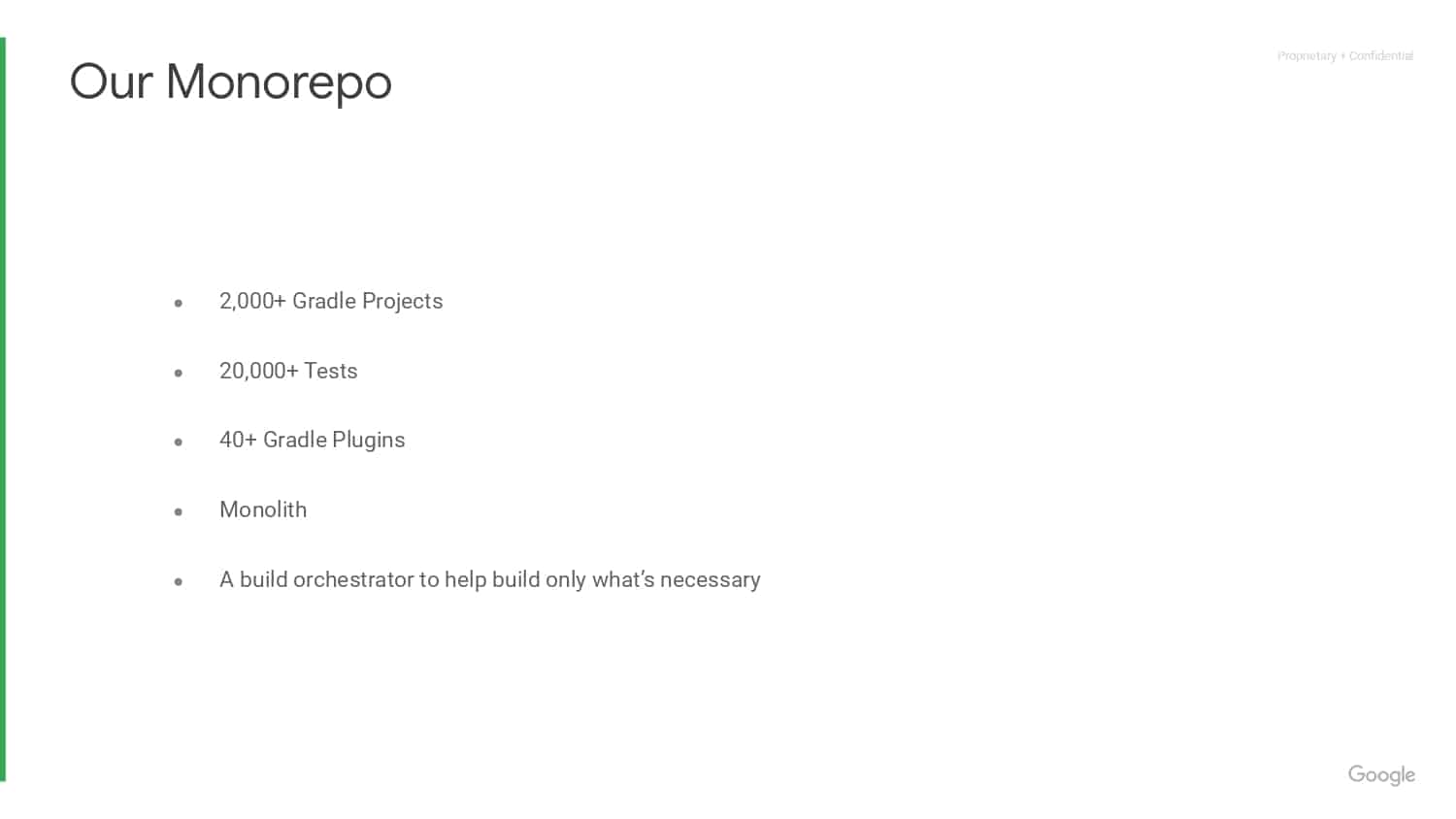
Gradle Enterprise Solutions
for Flaky Test Management
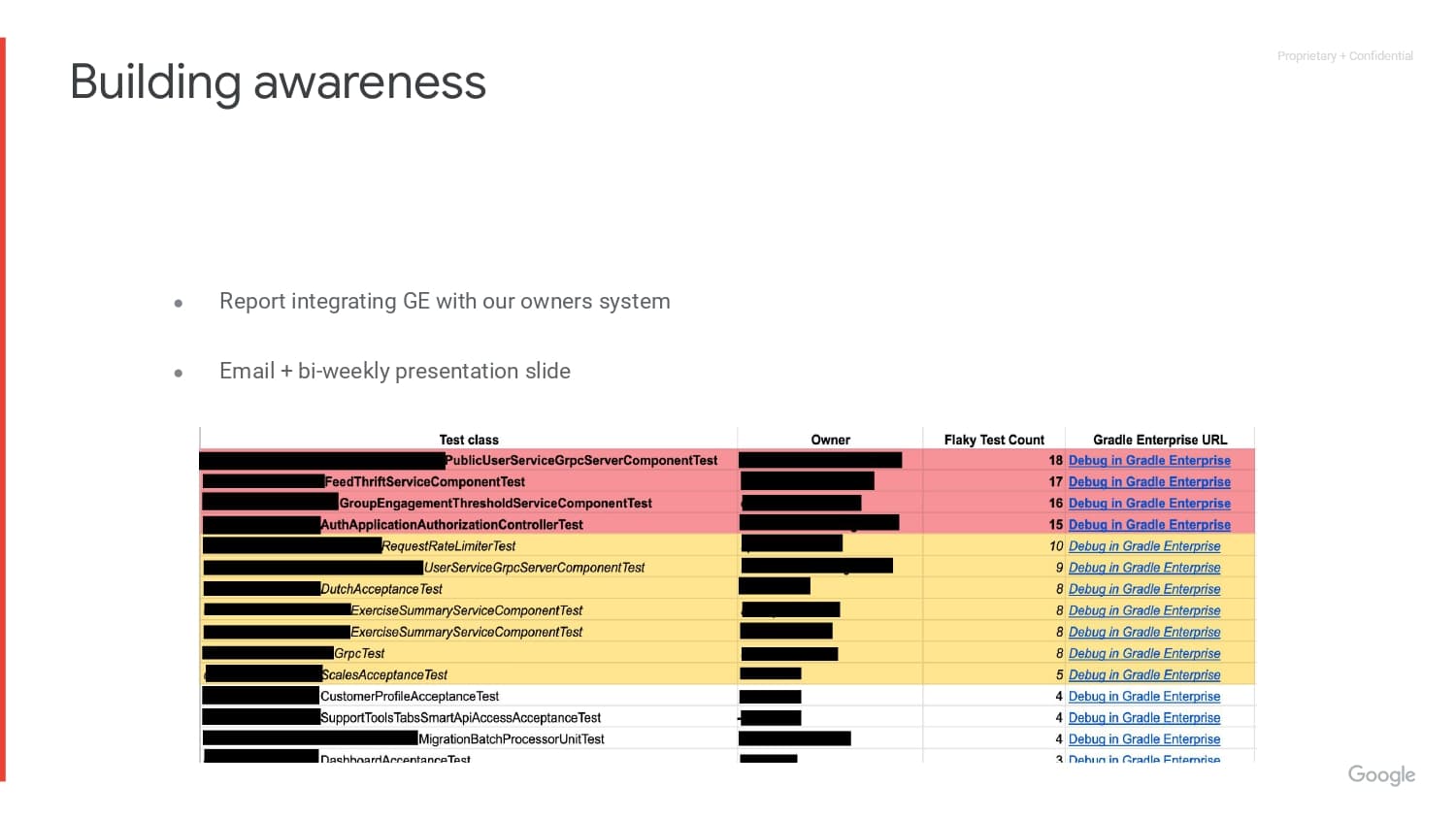
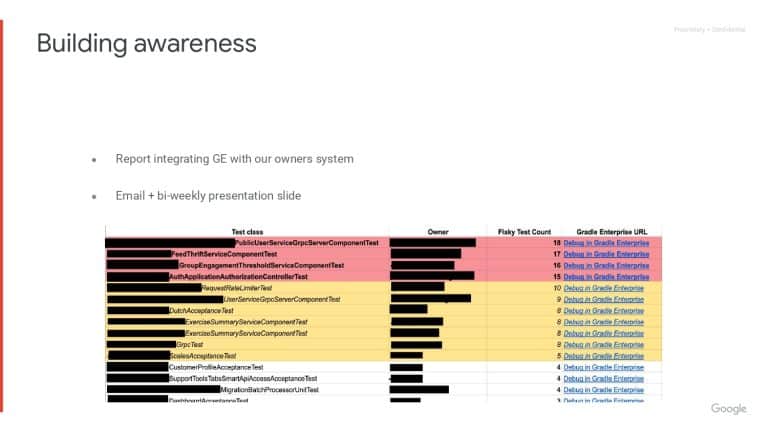
The management of non-deterministic test management is a multi-step process. Not only do flaky tests need to be discovered, but there must be practices in place to proactively deal with them once they’ve been detected. Gradle Enterprise’s Test Failure Analytics provides a comprehensive solution that helps detect, prioritize, and fix flaky tests.
The management of non-deterministic test management is a multi-step process. Not only do flaky tests need to be discovered, but there must be practices in place to proactively deal with them once they’ve been detected. Gradle Enterprise’s Test Failure Analytics provides a comprehensive solution that helps detect, prioritize, and fix flaky tests.
Slides








































Interested in Flaky Test Management?
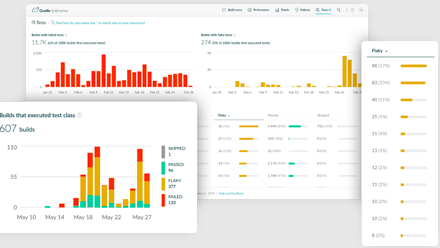
How the Gradle Build Tool core team manages flaky tests through
“flaky test days” prior to a major release
10-minute read
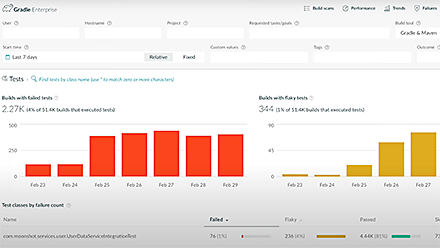
Improve Gradle & Maven flaky test management with test failure
analytics
14-minute watch

Check out the flaky test analysis chapter in the live DPE
workshop
2.5-hour training